 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGORA: An Archive-Grounded Benchmark for Agentic Workplace Document Reasoning
Jun 23, 2026Large language models are increasingly deployed as agents that reason over documents rather than answer from parametric knowledge. We study archive-grounded reasoning: locating sparse evidence across a large, messy collection of workplace files, reconciling inconsistent terminology, units, and time conventions, and computing an answer. Existing benchmarks address only parts of this setting and none jointly stresses archive-groundedness, agentic exploration, and cross-domain coverage. We introduce Agora, a benchmark pairing 362 questions with eight domain collections of 9,664 authentic documents and 372M tokens, far exceeding any model's context window, so agents must explore deliberately rather than scan exhaustively. Agora is built by an agentic pipeline combining cross-document task synthesis, leakage-preventing obfuscation, and difficulty filtering. Evaluating eight models, we find the task far from solved: even the strongest reaches only 59.4% accuracy, with notable variation across domains.
Learning Multi-Modal Trajectory Policies for Data-Efficient Robotic Manipulation
May 31, 2026Robotic manipulation requires the effective integration of heterogeneous inputs, including visual observations, language instructions, and trajectory representations, to generate accurate actions. Existing transformer-based policies typically process these heterogeneous modalities within a shared parameter space, which often leads to modality interference and inefficient representation learning, especially in data-scarce scenarios. While Mixture-of-Experts (MoE) offers a scalable solution through expert specialization, conventional routing mechanisms are often sensitive to such cross-modal representation discrepancies, resulting in unstable expert assignment and expert collapse. In this work, we propose MATE (Multi-ModAl TrajEctory Policies), a novel trajectory prediction framework built upon MoE. Specifically, we introduce a Multi-Modal MoE architecture to achieve fine-grained sub-token feature decoupling, and design a cross-modal cosine router for stable and scale-invariant expert assignment across heterogeneous modalities. We further employ temperature-controlled routing and stochastic noise injection to improve expert balance and prevent premature routing collapse under scarce demonstrations. Experiments on the LIBERO benchmark show that our MATE consistently outperforms prior work under data scarcity. It achieves a 4.75% improvement in average success rate over the trajectory-guided counterpart. Real-world experiments on robotic ping-pong also suggest that the predicted trajectories can provide useful guidance for downstream robotic execution, further indicating the practical feasibility of our algorithm.
Light-ResKAN: A Parameter-Sharing Lightweight KAN with Gram Polynomials for Efficient SAR Image Recognition
Apr 02, 2026Synthetic Aperture Radar (SAR) image recognition is vital for disaster monitoring, military reconnaissance, and ocean observation. However, large SAR image sizes hinder deep learning deployment on resource-constrained edge devices, and existing lightweight models struggle to balance high-precision feature extraction with low computational requirements. The emerging Kolmogorov-Arnold Network (KAN) enhances fitting by replacing fixed activations with learnable ones, reducing parameters and computation. Inspired by KAN, we propose Light-ResKAN to achieve a better balance between precision and efficiency. First, Light-ResKAN modifies ResNet by replacing convolutions with KAN convolutions, enabling adaptive feature extraction for SAR images. Second, we use Gram Polynomials as activations, which are well-suited for SAR data to capture complex non-linear relationships. Third, we employ a parameter-sharing strategy: each kernel shares parameters per channel, preserving unique features while reducing parameters and FLOPs. Our model achieves 99.09%, 93.01%, and 97.26% accuracy on MSTAR, FUSAR-Ship, and SAR-ACD datasets, respectively. Experiments on MSTAR resized to $1024 \times 1024$ show that compared to VGG16, our model reduces FLOPs by $82.90 \times$ and parameters by $163.78 \times$. This work establishes an efficient solution for edge SAR image recognition.
PCoKG: Personality-aware Commonsense Reasoning with Debate
Jan 09, 2026Most commonsense reasoning models overlook the influence of personality traits, limiting their effectiveness in personalized systems such as dialogue generation. To address this limitation, we introduce the Personality-aware Commonsense Knowledge Graph (PCoKG), a structured dataset comprising 521,316 quadruples. We begin by employing three evaluators to score and filter events from the ATOMIC dataset, selecting those that are likely to elicit diverse reasoning patterns across different personality types. For knowledge graph construction, we leverage the role-playing capabilities of large language models (LLMs) to perform reasoning tasks. To enhance the quality of the generated knowledge, we incorporate a debate mechanism consisting of a proponent, an opponent, and a judge, which iteratively refines the outputs through feedback loops. We evaluate the dataset from multiple perspectives and conduct fine-tuning and ablation experiments using multiple LLM backbones to assess PCoKG's robustness and the effectiveness of its construction pipeline. Our LoRA-based fine-tuning results indicate a positive correlation between model performance and the parameter scale of the base models. Finally, we apply PCoKG to persona-based dialogue generation, where it demonstrates improved consistency between generated responses and reference outputs. This work bridges the gap between commonsense reasoning and individual cognitive differences, enabling the development of more personalized and context-aware AI systems.
Fifty Years of SAR Automatic Target Recognition: The Road Forward
Sep 26, 2025This paper provides the first comprehensive review of fifty years of synthetic aperture radar automatic target recognition (SAR ATR) development, tracing its evolution from inception to the present day. Central to our analysis is the inheritance and refinement of traditional methods, such as statistical modeling, scattering center analysis, and feature engineering, within modern deep learning frameworks. The survey clearly distinguishes long-standing challenges that have been substantially mitigated by deep learning from newly emerging obstacles. We synthesize recent advances in physics-guided deep learning and propose future directions toward more generalizable and physically-consistent SAR ATR. Additionally, we provide a systematically organized compilation of all publicly available SAR datasets, complete with direct links to support reproducibility and benchmarking. This work not only documents the technical evolution of the field but also offers practical resources and forward-looking insights for researchers and practitioners. A systematic summary of existing literature, code, and datasets are open-sourced at \href{https://github.com/JoyeZLearning/SAR-ATR-From-Beginning-to-Present}{https://github.com/JoyeZLearning/SAR-ATR-From-Beginning-to-Present}.
SARDet-100K: Towards Open-Source Benchmark and ToolKit for Large-Scale SAR Object Detection
Mar 11, 2024


Synthetic Aperture Radar (SAR) object detection has gained significant attention recently due to its irreplaceable all-weather imaging capabilities. However, this research field suffers from both limited public datasets (mostly comprising <2K images with only mono-category objects) and inaccessible source code. To tackle these challenges, we establish a new benchmark dataset and an open-source method for large-scale SAR object detection. Our dataset, SARDet-100K, is a result of intense surveying, collecting, and standardizing 10 existing SAR detection datasets, providing a large-scale and diverse dataset for research purposes. To the best of our knowledge, SARDet-100K is the first COCO-level large-scale multi-class SAR object detection dataset ever created. With this high-quality dataset, we conducted comprehensive experiments and uncovered a crucial challenge in SAR object detection: the substantial disparities between the pretraining on RGB datasets and finetuning on SAR datasets in terms of both data domain and model structure. To bridge these gaps, we propose a novel Multi-Stage with Filter Augmentation (MSFA) pretraining framework that tackles the problems from the perspective of data input, domain transition, and model migration. The proposed MSFA method significantly enhances the performance of SAR object detection models while demonstrating exceptional generalizability and flexibility across diverse models. This work aims to pave the way for further advancements in SAR object detection. The dataset and code is available at https://github.com/zcablii/SARDet_100K.
Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation
Mar 05, 2024



Image-to-video (I2V) generation tasks always suffer from keeping high fidelity in the open domains. Traditional image animation techniques primarily focus on specific domains such as faces or human poses, making them difficult to generalize to open domains. Several recent I2V frameworks based on diffusion models can generate dynamic content for open domain images but fail to maintain fidelity. We found that two main factors of low fidelity are the loss of image details and the noise prediction biases during the denoising process. To this end, we propose an effective method that can be applied to mainstream video diffusion models. This method achieves high fidelity based on supplementing more precise image information and noise rectification. Specifically, given a specified image, our method first adds noise to the input image latent to keep more details, then denoises the noisy latent with proper rectification to alleviate the noise prediction biases. Our method is tuning-free and plug-and-play. The experimental results demonstrate the effectiveness of our approach in improving the fidelity of generated videos. For more image-to-video generated results, please refer to the project website: https://noise-rectification.github.io.
AtomoVideo: High Fidelity Image-to-Video Generation
Mar 05, 2024



Recently, video generation has achieved significant rapid development based on superior text-to-image generation techniques. In this work, we propose a high fidelity framework for image-to-video generation, named AtomoVideo. Based on multi-granularity image injection, we achieve higher fidelity of the generated video to the given image. In addition, thanks to high quality datasets and training strategies, we achieve greater motion intensity while maintaining superior temporal consistency and stability. Our architecture extends flexibly to the video frame prediction task, enabling long sequence prediction through iterative generation. Furthermore, due to the design of adapter training, our approach can be well combined with existing personalized models and controllable modules. By quantitatively and qualitatively evaluation, AtomoVideo achieves superior results compared to popular methods, more examples can be found on our project website: https://atomo-video.github.io/.
Self-Supervised Learning for SAR ATR with a Knowledge-Guided Predictive Architecture
Nov 26, 2023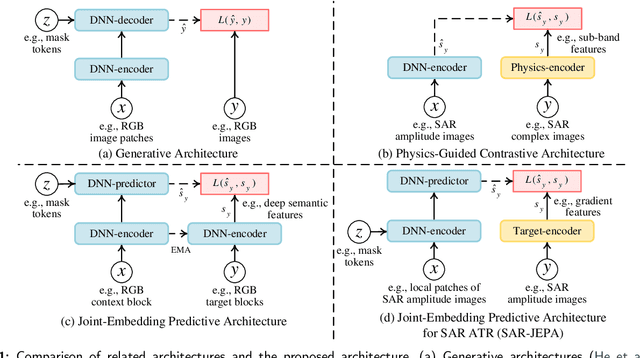
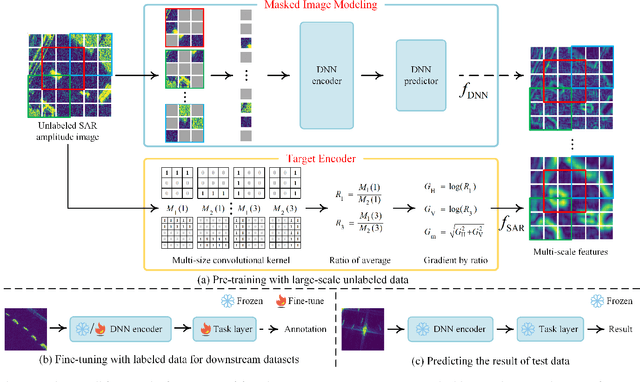

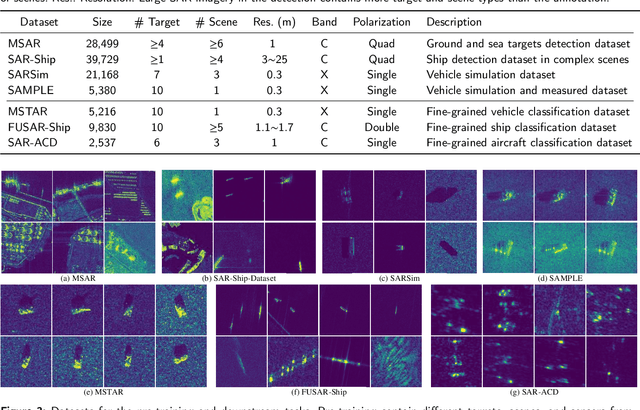
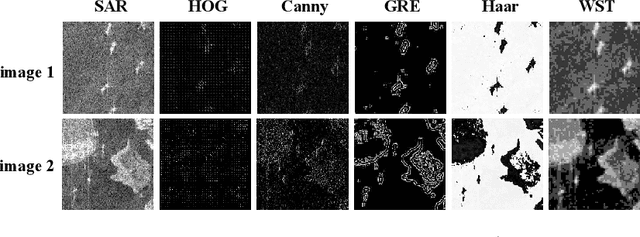
Recently, the emergence of a large number of Synthetic Aperture Radar (SAR) sensors and target datasets has made it possible to unify downstream tasks with self-supervised learning techniques, which can pave the way for building the foundation model in the SAR target recognition field. The major challenge of self-supervised learning for SAR target recognition lies in the generalizable representation learning in low data quality and noise.To address the aforementioned problem, we propose a knowledge-guided predictive architecture that uses local masked patches to predict the multiscale SAR feature representations of unseen context. The core of the proposed architecture lies in combining traditional SAR domain feature extraction with state-of-the-art scalable self-supervised learning for accurate generalized feature representations. The proposed framework is validated on various downstream datasets (MSTAR, FUSAR-Ship, SAR-ACD and SSDD), and can bring consistent performance improvement for SAR target recognition. The experimental results strongly demonstrate the unified performance improvement of the self-supervised learning technique for SAR target recognition across diverse targets, scenes and sensors.
UMAAF: Unveiling Aesthetics via Multifarious Attributes of Images
Nov 21, 2023



With the increasing prevalence of smartphones and websites, Image Aesthetic Assessment (IAA) has become increasingly crucial. While the significance of attributes in IAA is widely recognized, many attribute-based methods lack consideration for the selection and utilization of aesthetic attributes. Our initial step involves the acquisition of aesthetic attributes from both intra- and inter-perspectives. Within the intra-perspective, we extract the direct visual attributes of images, constituting the absolute attribute. In the inter-perspective, our focus lies in modeling the relative score relationships between images within the same sequence, forming the relative attribute. Then, to better utilize image attributes in aesthetic assessment, we propose the Unified Multi-attribute Aesthetic Assessment Framework (UMAAF) to model both absolute and relative attributes of images. For absolute attributes, we leverage multiple absolute-attribute perception modules and an absolute-attribute interacting network. The absolute-attribute perception modules are first pre-trained on several absolute-attribute learning tasks and then used to extract corresponding absolute attribute features. The absolute-attribute interacting network adaptively learns the weight of diverse absolute-attribute features, effectively integrating them with generic aesthetic features from various absolute-attribute perspectives and generating the aesthetic prediction. To model the relative attribute of images, we consider the relative ranking and relative distance relationships between images in a Relative-Relation Loss function, which boosts the robustness of the UMAAF. Furthermore, UMAAF achieves state-of-the-art performance on TAD66K and AVA datasets, and multiple experiments demonstrate the effectiveness of each module and the model's alignment with human preference.