 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
HexPlane Representation for 3D Semantic Scene Understanding
Mar 07, 2025



In this paper, we introduce the HexPlane representation for 3D semantic scene understanding. Specifically, we first design the View Projection Module (VPM) to project the 3D point cloud into six planes to maximally retain the original spatial information. Features of six planes are extracted by the 2D encoder and sent to the HexPlane Association Module (HAM) to adaptively fuse the most informative information for each point. The fused point features are further fed to the task head to yield the ultimate predictions. Compared to the popular point and voxel representation, the HexPlane representation is efficient and can utilize highly optimized 2D operations to process sparse and unordered 3D point clouds. It can also leverage off-the-shelf 2D models, network weights, and training recipes to achieve accurate scene understanding in 3D space. On ScanNet and SemanticKITTI benchmarks, our algorithm, dubbed HexNet3D, achieves competitive performance with previous algorithms. In particular, on the ScanNet 3D segmentation task, our method obtains 77.0 mIoU on the validation set, surpassing Point Transformer V2 by 1.6 mIoU. We also observe encouraging results in indoor 3D detection tasks. Note that our method can be seamlessly integrated into existing voxel-based, point-based, and range-based approaches and brings considerable gains without bells and whistles. The codes will be available upon publication.
OccMamba: Semantic Occupancy Prediction with State Space Models
Aug 19, 2024



Training deep learning models for semantic occupancy prediction is challenging due to factors such as a large number of occupancy cells, severe occlusion, limited visual cues, complicated driving scenarios, etc. Recent methods often adopt transformer-based architectures given their strong capability in learning input-conditioned weights and long-range relationships. However, transformer-based networks are notorious for their quadratic computation complexity, seriously undermining their efficacy and deployment in semantic occupancy prediction. Inspired by the global modeling and linear computation complexity of the Mamba architecture, we present the first Mamba-based network for semantic occupancy prediction, termed OccMamba. However, directly applying the Mamba architecture to the occupancy prediction task yields unsatisfactory performance due to the inherent domain gap between the linguistic and 3D domains. To relieve this problem, we present a simple yet effective 3D-to-1D reordering operation, i.e., height-prioritized 2D Hilbert expansion. It can maximally retain the spatial structure of point clouds as well as facilitate the processing of Mamba blocks. Our OccMamba achieves state-of-the-art performance on three prevalent occupancy prediction benchmarks, including OpenOccupancy, SemanticKITTI and SemanticPOSS. Notably, on OpenOccupancy, our OccMamba outperforms the previous state-of-the-art Co-Occ by 3.1% IoU and 3.2% mIoU, respectively. Codes will be released upon publication.
TASeg: Temporal Aggregation Network for LiDAR Semantic Segmentation
Jul 13, 2024



Training deep models for LiDAR semantic segmentation is challenging due to the inherent sparsity of point clouds. Utilizing temporal data is a natural remedy against the sparsity problem as it makes the input signal denser. However, previous multi-frame fusion algorithms fall short in utilizing sufficient temporal information due to the memory constraint, and they also ignore the informative temporal images. To fully exploit rich information hidden in long-term temporal point clouds and images, we present the Temporal Aggregation Network, termed TASeg. Specifically, we propose a Temporal LiDAR Aggregation and Distillation (TLAD) algorithm, which leverages historical priors to assign different aggregation steps for different classes. It can largely reduce memory and time overhead while achieving higher accuracy. Besides, TLAD trains a teacher injected with gt priors to distill the model, further boosting the performance. To make full use of temporal images, we design a Temporal Image Aggregation and Fusion (TIAF) module, which can greatly expand the camera FOV and enhance the present features. Temporal LiDAR points in the camera FOV are used as mediums to transform temporal image features to the present coordinate for temporal multi-modal fusion. Moreover, we develop a Static-Moving Switch Augmentation (SMSA) algorithm, which utilizes sufficient temporal information to enable objects to switch their motion states freely, thus greatly increasing static and moving training samples. Our TASeg ranks 1st on three challenging tracks, i.e., SemanticKITTI single-scan track, multi-scan track and nuScenes LiDAR segmentation track, strongly demonstrating the superiority of our method. Codes are available at https://github.com/LittlePey/TASeg.
SARATR-X: A Foundation Model for Synthetic Aperture Radar Images Target Recognition
May 15, 2024

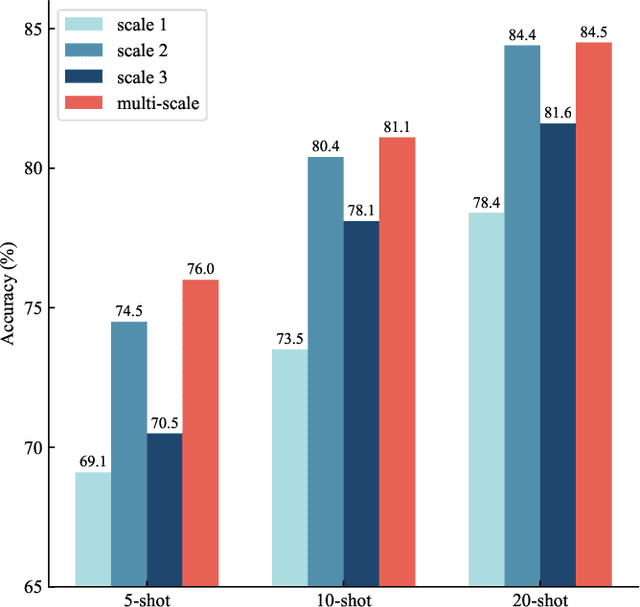

Synthetic aperture radar (SAR) is essential in actively acquiring information for Earth observation. SAR Automatic Target Recognition (ATR) focuses on detecting and classifying various target categories under different image conditions. The current deep learning-based SAR ATR methods are typically designed for specific datasets and applications. Various target characteristics, scene background information, and sensor parameters across ATR datasets challenge the generalization of those methods. This paper aims to achieve general SAR ATR based on a foundation model with Self-Supervised Learning (SSL). Our motivation is to break through the specific dataset and condition limitations and obtain universal perceptual capabilities across the target, scene, and sensor. A foundation model named SARATR-X is proposed with the following four aspects: pre-training dataset, model backbone, SSL, and evaluation task. First, we integrated 14 datasets with various target categories and imaging conditions as a pre-training dataset. Second, different model backbones were discussed to find the most suitable approaches for remote-sensing images. Third, we applied two-stage training and SAR gradient features to ensure the diversity and scalability of SARATR-X. Finally, SARATR-X has achieved competitive and superior performance on 5 datasets with 8 task settings, which shows that the foundation model can achieve universal SAR ATR. We believe it is time to embrace fundamental models for SAR image interpretation in the era of increasing big data.
NeRF-Det++: Incorporating Semantic Cues and Perspective-aware Depth Supervision for Indoor Multi-View 3D Detection
Feb 22, 2024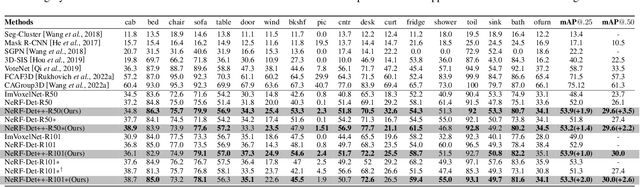
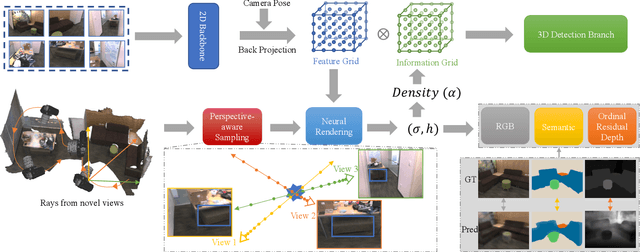
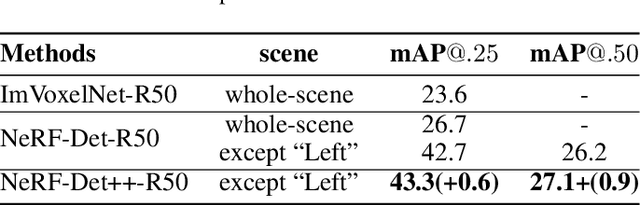

NeRF-Det has achieved impressive performance in indoor multi-view 3D detection by innovatively utilizing NeRF to enhance representation learning. Despite its notable performance, we uncover three decisive shortcomings in its current design, including semantic ambiguity, inappropriate sampling, and insufficient utilization of depth supervision. To combat the aforementioned problems, we present three corresponding solutions: 1) Semantic Enhancement. We project the freely available 3D segmentation annotations onto the 2D plane and leverage the corresponding 2D semantic maps as the supervision signal, significantly enhancing the semantic awareness of multi-view detectors. 2) Perspective-aware Sampling. Instead of employing the uniform sampling strategy, we put forward the perspective-aware sampling policy that samples densely near the camera while sparsely in the distance, more effectively collecting the valuable geometric clues. 3)Ordinal Residual Depth Supervision. As opposed to directly regressing the depth values that are difficult to optimize, we divide the depth range of each scene into a fixed number of ordinal bins and reformulate the depth prediction as the combination of the classification of depth bins as well as the regression of the residual depth values, thereby benefiting the depth learning process. The resulting algorithm, NeRF-Det++, has exhibited appealing performance in the ScanNetV2 and ARKITScenes datasets. Notably, in ScanNetV2, NeRF-Det++ outperforms the competitive NeRF-Det by +1.9% in mAP@0.25 and +3.5% in mAP@0.50$. The code will be publicly at https://github.com/mrsempress/NeRF-Detplusplus.
A Comprehensive Survey on 3D Content Generation
Feb 02, 2024
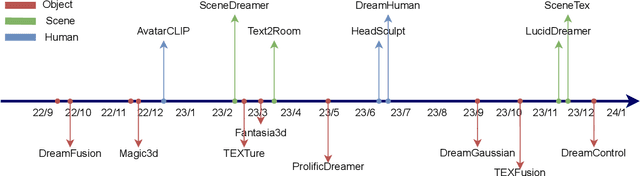

Recent years have witnessed remarkable advances in artificial intelligence generated content(AIGC), with diverse input modalities, e.g., text, image, video, audio and 3D. The 3D is the most close visual modality to real-world 3D environment and carries enormous knowledge. The 3D content generation shows both academic and practical values while also presenting formidable technical challenges. This review aims to consolidate developments within the burgeoning domain of 3D content generation. Specifically, a new taxonomy is proposed that categorizes existing approaches into three types: 3D native generative methods, 2D prior-based 3D generative methods, and hybrid 3D generative methods. The survey covers approximately 60 papers spanning the major techniques. Besides, we discuss limitations of current 3D content generation techniques, and point out open challenges as well as promising directions for future work. Accompanied with this survey, we have established a project website where the resources on 3D content generation research are provided. The project page is available at https://github.com/hitcslj/Awesome-AIGC-3D.
Self-Supervised Learning for SAR ATR with a Knowledge-Guided Predictive Architecture
Nov 26, 2023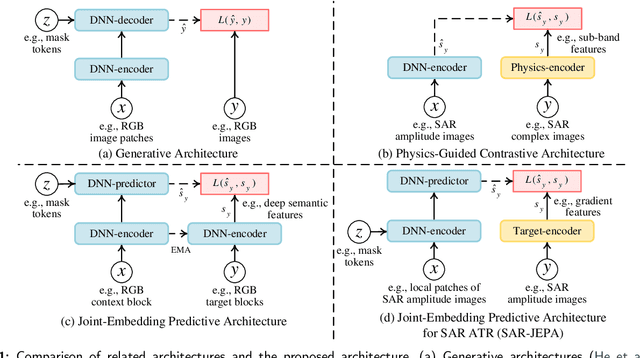
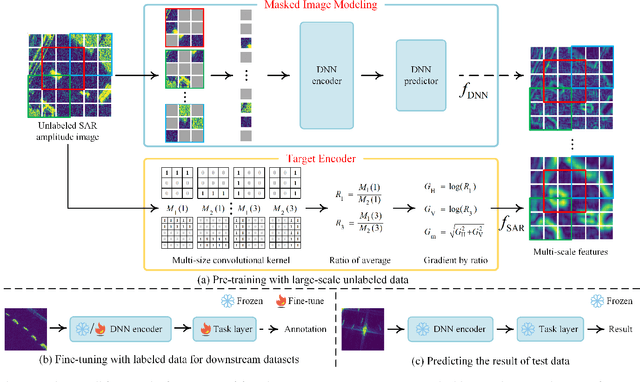

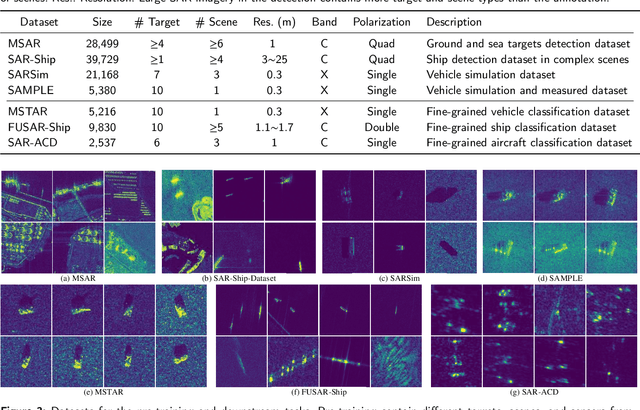
Recently, the emergence of a large number of Synthetic Aperture Radar (SAR) sensors and target datasets has made it possible to unify downstream tasks with self-supervised learning techniques, which can pave the way for building the foundation model in the SAR target recognition field. The major challenge of self-supervised learning for SAR target recognition lies in the generalizable representation learning in low data quality and noise.To address the aforementioned problem, we propose a knowledge-guided predictive architecture that uses local masked patches to predict the multiscale SAR feature representations of unseen context. The core of the proposed architecture lies in combining traditional SAR domain feature extraction with state-of-the-art scalable self-supervised learning for accurate generalized feature representations. The proposed framework is validated on various downstream datasets (MSTAR, FUSAR-Ship, SAR-ACD and SSDD), and can bring consistent performance improvement for SAR target recognition. The experimental results strongly demonstrate the unified performance improvement of the self-supervised learning technique for SAR target recognition across diverse targets, scenes and sensors.
Point Cloud Pre-training with Diffusion Models
Nov 25, 2023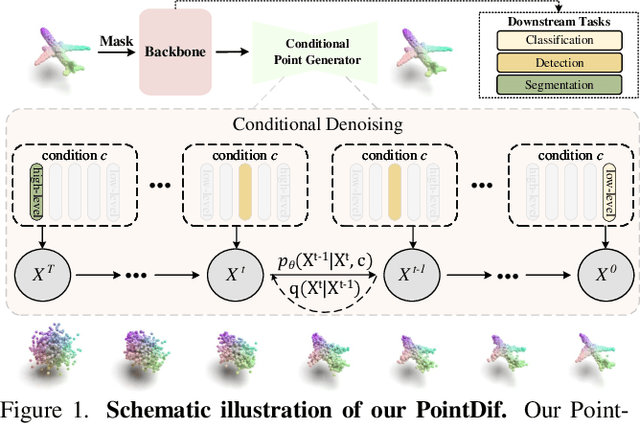
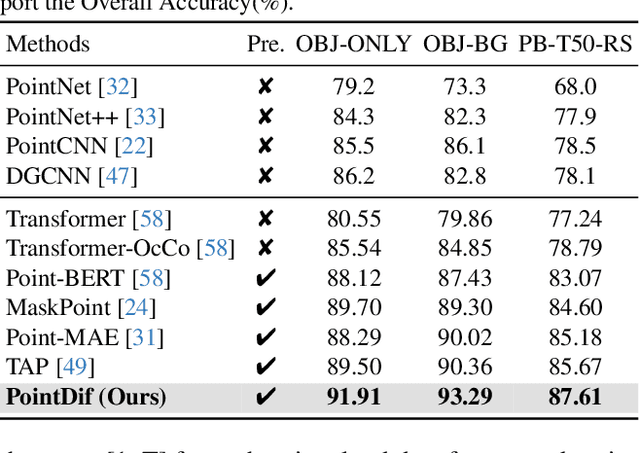
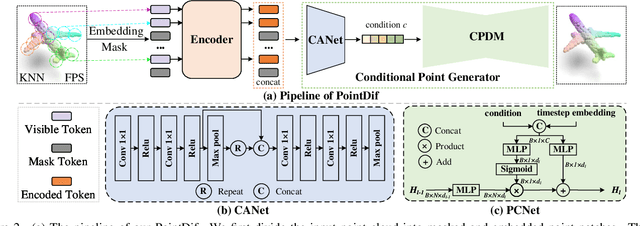
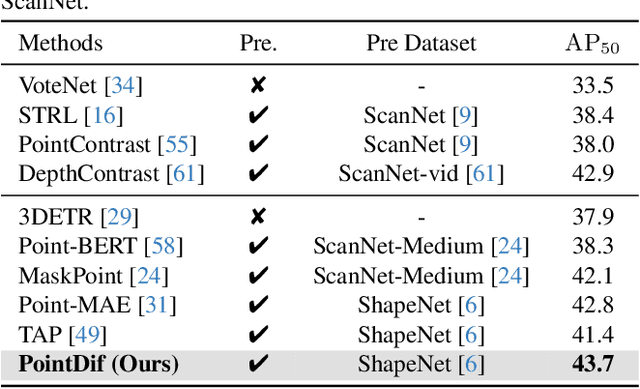
Pre-training a model and then fine-tuning it on downstream tasks has demonstrated significant success in the 2D image and NLP domains. However, due to the unordered and non-uniform density characteristics of point clouds, it is non-trivial to explore the prior knowledge of point clouds and pre-train a point cloud backbone. In this paper, we propose a novel pre-training method called Point cloud Diffusion pre-training (PointDif). We consider the point cloud pre-training task as a conditional point-to-point generation problem and introduce a conditional point generator. This generator aggregates the features extracted by the backbone and employs them as the condition to guide the point-to-point recovery from the noisy point cloud, thereby assisting the backbone in capturing both local and global geometric priors as well as the global point density distribution of the object. We also present a recurrent uniform sampling optimization strategy, which enables the model to uniformly recover from various noise levels and learn from balanced supervision. Our PointDif achieves substantial improvement across various real-world datasets for diverse downstream tasks such as classification, segmentation and detection. Specifically, PointDif attains 70.0% mIoU on S3DIS Area 5 for the segmentation task and achieves an average improvement of 2.4% on ScanObjectNN for the classification task compared to TAP. Furthermore, our pre-training framework can be flexibly applied to diverse point cloud backbones and bring considerable gains.
UniSeg: A Unified Multi-Modal LiDAR Segmentation Network and the OpenPCSeg Codebase
Sep 11, 2023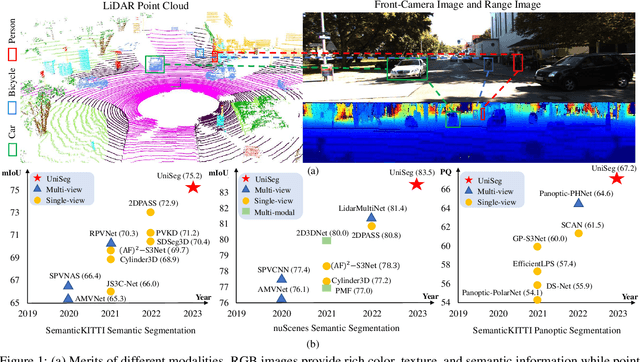

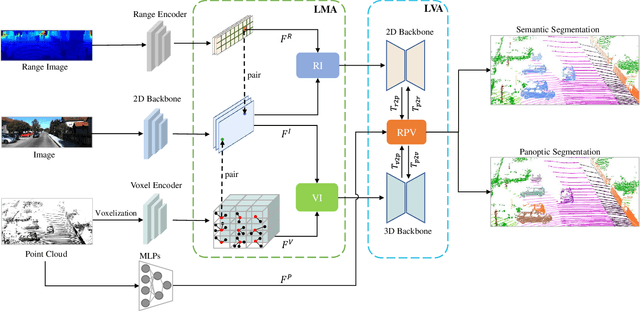
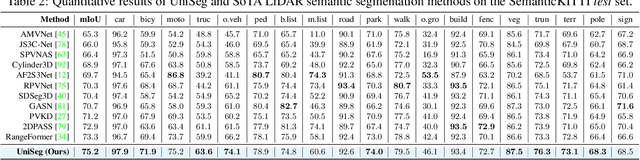
Point-, voxel-, and range-views are three representative forms of point clouds. All of them have accurate 3D measurements but lack color and texture information. RGB images are a natural complement to these point cloud views and fully utilizing the comprehensive information of them benefits more robust perceptions. In this paper, we present a unified multi-modal LiDAR segmentation network, termed UniSeg, which leverages the information of RGB images and three views of the point cloud, and accomplishes semantic segmentation and panoptic segmentation simultaneously. Specifically, we first design the Learnable cross-Modal Association (LMA) module to automatically fuse voxel-view and range-view features with image features, which fully utilize the rich semantic information of images and are robust to calibration errors. Then, the enhanced voxel-view and range-view features are transformed to the point space,where three views of point cloud features are further fused adaptively by the Learnable cross-View Association module (LVA). Notably, UniSeg achieves promising results in three public benchmarks, i.e., SemanticKITTI, nuScenes, and Waymo Open Dataset (WOD); it ranks 1st on two challenges of two benchmarks, including the LiDAR semantic segmentation challenge of nuScenes and panoptic segmentation challenges of SemanticKITTI. Besides, we construct the OpenPCSeg codebase, which is the largest and most comprehensive outdoor LiDAR segmentation codebase. It contains most of the popular outdoor LiDAR segmentation algorithms and provides reproducible implementations. The OpenPCSeg codebase will be made publicly available at https://github.com/PJLab-ADG/PCSeg.