 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCFT: Hierarchical Convolutional Fusion Transformer for EEG Decoding
Jan 18, 2026Electroencephalography (EEG) decoding requires models that can effectively extract and integrate complex temporal, spectral, and spatial features from multichannel signals. To address this challenge, we propose a lightweight and generalizable decoding framework named Hierarchical Convolutional Fusion Transformer (HCFT), which combines dual-branch convolutional encoders and hierarchical Transformer blocks for multi-scale EEG representation learning. Specifically, the model first captures local temporal and spatiotemporal dynamics through time-domain and time-space convolutional branches, and then aligns these features via a cross-attention mechanism that enables interaction between branches at each stage. Subsequently, a hierarchical Transformer fusion structure is employed to encode global dependencies across all feature stages, while a customized Dynamic Tanh normalization module is introduced to replace traditional Layer Normalization in order to enhance training stability and reduce redundancy. Extensive experiments are conducted on two representative benchmark datasets, BCI Competition IV-2b and CHB-MIT, covering both event-related cross-subject classification and continuous seizure prediction tasks. Results show that HCFT achieves 80.83% average accuracy and a Cohen's kappa of 0.6165 on BCI IV-2b, as well as 99.10% sensitivity, 0.0236 false positives per hour, and 98.82% specificity on CHB-MIT, consistently outperforming over ten state-of-the-art baseline methods. Ablation studies confirm that each core component of the proposed framework contributes significantly to the overall decoding performance, demonstrating HCFT's effectiveness in capturing EEG dynamics and its potential for real-world BCI applications.
Implicit Kinodynamic Motion Retargeting for Human-to-humanoid Imitation Learning
Sep 18, 2025Human-to-humanoid imitation learning aims to learn a humanoid whole-body controller from human motion. Motion retargeting is a crucial step in enabling robots to acquire reference trajectories when exploring locomotion skills. However, current methods focus on motion retargeting frame by frame, which lacks scalability. Could we directly convert large-scale human motion into robot-executable motion through a more efficient approach? To address this issue, we propose Implicit Kinodynamic Motion Retargeting (IKMR), a novel efficient and scalable retargeting framework that considers both kinematics and dynamics. In kinematics, IKMR pretrains motion topology feature representation and a dual encoder-decoder architecture to learn a motion domain mapping. In dynamics, IKMR integrates imitation learning with the motion retargeting network to refine motion into physically feasible trajectories. After fine-tuning using the tracking results, IKMR can achieve large-scale physically feasible motion retargeting in real time, and a whole-body controller could be directly trained and deployed for tracking its retargeted trajectories. We conduct our experiments both in the simulator and the real robot on a full-size humanoid robot. Extensive experiments and evaluation results verify the effectiveness of our proposed framework.
TOP: Time Optimization Policy for Stable and Accurate Standing Manipulation with Humanoid Robots
Aug 01, 2025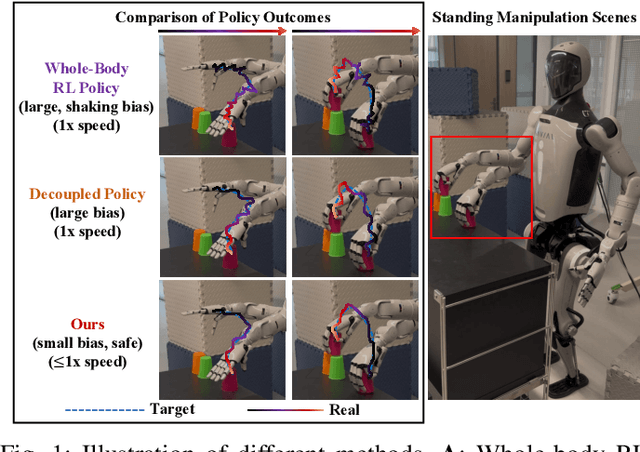

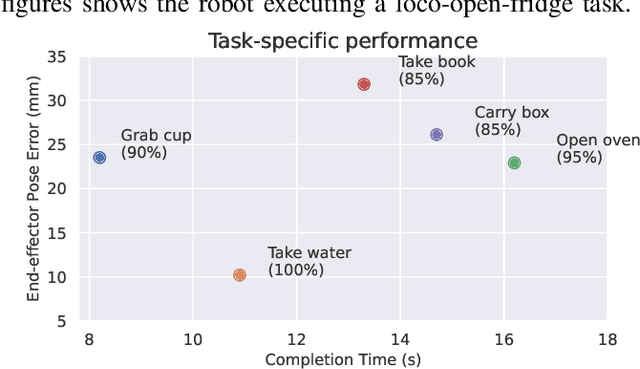
Humanoid robots have the potential capability to perform a diverse range of manipulation tasks, but this is based on a robust and precise standing controller. Existing methods are either ill-suited to precisely control high-dimensional upper-body joints, or difficult to ensure both robustness and accuracy, especially when upper-body motions are fast. This paper proposes a novel time optimization policy (TOP), to train a standing manipulation control model that ensures balance, precision, and time efficiency simultaneously, with the idea of adjusting the time trajectory of upper-body motions but not only strengthening the disturbance resistance of the lower-body. Our approach consists of three parts. Firstly, we utilize motion prior to represent upper-body motions to enhance the coordination ability between the upper and lower-body by training a variational autoencoder (VAE). Then we decouple the whole-body control into an upper-body PD controller for precision and a lower-body RL controller to enhance robust stability. Finally, we train TOP method in conjunction with the decoupled controller and VAE to reduce the balance burden resulting from fast upper-body motions that would destabilize the robot and exceed the capabilities of the lower-body RL policy. The effectiveness of the proposed approach is evaluated via both simulation and real world experiments, which demonstrate the superiority on standing manipulation tasks stably and accurately. The project page can be found at https://anonymous.4open.science/w/top-258F/.
Transformer-based EEG Decoding: A Survey
Jul 03, 2025Electroencephalography (EEG) is one of the most common signals used to capture the electrical activity of the brain, and the decoding of EEG, to acquire the user intents, has been at the forefront of brain-computer/machine interfaces (BCIs/BMIs) research. Compared to traditional EEG analysis methods with machine learning, the advent of deep learning approaches have gradually revolutionized the field by providing an end-to-end long-cascaded architecture, which can learn more discriminative features automatically. Among these, Transformer is renowned for its strong handling capability of sequential data by the attention mechanism, and the application of Transformers in various EEG processing tasks is increasingly prevalent. This article delves into a relevant survey, summarizing the latest application of Transformer models in EEG decoding since it appeared. The evolution of the model architecture is followed to sort and organize the related advances, in which we first elucidate the fundamentals of the Transformer that benefits EEG decoding and its direct application. Then, the common hybrid architectures by integrating basic Transformer with other deep learning techniques (convolutional/recurrent/graph/spiking neural netwo-rks, generative adversarial networks, diffusion models, etc.) is overviewed in detail. The research advances of applying the modified intrinsic structures of customized Transformer have also been introduced. Finally, the current challenges and future development prospects in this rapidly evolving field are discussed. This paper aims to help readers gain a clear understanding of the current state of Transformer applications in EEG decoding and to provide valuable insights for future research endeavors.
SlowFastVAD: Video Anomaly Detection via Integrating Simple Detector and RAG-Enhanced Vision-Language Model
Apr 14, 2025Video anomaly detection (VAD) aims to identify unexpected events in videos and has wide applications in safety-critical domains. While semi-supervised methods trained on only normal samples have gained traction, they often suffer from high false alarm rates and poor interpretability. Recently, vision-language models (VLMs) have demonstrated strong multimodal reasoning capabilities, offering new opportunities for explainable anomaly detection. However, their high computational cost and lack of domain adaptation hinder real-time deployment and reliability. Inspired by dual complementary pathways in human visual perception, we propose SlowFastVAD, a hybrid framework that integrates a fast anomaly detector with a slow anomaly detector (namely a retrieval augmented generation (RAG) enhanced VLM), to address these limitations. Specifically, the fast detector first provides coarse anomaly confidence scores, and only a small subset of ambiguous segments, rather than the entire video, is further analyzed by the slower yet more interpretable VLM for elaborate detection and reasoning. Furthermore, to adapt VLMs to domain-specific VAD scenarios, we construct a knowledge base including normal patterns based on few normal samples and abnormal patterns inferred by VLMs. During inference, relevant patterns are retrieved and used to augment prompts for anomaly reasoning. Finally, we smoothly fuse the anomaly confidence of fast and slow detectors to enhance robustness of anomaly detection. Extensive experiments on four benchmarks demonstrate that SlowFastVAD effectively combines the strengths of both fast and slow detectors, and achieves remarkable detection accuracy and interpretability with significantly reduced computational overhead, making it well-suited for real-world VAD applications with high reliability requirements.
Re-Aligning Language to Visual Objects with an Agentic Workflow
Mar 30, 2025Language-based object detection (LOD) aims to align visual objects with language expressions. A large amount of paired data is utilized to improve LOD model generalizations. During the training process, recent studies leverage vision-language models (VLMs) to automatically generate human-like expressions for visual objects, facilitating training data scaling up. In this process, we observe that VLM hallucinations bring inaccurate object descriptions (e.g., object name, color, and shape) to deteriorate VL alignment quality. To reduce VLM hallucinations, we propose an agentic workflow controlled by an LLM to re-align language to visual objects via adaptively adjusting image and text prompts. We name this workflow Real-LOD, which includes planning, tool use, and reflection steps. Given an image with detected objects and VLM raw language expressions, Real-LOD reasons its state automatically and arranges action based on our neural symbolic designs (i.e., planning). The action will adaptively adjust the image and text prompts and send them to VLMs for object re-description (i.e., tool use). Then, we use another LLM to analyze these refined expressions for feedback (i.e., reflection). These steps are conducted in a cyclic form to gradually improve language descriptions for re-aligning to visual objects. We construct a dataset that contains a tiny amount of 0.18M images with re-aligned language expression and train a prevalent LOD model to surpass existing LOD methods by around 50% on the standard benchmarks. Our Real-LOD workflow, with automatic VL refinement, reveals a potential to preserve data quality along with scaling up data quantity, which further improves LOD performance from a data-alignment perspective.
Natural Humanoid Robot Locomotion with Generative Motion Prior
Mar 12, 2025Natural and lifelike locomotion remains a fundamental challenge for humanoid robots to interact with human society. However, previous methods either neglect motion naturalness or rely on unstable and ambiguous style rewards. In this paper, we propose a novel Generative Motion Prior (GMP) that provides fine-grained motion-level supervision for the task of natural humanoid robot locomotion. To leverage natural human motions, we first employ whole-body motion retargeting to effectively transfer them to the robot. Subsequently, we train a generative model offline to predict future natural reference motions for the robot based on a conditional variational auto-encoder. During policy training, the generative motion prior serves as a frozen online motion generator, delivering precise and comprehensive supervision at the trajectory level, including joint angles and keypoint positions. The generative motion prior significantly enhances training stability and improves interpretability by offering detailed and dense guidance throughout the learning process. Experimental results in both simulation and real-world environments demonstrate that our method achieves superior motion naturalness compared to existing approaches. Project page can be found at https://sites.google.com/view/humanoid-gmp
Dual-TSST: A Dual-Branch Temporal-Spectral-Spatial Transformer Model for EEG Decoding
Sep 05, 2024



The decoding of electroencephalography (EEG) signals allows access to user intentions conveniently, which plays an important role in the fields of human-machine interaction. To effectively extract sufficient characteristics of the multichannel EEG, a novel decoding architecture network with a dual-branch temporal-spectral-spatial transformer (Dual-TSST) is proposed in this study. Specifically, by utilizing convolutional neural networks (CNNs) on different branches, the proposed processing network first extracts the temporal-spatial features of the original EEG and the temporal-spectral-spatial features of time-frequency domain data converted by wavelet transformation, respectively. These perceived features are then integrated by a feature fusion block, serving as the input of the transformer to capture the global long-range dependencies entailed in the non-stationary EEG, and being classified via the global average pooling and multi-layer perceptron blocks. To evaluate the efficacy of the proposed approach, the competitive experiments are conducted on three publicly available datasets of BCI IV 2a, BCI IV 2b, and SEED, with the head-to-head comparison of more than ten other state-of-the-art methods. As a result, our proposed Dual-TSST performs superiorly in various tasks, which achieves the promising EEG classification performance of average accuracy of 80.67% in BCI IV 2a, 88.64% in BCI IV 2b, and 96.65% in SEED, respectively. Extensive ablation experiments conducted between the Dual-TSST and comparative baseline model also reveal the enhanced decoding performance with each module of our proposed method. This study provides a new approach to high-performance EEG decoding, and has great potential for future CNN-Transformer based applications.
Sparse Array Enabled Near-Field Communications: Beam Pattern Analysis and Hybrid Beamforming Design
Jan 11, 2024Extremely large-scale array (XL-array) has emerged as a promising technology to enable near-field communications for achieving enhanced spectrum efficiency and spatial resolution, by drastically increasing the number of antennas. However, this also inevitably incurs higher hardware and energy cost, which may not be affordable in future wireless systems. To address this issue, we propose in this paper to exploit two types of sparse arrays (SAs) for enabling near-field communications. Specifically, we first consider the linear sparse array (LSA) and characterize its near-field beam pattern. It is shown that despite the achieved beam-focusing gain, the LSA introduces several undesired grating-lobes, which have comparable beam power with the main-lobe and are focused on specific regions. An efficient hybrid beamforming design is then proposed for the LSA to deal with the potential strong inter-user interference (IUI). Next, we consider another form of SA, called extended coprime array (ECA), which is composed of two LSA subarrays with different (coprime) inter-antenna spacing. By characterizing the ECA near-field beam pattern, we show that compared with the LSA with the same array sparsity, the ECA can greatly suppress the beam power of near-field grating-lobes thanks to the offset effect of the two subarrays, albeit with a larger number of grating-lobes. This thus motivates us to propose a customized two-phase hybrid beamforming design for the ECA. Finally, numerical results are presented to demonstrate the rate performance gain of the proposed two SAs over the conventional uniform linear array (ULA).
Semantics-aware Motion Retargeting with Vision-Language Models
Dec 04, 2023



Capturing and preserving motion semantics is essential to motion retargeting between animation characters. However, most of the previous works neglect the semantic information or rely on human-designed joint-level representations. Here, we present a novel Semantics-aware Motion reTargeting (SMT) method with the advantage of vision-language models to extract and maintain meaningful motion semantics. We utilize a differentiable module to render 3D motions. Then the high-level motion semantics are incorporated into the motion retargeting process by feeding the vision-language model with the rendered images and aligning the extracted semantic embeddings. To ensure the preservation of fine-grained motion details and high-level semantics, we adopt a two-stage pipeline consisting of skeleton-aware pre-training and fine-tuning with semantics and geometry constraints. Experimental results show the effectiveness of the proposed method in producing high-quality motion retargeting results while accurately preserving motion semantics. Project page can be found at https://sites.google.com/view/smtnet.