 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Efficient Unsupervised Satellite Image-based Building Damage Detection
Dec 04, 2023Existing Building Damage Detection (BDD) methods always require labour-intensive pixel-level annotations of buildings and their conditions, hence largely limiting their applications. In this paper, we investigate a challenging yet practical scenario of BDD, Unsupervised Building Damage Detection (U-BDD), where only unlabelled pre- and post-disaster satellite image pairs are provided. As a pilot study, we have first proposed an advanced U-BDD baseline that leverages pre-trained vision-language foundation models (i.e., Grounding DINO, SAM and CLIP) to address the U-BDD task. However, the apparent domain gap between satellite and generic images causes low confidence in the foundation models used to identify buildings and their damages. In response, we further present a novel self-supervised framework, U-BDD++, which improves upon the U-BDD baseline by addressing domain-specific issues associated with satellite imagery. Furthermore, the new Building Proposal Generation (BPG) module and the CLIP-enabled noisy Building Proposal Selection (CLIP-BPS) module in U-BDD++ ensure high-quality self-training. Extensive experiments on the widely used building damage assessment benchmark demonstrate the effectiveness of the proposed method for unsupervised building damage detection. The presented annotation-free and foundation model-based paradigm ensures an efficient learning phase. This study opens a new direction for real-world BDD and sets a strong baseline for future research.
RoadAtlas: Intelligent Platform for Automated Road Defect Detection and Asset Management
Sep 09, 2021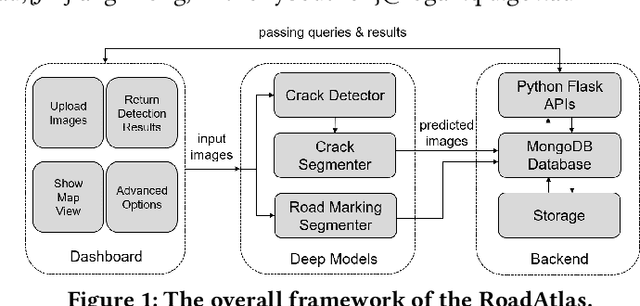

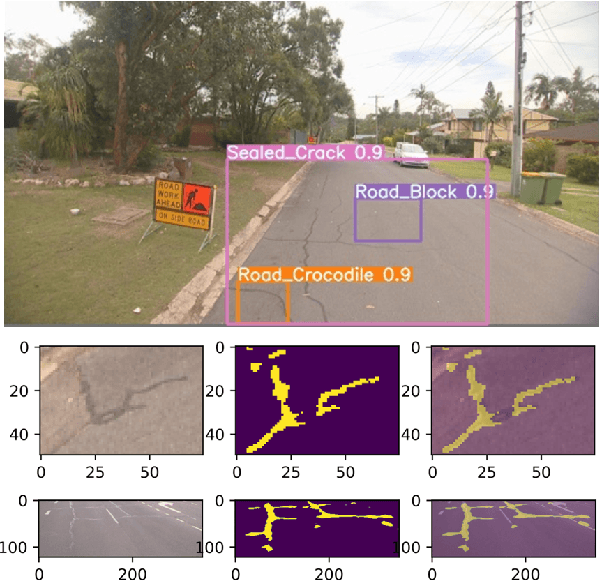
With the rapid development of intelligent detection algorithms based on deep learning, much progress has been made in automatic road defect recognition and road marking parsing. This can effectively address the issue of an expensive and time-consuming process for professional inspectors to review the street manually. Towards this goal, we present RoadAtlas, a novel end-to-end integrated system that can support 1) road defect detection, 2) road marking parsing, 3) a web-based dashboard for presenting and inputting data by users, and 4) a backend containing a well-structured database and developed APIs.
RRLFSOR: An Efficient Self-Supervised Learning Strategy of Graph Convolutional Networks
Aug 17, 2021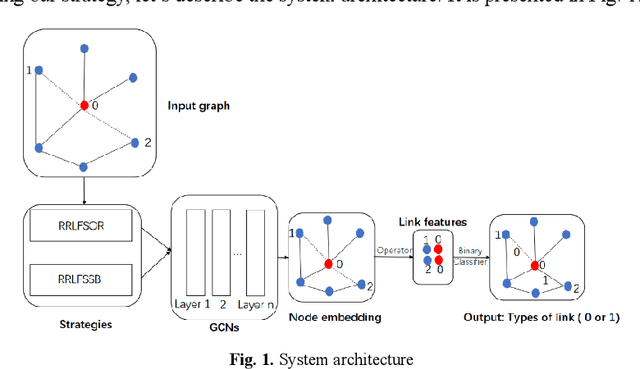
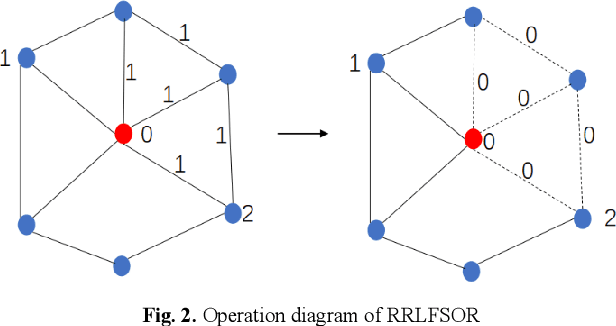
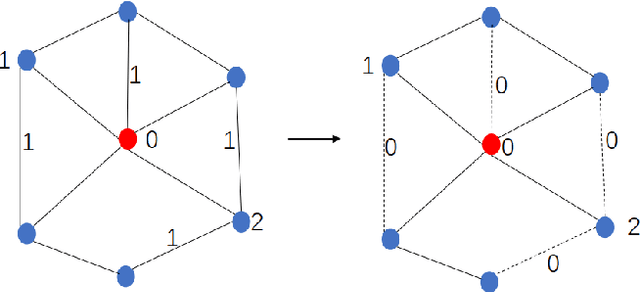

To further improve the performance and the self-learning ability of GCNs, in this paper, we propose an efficient self-supervised learning strategy of GCNs, named randomly removed links with a fixed step at one region (RRLFSOR). In addition, we also propose another self-supervised learning strategy of GCNs, named randomly removing links with a fixed step at some blocks (RRLFSSB), to solve the problem that adjacent nodes have no selected step. Experiments on transductive link prediction tasks show that our strategies outperform the baseline models consistently by up to 21.34% in terms of accuracy on three benchmark datasets.