 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeMerge: Codebook-Guided Model Merging for Robust Test-Time Adaptation in Autonomous Driving
May 22, 2025



Maintaining robust 3D perception under dynamic and unpredictable test-time conditions remains a critical challenge for autonomous driving systems. Existing test-time adaptation (TTA) methods often fail in high-variance tasks like 3D object detection due to unstable optimization and sharp minima. While recent model merging strategies based on linear mode connectivity (LMC) offer improved stability by interpolating between fine-tuned checkpoints, they are computationally expensive, requiring repeated checkpoint access and multiple forward passes. In this paper, we introduce CodeMerge, a lightweight and scalable model merging framework that bypasses these limitations by operating in a compact latent space. Instead of loading full models, CodeMerge represents each checkpoint with a low-dimensional fingerprint derived from the source model's penultimate features and constructs a key-value codebook. We compute merging coefficients using ridge leverage scores on these fingerprints, enabling efficient model composition without compromising adaptation quality. Our method achieves strong performance across challenging benchmarks, improving end-to-end 3D detection 14.9% NDS on nuScenes-C and LiDAR-based detection by over 7.6% mAP on nuScenes-to-KITTI, while benefiting downstream tasks such as online mapping, motion prediction and planning even without training. Code and pretrained models are released in the supplementary material.
MOS: Model Synergy for Test-Time Adaptation on LiDAR-Based 3D Object Detection
Jun 21, 2024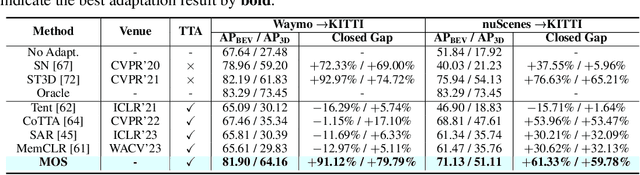


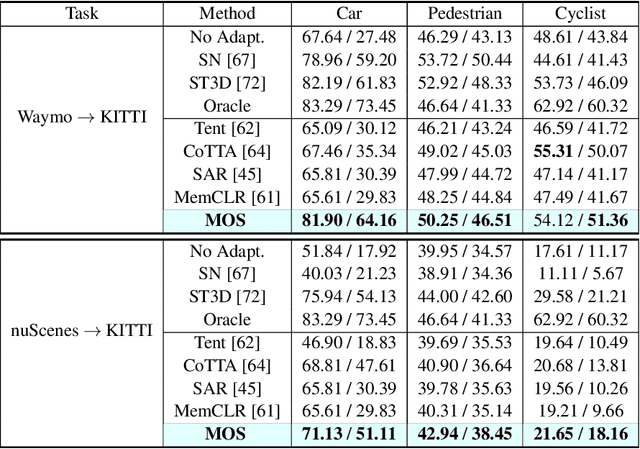
LiDAR-based 3D object detection is pivotal across many applications, yet the performance of such detection systems often degrades after deployment, especially when faced with unseen test point clouds originating from diverse locations or subjected to corruption. In this work, we introduce a new online adaptation framework for detectors named Model Synergy (MOS). Specifically, MOS dynamically assembles best-fit supermodels for each test batch from a bank of historical checkpoints, leveraging long-term knowledge to guide model updates without forgetting. The model assembly is directed by the proposed synergy weights (SW), employed for weighted averaging of the selected checkpoints to minimize redundancy in the composite supermodel. These weights are calculated by evaluating the similarity of predicted bounding boxes on test data and the feature independence among model pairs in the bank. To maintain an informative yet compact model bank, we pop out checkpoints with the lowest average SW scores and insert newly updated model weights. Our method was rigorously tested against prior test-time domain adaptation strategies on three datasets and under eight types of corruptions, demonstrating its superior adaptability to changing scenes and conditions. Remarkably, our approach achieved a 67.3% increase in performance in a complex "cross-corruption" scenario, which involves cross-dataset inconsistencies and real-world scene corruptions, providing a more realistic testbed of adaptation capabilities. The code is available at https://github.com/zhuoxiao-chen/MOS.
DiPEx: Dispersing Prompt Expansion for Class-Agnostic Object Detection
Jun 21, 2024



Class-agnostic object detection (OD) can be a cornerstone or a bottleneck for many downstream vision tasks. Despite considerable advancements in bottom-up and multi-object discovery methods that leverage basic visual cues to identify salient objects, consistently achieving a high recall rate remains difficult due to the diversity of object types and their contextual complexity. In this work, we investigate using vision-language models (VLMs) to enhance object detection via a self-supervised prompt learning strategy. Our initial findings indicate that manually crafted text queries often result in undetected objects, primarily because detection confidence diminishes when the query words exhibit semantic overlap. To address this, we propose a Dispersing Prompt Expansion (DiPEx) approach. DiPEx progressively learns to expand a set of distinct, non-overlapping hyperspherical prompts to enhance recall rates, thereby improving performance in downstream tasks such as out-of-distribution OD. Specifically, DiPEx initiates the process by self-training generic parent prompts and selecting the one with the highest semantic uncertainty for further expansion. The resulting child prompts are expected to inherit semantics from their parent prompts while capturing more fine-grained semantics. We apply dispersion losses to ensure high inter-class discrepancy among child prompts while preserving semantic consistency between parent-child prompt pairs. To prevent excessive growth of the prompt sets, we utilize the maximum angular coverage (MAC) of the semantic space as a criterion for early termination. We demonstrate the effectiveness of DiPEx through extensive class-agnostic OD and OOD-OD experiments on MS-COCO and LVIS, surpassing other prompting methods by up to 20.1% in AR and achieving a 21.3% AP improvement over SAM. The code is available at https://github.com/jason-lim26/DiPEx.
DPO: Dual-Perturbation Optimization for Test-time Adaptation in 3D Object Detection
Jun 19, 2024LiDAR-based 3D object detection has seen impressive advances in recent times. However, deploying trained 3D detectors in the real world often yields unsatisfactory performance when the distribution of the test data significantly deviates from the training data due to different weather conditions, object sizes, \textit{etc}. A key factor in this performance degradation is the diminished generalizability of pre-trained models, which creates a sharp loss landscape during training. Such sharpness, when encountered during testing, can precipitate significant performance declines, even with minor data variations. To address the aforementioned challenges, we propose \textbf{dual-perturbation optimization (DPO)} for \textbf{\underline{T}est-\underline{t}ime \underline{A}daptation in \underline{3}D \underline{O}bject \underline{D}etection (TTA-3OD)}. We minimize the sharpness to cultivate a flat loss landscape to ensure model resiliency to minor data variations, thereby enhancing the generalization of the adaptation process. To fully capture the inherent variability of the test point clouds, we further introduce adversarial perturbation to the input BEV features to better simulate the noisy test environment. As the dual perturbation strategy relies on trustworthy supervision signals, we utilize a reliable Hungarian matcher to filter out pseudo-labels sensitive to perturbations. Additionally, we introduce early Hungarian cutoff to avoid error accumulation from incorrect pseudo-labels by halting the adaptation process. Extensive experiments across three types of transfer tasks demonstrate that the proposed DPO significantly surpasses previous state-of-the-art approaches, specifically on Waymo $\rightarrow$ KITTI, outperforming the most competitive baseline by 57.72\% in $\text{AP}_\text{3D}$ and reaching 91\% of the fully supervised upper bound.
In Search of Lost Online Test-time Adaptation: A Survey
Oct 31, 2023



In this paper, we present a comprehensive survey on online test-time adaptation (OTTA), a paradigm focused on adapting machine learning models to novel data distributions upon batch arrival. Despite the proliferation of OTTA methods recently, the field is mired in issues like ambiguous settings, antiquated backbones, and inconsistent hyperparameter tuning, obfuscating the real challenges and making reproducibility elusive. For clarity and a rigorous comparison, we classify OTTA techniques into three primary categories and subject them to benchmarks using the potent Vision Transformer (ViT) backbone to discover genuinely effective strategies. Our benchmarks span not only conventional corrupted datasets such as CIFAR-10/100-C and ImageNet-C but also real-world shifts embodied in CIFAR-10.1 and CIFAR-10-Warehouse, encapsulating variations across search engines and synthesized data by diffusion models. To gauge efficiency in online scenarios, we introduce novel evaluation metrics, inclusive of FLOPs, shedding light on the trade-offs between adaptation accuracy and computational overhead. Our findings diverge from existing literature, indicating: (1) transformers exhibit heightened resilience to diverse domain shifts, (2) the efficacy of many OTTA methods hinges on ample batch sizes, and (3) stability in optimization and resistance to perturbations are critical during adaptation, especially when the batch size is 1. Motivated by these insights, we pointed out promising directions for future research. The source code will be made available.
Towards Open World Active Learning for 3D Object Detection
Oct 16, 2023



Significant strides have been made in closed world 3D object detection, testing systems in environments with known classes. However, the challenge arises in open world scenarios where new object classes appear. Existing efforts sequentially learn novel classes from streams of labeled data at a significant annotation cost, impeding efficient deployment to the wild. To seek effective solutions, we investigate a more practical yet challenging research task: Open World Active Learning for 3D Object Detection (OWAL-3D), aiming at selecting a small number of 3D boxes to annotate while maximizing detection performance on both known and unknown classes. The core difficulty centers on striking a balance between mining more unknown instances and minimizing the labeling expenses of point clouds. Empirically, our study finds the harmonious and inverse relationship between box quantities and their confidences can help alleviate the dilemma, avoiding the repeated selection of common known instances and focusing on uncertain objects that are potentially unknown. We unify both relational constraints into a simple and effective AL strategy namely OpenCRB, which guides to acquisition of informative point clouds with the least amount of boxes to label. Furthermore, we develop a comprehensive codebase for easy reproducing and future research, supporting 15 baseline methods (i.e., active learning, out-of-distribution detection and open world detection), 2 types of modern 3D detectors (i.e., one-stage SECOND and two-stage PV-RCNN) and 3 benchmark 3D datasets (i.e., KITTI, nuScenes and Waymo). Extensive experiments evidence that the proposed Open-CRB demonstrates superiority and flexibility in recognizing both novel and shared categories with very limited labeling costs, compared to state-of-the-art baselines.
KECOR: Kernel Coding Rate Maximization for Active 3D Object Detection
Jul 16, 2023Achieving a reliable LiDAR-based object detector in autonomous driving is paramount, but its success hinges on obtaining large amounts of precise 3D annotations. Active learning (AL) seeks to mitigate the annotation burden through algorithms that use fewer labels and can attain performance comparable to fully supervised learning. Although AL has shown promise, current approaches prioritize the selection of unlabeled point clouds with high uncertainty and/or diversity, leading to the selection of more instances for labeling and reduced computational efficiency. In this paper, we resort to a novel kernel coding rate maximization (KECOR) strategy which aims to identify the most informative point clouds to acquire labels through the lens of information theory. Greedy search is applied to seek desired point clouds that can maximize the minimal number of bits required to encode the latent features. To determine the uniqueness and informativeness of the selected samples from the model perspective, we construct a proxy network of the 3D detector head and compute the outer product of Jacobians from all proxy layers to form the empirical neural tangent kernel (NTK) matrix. To accommodate both one-stage (i.e., SECOND) and two-stage detectors (i.e., PVRCNN), we further incorporate the classification entropy maximization and well trade-off between detection performance and the total number of bounding boxes selected for annotation. Extensive experiments conducted on two 3D benchmarks and a 2D detection dataset evidence the superiority and versatility of the proposed approach. Our results show that approximately 44% box-level annotation costs and 26% computational time are reduced compared to the state-of-the-art AL method, without compromising detection performance.
Revisiting Domain-Adaptive 3D Object Detection by Reliable, Diverse and Class-balanced Pseudo-Labeling
Jul 16, 2023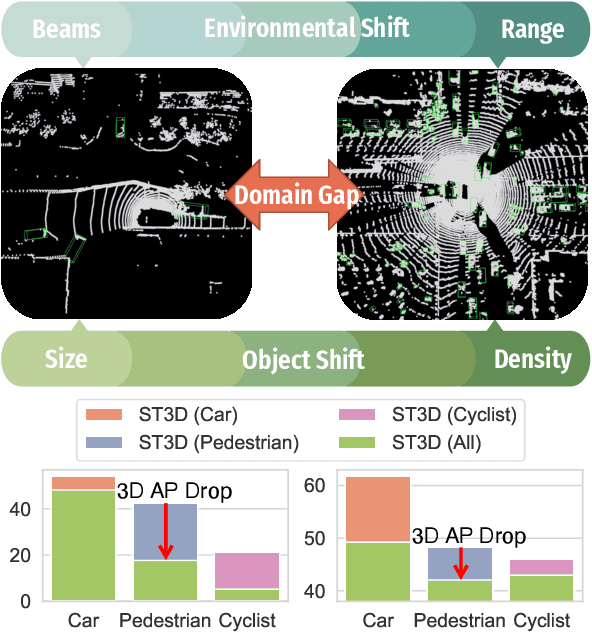



Unsupervised domain adaptation (DA) with the aid of pseudo labeling techniques has emerged as a crucial approach for domain-adaptive 3D object detection. While effective, existing DA methods suffer from a substantial drop in performance when applied to a multi-class training setting, due to the co-existence of low-quality pseudo labels and class imbalance issues. In this paper, we address this challenge by proposing a novel ReDB framework tailored for learning to detect all classes at once. Our approach produces Reliable, Diverse, and class-Balanced pseudo 3D boxes to iteratively guide the self-training on a distributionally different target domain. To alleviate disruptions caused by the environmental discrepancy (e.g., beam numbers), the proposed cross-domain examination (CDE) assesses the correctness of pseudo labels by copy-pasting target instances into a source environment and measuring the prediction consistency. To reduce computational overhead and mitigate the object shift (e.g., scales and point densities), we design an overlapped boxes counting (OBC) metric that allows to uniformly downsample pseudo-labeled objects across different geometric characteristics. To confront the issue of inter-class imbalance, we progressively augment the target point clouds with a class-balanced set of pseudo-labeled target instances and source objects, which boosts recognition accuracies on both frequently appearing and rare classes. Experimental results on three benchmark datasets using both voxel-based (i.e., SECOND) and point-based 3D detectors (i.e., PointRCNN) demonstrate that our proposed ReDB approach outperforms existing 3D domain adaptation methods by a large margin, improving 23.15% mAP on the nuScenes $\rightarrow$ KITTI task.
Exploring Active 3D Object Detection from a Generalization Perspective
Jan 23, 2023To alleviate the high annotation cost in LiDAR-based 3D object detection, active learning is a promising solution that learns to select only a small portion of unlabeled data to annotate, without compromising model performance. Our empirical study, however, suggests that mainstream uncertainty-based and diversity-based active learning policies are not effective when applied in the 3D detection task, as they fail to balance the trade-off between point cloud informativeness and box-level annotation costs. To overcome this limitation, we jointly investigate three novel criteria in our framework Crb for point cloud acquisition - label conciseness}, feature representativeness and geometric balance, which hierarchically filters out the point clouds of redundant 3D bounding box labels, latent features and geometric characteristics (e.g., point cloud density) from the unlabeled sample pool and greedily selects informative ones with fewer objects to annotate. Our theoretical analysis demonstrates that the proposed criteria align the marginal distributions of the selected subset and the prior distributions of the unseen test set, and minimizes the upper bound of the generalization error. To validate the effectiveness and applicability of \textsc{Crb}, we conduct extensive experiments on the two benchmark 3D object detection datasets of KITTI and Waymo and examine both one-stage (\textit{i.e.}, \textsc{Second}) and two-stage 3D detectors (i.e., Pv-rcnn). Experiments evidence that the proposed approach outperforms existing active learning strategies and achieves fully supervised performance requiring $1\%$ and $8\%$ annotations of bounding boxes and point clouds, respectively. Source code: https://github.com/Luoyadan/CRB-active-3Ddet.
Source-Free Progressive Graph Learning for Open-Set Domain Adaptation
Feb 13, 2022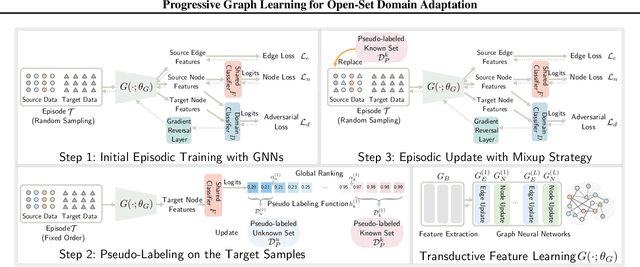
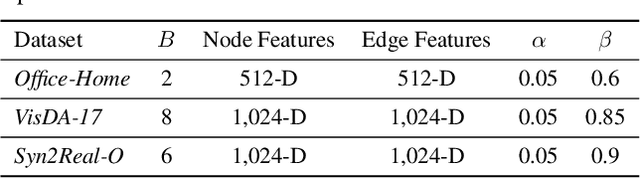
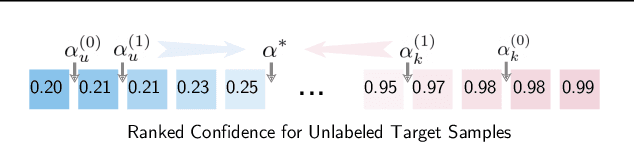
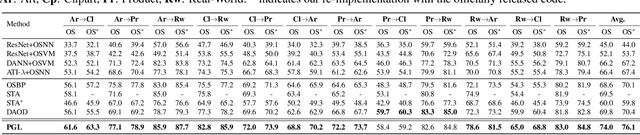
Open-set domain adaptation (OSDA) has gained considerable attention in many visual recognition tasks. However, most existing OSDA approaches are limited due to three main reasons, including: (1) the lack of essential theoretical analysis of generalization bound, (2) the reliance on the coexistence of source and target data during adaptation, and (3) failing to accurately estimate the uncertainty of model predictions. We propose a Progressive Graph Learning (PGL) framework that decomposes the target hypothesis space into the shared and unknown subspaces, and then progressively pseudo-labels the most confident known samples from the target domain for hypothesis adaptation. Moreover, we tackle a more realistic source-free open-set domain adaptation (SF-OSDA) setting that makes no assumption about the coexistence of source and target domains, and introduce a balanced pseudo-labeling (BP-L) strategy in a two-stage framework, namely SF-PGL. Different from PGL that applies a class-agnostic constant threshold for all target samples for pseudo-labeling, the SF-PGL model uniformly selects the most confident target instances from each category at a fixed ratio. The confidence thresholds in each class are regarded as the 'uncertainty' of learning the semantic information, which are then used to weigh the classification loss in the adaptation step. We conducted unsupervised and semi-supervised OSDA and SF-OSDA experiments on the benchmark image classification and action recognition datasets. Additionally, we find that balanced pseudo-labeling plays a significant role in improving calibration, which makes the trained model less prone to over-confident or under-confident predictions on the target data. Source code is available at https://github.com/Luoyadan/SF-PGL.