 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-complexity Design for Beam Coverage in Near-field and Far-field: A Fourier Transform Approach
Feb 05, 2026In this paper, we study efficient beam coverage design for multi-antenna systems in both far-field and near-field cases. To reduce the computational complexity of existing sampling-based optimization methods, we propose a new low-complexity yet efficient beam coverage design. To this end, we first formulate a general beam coverage optimization problem to maximize the worst-case beamforming gain over a target region. For the far-field case, we show that the beam coverage design can be viewed as a spatial-frequency filtering problem, where angular coverage can be achieved by weight-shaping in the antenna domain via an inverse FT, yielding an infinite-length weighting sequence. Under the constraint of a finite number of antennas, a surrogate scheme is proposed by directly truncating this sequence, which inevitably introduces a roll-off effect at the angular boundaries, yielding degraded worst-case beamforming gain. To address this issue, we characterize the finite-antenna-induced roll-off effect, based on which a roll-off-aware design with a protective zoom is developed to ensure a flat beamforming-gain profile within the target angular region. Next, we extend the proposed method to the near-field case. Specifically, by applying a first-order Taylor approximation to the near-field channel steering vector (CSV), the two-dimensional (2D) beam coverage design (in both angle and inverse-range) can be transformed into a 2D inverse FT, leading to a low-complexity beamforming design. Furthermore, an inherent near-field range defocusing effect is observed, indicating that sufficiently wide angular coverage results in range-insensitive beam steering. Finally, numerical results demonstrate that the proposed FT-based approach achieves a comparable worst-case beamforming performance with that of conventional sampling-based optimization methods while significantly reducing the computational complexity.
Near-field Physical Layer Security: Robust Beamforming under Location Uncertainty
Jan 20, 2026In this paper, we study robust beamforming design for near-field physical-layer-security (PLS) systems, where a base station (BS) equipped with an extremely large-scale array (XL-array) serves multiple near-field legitimate users (Bobs) in the presence of multiple near-field eavesdroppers (Eves). Unlike existing works that mostly assume perfect channel state information (CSI) or location information of Eves, we consider a more practical and challenging scenario, where the locations of Bobs are perfectly known, while only imperfect location information of Eves is available at the BS. We first formulate a robust optimization problem to maximize the sum-rate of Bobs while guaranteeing a worst-case limit on the eavesdropping rate under location uncertainty. By transforming Cartesian position errors into the polar domain, we reveal an important near-field angular-error amplification effect: for the same location error, the closer the Eve, the larger the angle error, severely degrading the performance of conventional robust beamforming methods based on imperfect channel state information. To address this issue, we first establish the conditions for which the first-order Taylor approximation of the near-field channel steering vector under location uncertainty is largely accurate. Then, we propose a two-stage robust beamforming method, which first partitions the uncertainty region into multiple fan-shaped sub-regions, followed by the second stage to formulate and solve a refined linear-matrix-inequality (LMI)-based robust beamforming optimization problem. In addition, the proposed method is further extended to scenarios with multiple Bobs and multiple Eves. Finally, numerical results validate that the proposed method achieves a superior trade-off between rate performance and secrecy robustness, hence significantly outperforming existing benchmarks under Eve location uncertainty.
MA-enhanced Mixed Near-field and Far-field Covert Communications
Nov 11, 2025In this paper, we propose to employ a modular-based movable extremely large-scale array (XL-array) at Alice for enhancing covert communication performance. Compared with existing work that mostly considered either far-field or near-field covert communications, we consider in this paper a more general and practical mixed-field scenario, where multiple Bobs are located in either the near-field or far-field of Alice, in the presence of multiple near-field Willies. Specifically, we first consider a two-Bob-one-Willie system and show that conventional fixed-position XL-arrays suffer degraded sum-rate performance due to the energy-spread effect in mixed-field systems, which, however, can be greatly improved by subarray movement. On the other hand, for transmission covertness, it is revealed that sufficient angle difference between far-field Bob and Willie as well as adequate range difference between near-field Bob and Willie are necessary for ensuring covertness in fixed-position XL-array systems, while this requirement can be relaxed in movable XL-array systems thanks to flexible channel correlation control between Bobs and Willie. Next, for general system setups, we formulate an optimization problem to maximize the achievable sum-rate under covertness constraint. To solve this non-convex optimization problem, we first decompose it into two subproblems, corresponding to an inner problem for beamforming optimization given positions of subarrays and an outer problem for subarray movement optimization. Although these two subproblems are still non-convex, we obtain their high-quality solutions by using the successive convex approximation technique and devising a customized differential evolution algorithm, respectively. Last, numerical results demonstrate the effectiveness of proposed movable XL-array in balancing sum-rate and covert communication requirements.
Joint Frequency-Space Sparse Reconstruction for DOA Estimation under Coherent Sources and Amplitude-Phase Errors
Sep 04, 2025
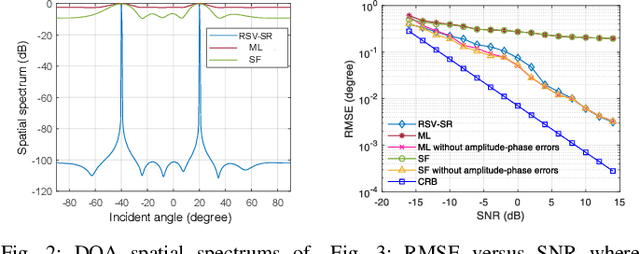
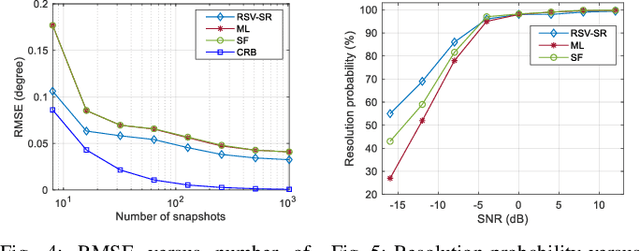
In this letter, we propose a joint frequency-space sparse reconstruction method for direction-of-arrival (DOA) estimation, which effectively addresses the issues arising from the existence of coherent sources and array amplitude-phase errors. Specifically, by using an auxiliary source with known angles, we first construct the real steering vectors (RSVs) based on the spectral peaks of received signals in the frequency domain, which serve as a complete basis matrix for compensation for amplitude-phase errors. Then, we leverage the spectral sparsity of snapshot data in the frequency domain and the spatial sparsity of incident directions to perform the DOA estimation according to the sparse reconstruction method. The proposed method does not require iterative optimization, hence exhibiting low computational complexity. Numerical results demonstrate that the proposed DOA estimation method achieves higher estimation accuracy for coherent sources as compared to various benchmark schemes.
Frequency-switching Array Enhanced Physical-Layer Security in Terahertz Bands: A Movable Antenna Perspective
Jul 02, 2025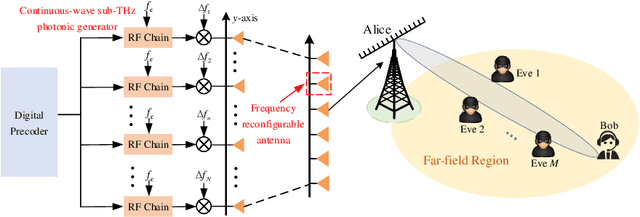
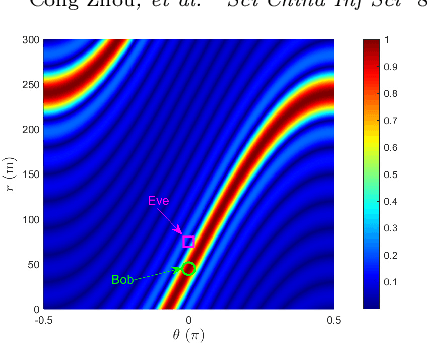
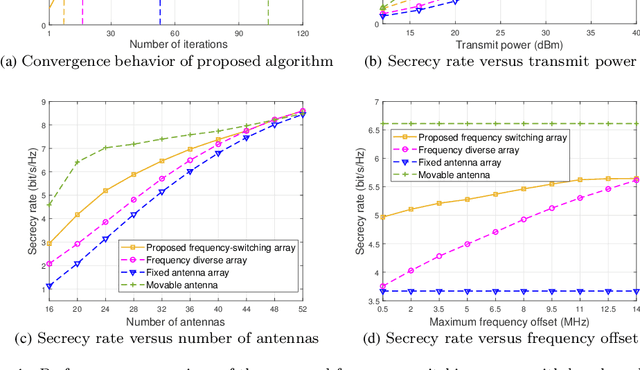
In this paper, we propose a new frequency-switching array (FSA) enhanced physical-layer security (PLS) system in terahertz bands, where the carrier frequency can be flexibly switched and small frequency offsets can be imposed on each antenna at Alice, so as to eliminate information wiretapping by undesired eavesdroppers. First, we analytically show that by flexibly controlling the carrier frequency parameters, FSAs can effectively form uniform/non-uniform sparse arrays, hence resembling movable antennas (MAs) in the control of inter-antenna spacing and providing additional degree-of-freedom (DoF) in the beam control. Although the proposed FSA experiences additional path-gain attenuation in the received signals, it can overcome several hardware and signal processing issues incurred by MAs, such as limited positioning accuracy, considerable response latency, and demanding hardware and energy cost. To shed useful insights, we first consider a secrecy-guaranteed problem with a null-steering constraint for which maximum ratio transmission (MRT) beamformer is considered at Alice and the frequency offsets are set as uniform frequency increment. Interestingly, it is shown that the proposed FSA can flexibly realize null-steering over Eve in both the angular domain (by tuning carrier frequency) and range domain (by controlling per-antenna frequency offset), thereby achieving improved PLS performance. Then, for the general case, we propose an efficient algorithm to solve the formulated non-convex problem by using the block coordinate descent (BCD) and projected gradient ascent (PGA) techniques. Finally, numerical results demonstrate the convergence of the proposed optimization algorithm and its superiority over fixed-position arrays (FPAs) in terms of secrecy-rate performance.
Physical-Layer Security in Mixed Near-Field and Far-Field Communication Systems
Apr 28, 2025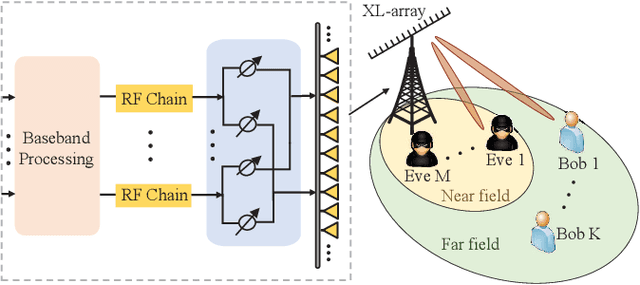
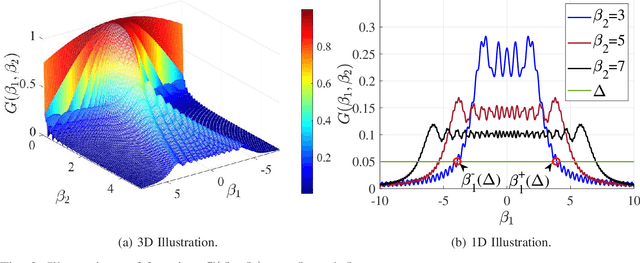
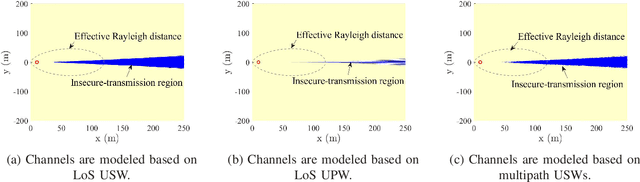
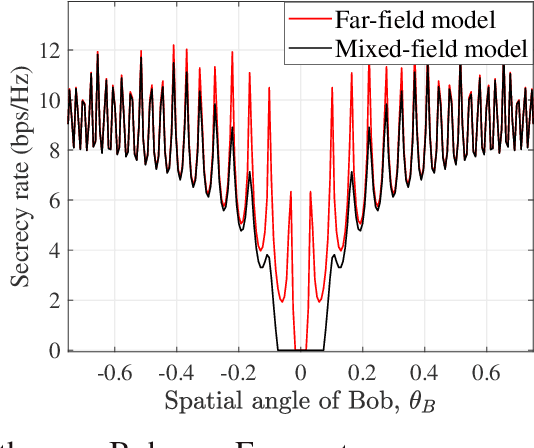
Extremely large-scale arrays (XL-arrays) have emerged as a promising technology to improve the spectrum efficiency and spatial resolution of future wireless systems. Different from existing works that mostly considered physical layer security (PLS) in either the far-field or near-field, we consider in this paper a new and practical scenario, where legitimate users (Bobs) are located in the far-field of a base station (BS) while eavesdroppers (Eves) are located in the near-field for intercepting confidential information at short distance, referred to as the mixed near-field and far-field PLS. Specifically, we formulate an optimization problem to maximize the sum-secrecy-rate of all Bobs by optimizing the power allocation of the BS, subject to the constraint on the total BS transmit power. To shed useful insights, we first consider a one-Bob-one-Eve system and characterize the insecure-transmission region of the Bob in closed form. Interestingly, we show that the insecure-transmission region is significantly \emph{expanded} as compared to that in conventional far-field PLS systems, due to the energy-spread effect in the mixed-field scenario. Then, we further extend the analysis to a two-Bob-one-Eve system. It is revealed that as compared to the one-Bob system, the interferences from the other Bob can be effectively used to weaken the capability of Eve for intercepting signals of target Bobs, thus leading to enhanced secrecy rates. Furthermore, we propose an efficient algorithm to obtain a high-quality solution to the formulated non-convex problem by leveraging the successive convex approximation (SCA) technique. Finally, numerical results demonstrate that our proposed algorithm achieves a higher sum-secrecy-rate than the benchmark scheme where the power allocation is designed based on the (simplified) far-field channel model.
Super-resolution Wideband Beam Training for Near-field Communications with Ultra-low Overhead
Apr 27, 2025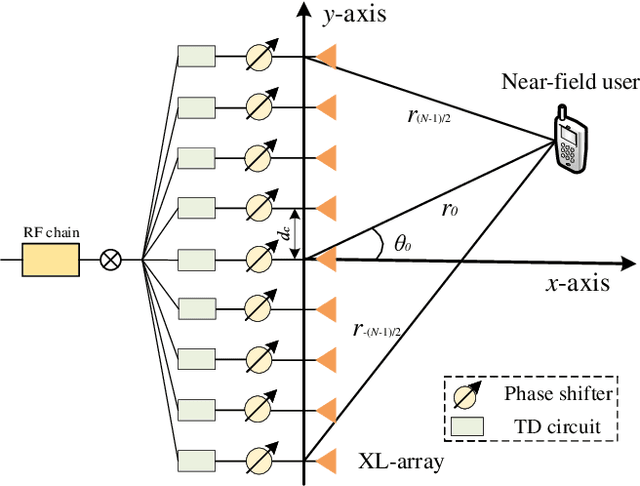
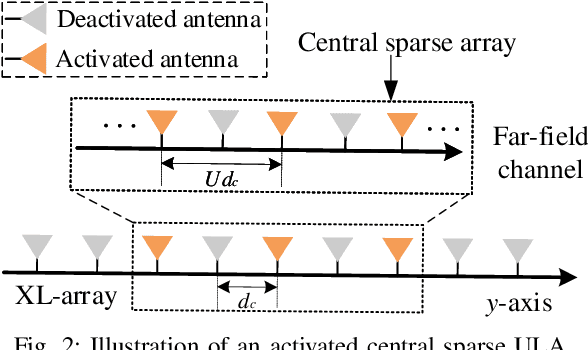
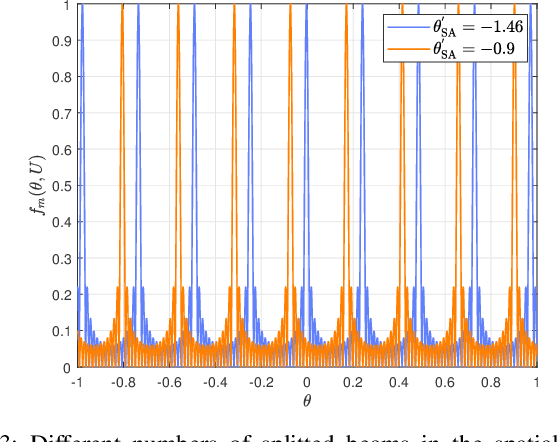
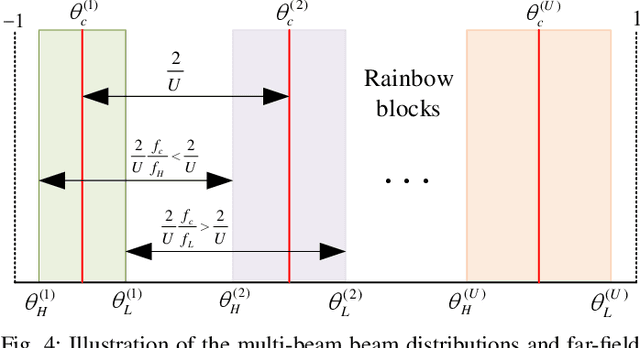
In this paper, we propose a super-resolution wideband beam training method for near-field communications, which is able to achieve ultra-low overhead. To this end, we first study the multi-beam characteristic of a sparse uniform linear array (S-ULA) in the wideband. Interestingly, we show that this leads to a new beam pattern property, called rainbow blocks, where the S-ULA generates multiple grating lobes and each grating lobe is further splitted into multiple versions in the wideband due to the well-known beam-split effect. As such, one directional beamformer based on S-ULA is capable of generating multiple rainbow blocks in the wideband, hence significantly extending the beam coverage. Then, by exploiting the beam-split effect in both the frequency and spatial domains, we propose a new three-stage wideband beam training method for extremely large-scale array (XL-array) systems. Specifically, we first sparsely activate a set of antennas at the central of the XL-array and judiciously design the time-delay (TD) parameters to estimate candidate user angles by comparing the received signal powers at the user over subcarriers. Next, to resolve the angular ambiguity introduced by the S-ULA, we activate all antennas in the central subarray and design an efficient subcarrier selection scheme to estimate the true user angle. In the third stage, we resolve the user range at the estimated user angle with high resolution by controlling the splitted beams over subcarriers to simultaneously cover the range domain. Finally, numerical results are provided to demonstrate the effectiveness of proposed wideband beam training scheme, which only needs three pilots in near-field beam training, while achieving near-optimal rate performance.
Mixed Near-field and Far-field Target Localization for Low-altitude Economy
Mar 06, 2025In this paper, we study efficient mixed near-field and far-field target localization methods for low-altitude economy, by capitalizing on extremely large-scale multiple-input multiple-output (XL-MIMO) communication systems. Compared with existing works, we address three new challenges in localization, arising from 1) half-wavelength antenna spacing constraint, 2) hybrid uniform planar array (UPA) architecture, and 3) incorrect mixed-field target classification for near-field targets.To address these issues, we propose a new three-step mixed-field localization method.First, we reconstruct the signals received at UPA antennas by judiciously designing analog combining matrices over time with minimum recovery errors, thus tackling the reduced-dimensional signal-space issue in hybrid arrays.Second, based on recovered signals, we devise a modified MUSIC algorithm (catered to UPA architecture) to estimate 2D angular parameters of both far- and near-field targets. Due to half-wavelength inter-antenna spacing, there exist ambiguous angles when estimating true angles of targets.In the third step, we design an effective classification method to distinguish mixed-field targets, determine true angles of all targets, as well as estimate the ranges of near-field targets. In particular, angular ambiguity is resolved by showing an important fact that the three types of estimated angles (i.e., far-field, near-field, and ambiguous angles) exhibit significantly different patterns in the range-domain MUSIC spectrum. Furthermore, to characterize the estimation error lower-bound, we obtain a matrix closed-form Cram\'er-Rao bounds for mixed-field target localization. Finally, numerical results demonstrate the effectiveness of our proposed mixed-field localization method, which improves target-classification accuracy and achieves a lower root mean square error than various benchmark schemes.
Hybrid Beamforming Design for RSMA-enabled Near-Field Integrated Sensing and Communications
Dec 22, 2024



To enable high data rates and sensing resolutions, integrated sensing and communication (ISAC) networks leverage extremely large antenna arrays and high frequencies, extending the Rayleigh distance and making near-field (NF) spherical wave propagation dominant. This unlocks numerous spatial degrees of freedom, raising the challenge of optimizing them for communication and sensing tradeoffs. To this end, we propose a rate-splitting multiple access (RSMA)-based NF-ISAC transmit scheme utilizing hybrid digital-analog antennas. RSMA enhances interference management, while a variable number of dedicated sensing beams adds beamforming flexibility. The objective is to maximize the minimum communication rate while ensuring multi-target sensing performance by jointly optimizing receive filters, analog and digital beamformers, common rate allocation, and the sensing beam count. To address uncertainty in sensing beam allocation, a rank-zero solution reconstruction method demonstrates that dedicated sensing beams are unnecessary for NF multi-target detection. A penalty dual decomposition (PDD)-based double-loop algorithm is introduced, employing weighted minimum mean-squared error (WMMSE) and quadratic transforms to reformulate communication and sensing rates. Simulations reveal that the proposed scheme: 1) Achieves performance comparable to fully digital beamforming with fewer RF chains, (2) Maintains NF multi-target detection without compromising communication rates, and 3) Significantly outperforms space division multiple access (SDMA) and far-field ISAC systems.
Flexible Rate-Splitting Multiple Access for Near-Field Integrated Sensing and Communications
Dec 01, 2024


This letter presents a flexible rate-splitting multiple access (RSMA) framework for near-field (NF) integrated sensing and communications (ISAC). The spatial beams configured to meet the communication rate requirements of NF users are simultaneously leveraged to sense an additional NF target. A key innovation lies in its flexibility to select a subset of users for decoding the common stream, enhancing interference management and system performance. The system is designed by minimizing the Cram\'{e}r-Rao bound (CRB) for joint distance and angle estimation through optimized power allocation, common rate allocation, and user selection. This leads to a discrete, non-convex optimization problem. Remarkably, we demonstrate that the preconfigured beams are sufficient for target sensing, eliminating the need for additional probing signals. To solve the optimization problem, an iterative algorithm is proposed combining the quadratic transform and simulated annealing. Simulation results indicate that the proposed scheme significantly outperforms conventional RSMA and space division multiple access (SDMA), reducing distance and angle estimation errors by approximately 100\% and 20\%, respectively.