 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
CodeMerge: Codebook-Guided Model Merging for Robust Test-Time Adaptation in Autonomous Driving
May 22, 2025



Maintaining robust 3D perception under dynamic and unpredictable test-time conditions remains a critical challenge for autonomous driving systems. Existing test-time adaptation (TTA) methods often fail in high-variance tasks like 3D object detection due to unstable optimization and sharp minima. While recent model merging strategies based on linear mode connectivity (LMC) offer improved stability by interpolating between fine-tuned checkpoints, they are computationally expensive, requiring repeated checkpoint access and multiple forward passes. In this paper, we introduce CodeMerge, a lightweight and scalable model merging framework that bypasses these limitations by operating in a compact latent space. Instead of loading full models, CodeMerge represents each checkpoint with a low-dimensional fingerprint derived from the source model's penultimate features and constructs a key-value codebook. We compute merging coefficients using ridge leverage scores on these fingerprints, enabling efficient model composition without compromising adaptation quality. Our method achieves strong performance across challenging benchmarks, improving end-to-end 3D detection 14.9% NDS on nuScenes-C and LiDAR-based detection by over 7.6% mAP on nuScenes-to-KITTI, while benefiting downstream tasks such as online mapping, motion prediction and planning even without training. Code and pretrained models are released in the supplementary material.
TT-GaussOcc: Test-Time Compute for Self-Supervised Occupancy Prediction via Spatio-Temporal Gaussian Splatting
Mar 11, 2025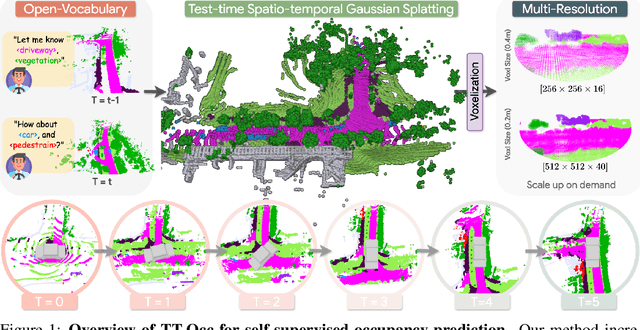


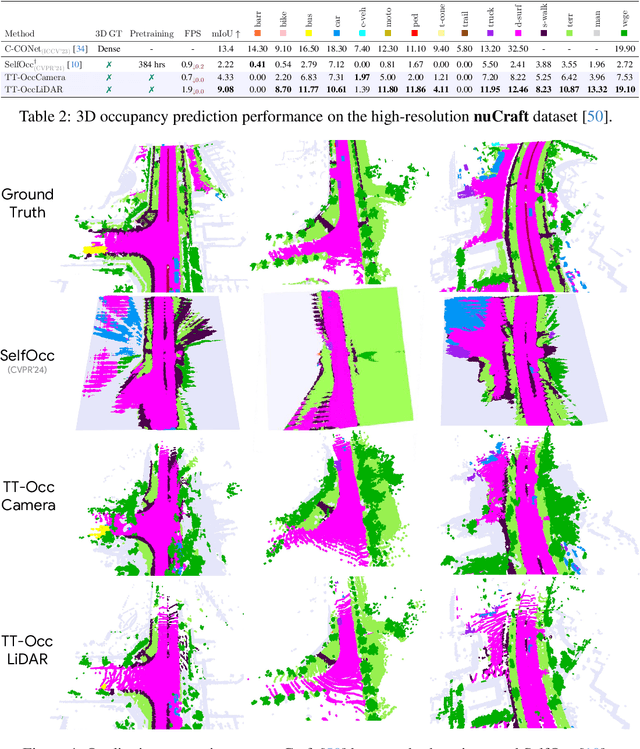
Self-supervised 3D occupancy prediction offers a promising solution for understanding complex driving scenes without requiring costly 3D annotations. However, training dense voxel decoders to capture fine-grained geometry and semantics can demand hundreds of GPU hours, and such models often fail to adapt to varying voxel resolutions or new classes without extensive retraining. To overcome these limitations, we propose a practical and flexible test-time occupancy prediction framework termed TT-GaussOcc. Our approach incrementally optimizes time-aware 3D Gaussians instantiated from raw sensor streams at runtime, enabling voxelization at arbitrary user-specified resolution. Specifically, TT-GaussOcc operates in a "lift-move-voxel" symphony: we first "lift" surrounding-view semantics obtained from 2D vision foundation models (VLMs) to instantiate Gaussians at non-empty 3D space; Next, we "move" dynamic Gaussians from previous frames along estimated Gaussian scene flow to complete appearance and eliminate trailing artifacts of fast-moving objects, while accumulating static Gaussians to enforce temporal consistency; Finally, we mitigate inherent noises in semantic predictions and scene flow vectors by periodically smoothing neighboring Gaussians during optimization, using proposed trilateral RBF kernels that jointly consider color, semantic, and spatial affinities. The historical static and current dynamic Gaussians are then combined and voxelized to generate occupancy prediction. Extensive experiments on Occ3D and nuCraft with varying voxel resolutions demonstrate that TT-GaussOcc surpasses self-supervised baselines by 46% on mIoU without any offline training, and supports finer voxel resolutions at 2.6 FPS inference speed.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024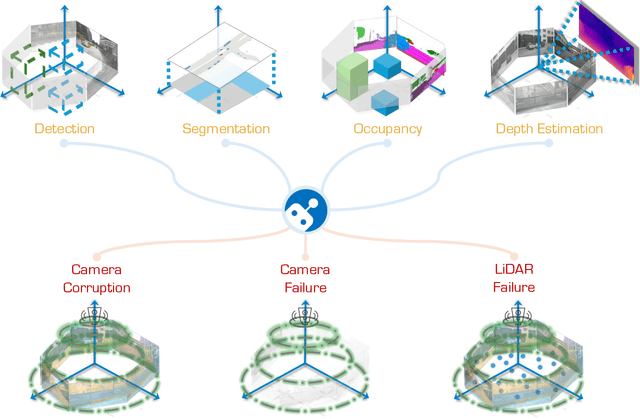


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
Cross-modal and Cross-domain Knowledge Transfer for Label-free 3D Segmentation
Sep 19, 2023



Current state-of-the-art point cloud-based perception methods usually rely on large-scale labeled data, which requires expensive manual annotations. A natural option is to explore the unsupervised methodology for 3D perception tasks. However, such methods often face substantial performance-drop difficulties. Fortunately, we found that there exist amounts of image-based datasets and an alternative can be proposed, i.e., transferring the knowledge in the 2D images to 3D point clouds. Specifically, we propose a novel approach for the challenging cross-modal and cross-domain adaptation task by fully exploring the relationship between images and point clouds and designing effective feature alignment strategies. Without any 3D labels, our method achieves state-of-the-art performance for 3D point cloud semantic segmentation on SemanticKITTI by using the knowledge of KITTI360 and GTA5, compared to existing unsupervised and weakly-supervised baselines.
* 12 pages,4 figures,accepted
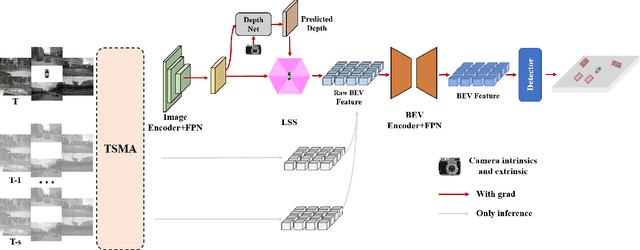
One Training for Multiple Deployments: Polar-based Adaptive BEV Perception for Autonomous Driving
Apr 02, 2023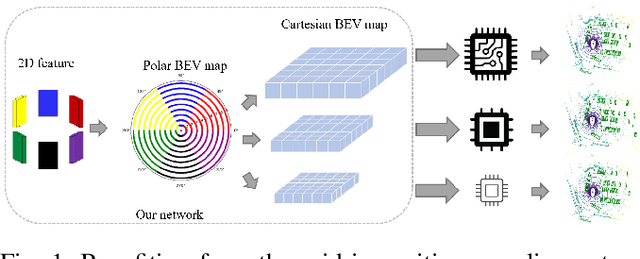
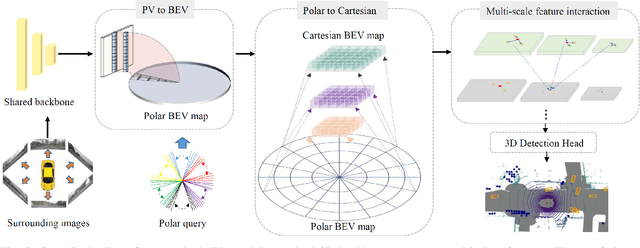
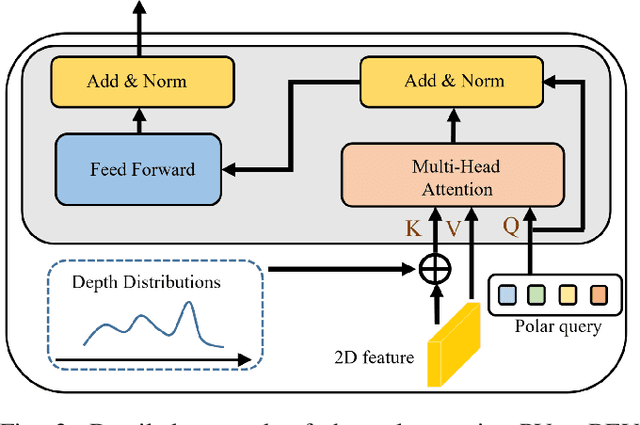
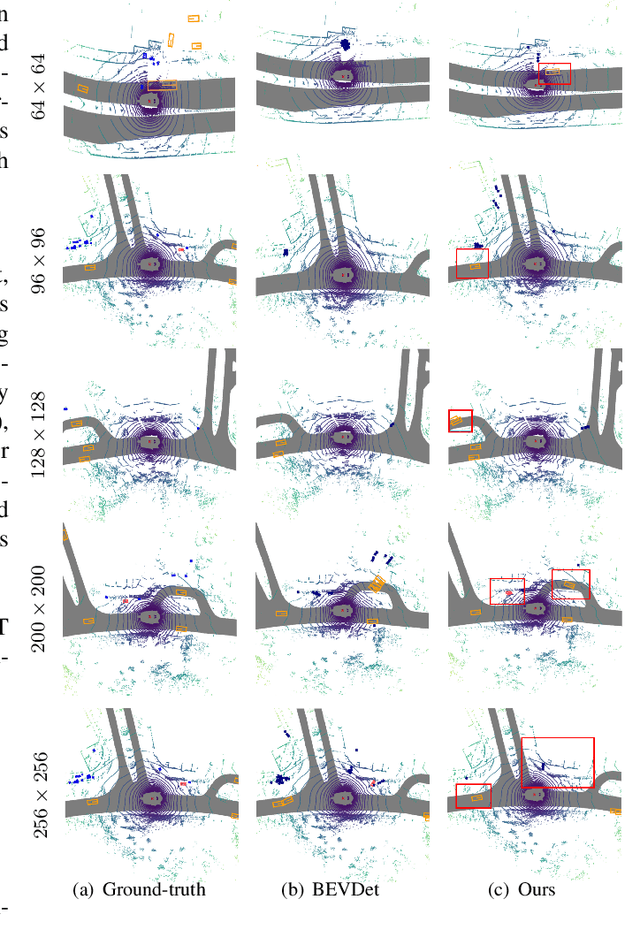
Current on-board chips usually have different computing power, which means multiple training processes are needed for adapting the same learning-based algorithm to different chips, costing huge computing resources. The situation becomes even worse for 3D perception methods with large models. Previous vision-centric 3D perception approaches are trained with regular grid-represented feature maps of fixed resolutions, which is not applicable to adapt to other grid scales, limiting wider deployment. In this paper, we leverage the Polar representation when constructing the BEV feature map from images in order to achieve the goal of training once for multiple deployments. Specifically, the feature along rays in Polar space can be easily adaptively sampled and projected to the feature in Cartesian space with arbitrary resolutions. To further improve the adaptation capability, we make multi-scale contextual information interact with each other to enhance the feature representation. Experiments on a large-scale autonomous driving dataset show that our method outperforms others as for the good property of one training for multiple deployments.
Vision-Centric BEV Perception: A Survey
Aug 04, 2022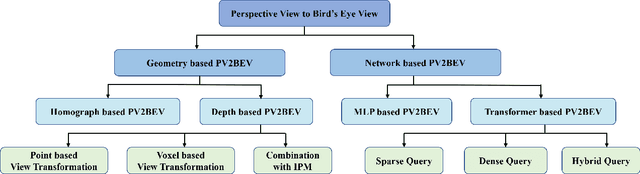

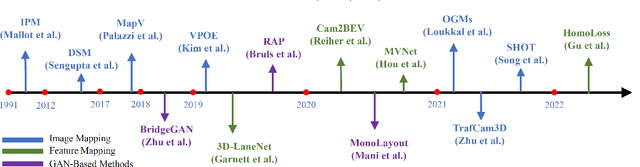
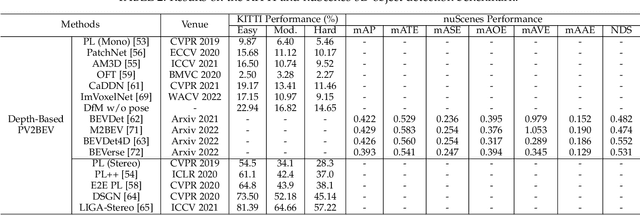
Vision-centric BEV perception has recently received increased attention from both industry and academia due to its inherent merits, including presenting a natural representation of the world and being fusion-friendly. With the rapid development of deep learning, numerous methods have been proposed to address the vision-centric BEV perception. However, there is no recent survey for this novel and growing research field. To stimulate its future research, this paper presents a comprehensive survey of recent progress of vision-centric BEV perception and its extensions. It collects and organizes the recent knowledge, and gives a systematic review and summary of commonly used algorithms. It also provides in-depth analyses and comparative results on several BEV perception tasks, facilitating the comparisons of future works and inspiring future research directions. Moreover, empirical implementation details are also discussed and shown to benefit the development of related algorithms.