 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Fluid Antenna Arrays: Continuous Position Design Beyond Classical DOF Limits
May 19, 2026Fluid antenna system (FAS), which continuously repositions a single physical element across a deployment region $[0, D]$, breaks this limit by freeing antenna positions from the discrete grid entirely. This paper establishes the theoretical foundations of sparse FAS design for direction-of-arrival (DOA) estimation and shows that continuous position freedom unlocks three compounding advantages over the classical designs. \emph{First}, we derive a universal dual DOF bound and prove that FAS-optimized positions can approach it, growing the DOF linearly with $D/λ$ , where $λ$ is the signal wavelength, rather than saturating at $O(N^2)$. \emph{Second}, the CRB scales as $O(1/D^{2L})$ for $L$ sources, a $(D/(N^2 d_0))^{2L}$ improvement over the best grid design, with $d_0 = λ/2$ and D-optimal positions admitting closed-form solution for single sources and efficient Frank-Wolfe algorithm for multiple sources. \emph{Third}, we propose a two-stage FAS-MUSIC approach that combines coarray MUSIC disambiguation with full-aperture local maximum likelihood (ML) refinement to track the CRB, overcoming the grating-lobe ambiguity inherent in large-aperture non-uniform arrays. Robustness to minimum spacing constraints, mutual coupling, and finite position accuracy is also analyzed. Extensive simulations show that FAS-MUSIC achieves $17.5\times$ lower root mean squared error (RMSE) than uniform linear array (ULA) MUSIC and that FAS with $4$ antennas outperforms MRA with $8$ antennas, gains that are unattainable by any grid-constrained design.
MolCrystalFlow: Molecular Crystal Structure Prediction via Flow Matching
Feb 17, 2026Molecular crystal structure prediction represents a grand challenge in computational chemistry due to large sizes of constituent molecules and complex intra- and intermolecular interactions. While generative modeling has revolutionized structure discovery for molecules, inorganic solids, and metal-organic frameworks, extending such approaches to fully periodic molecular crystals is still elusive. Here, we present MolCrystalFlow, a flow-based generative model for molecular crystal structure prediction. The framework disentangles intramolecular complexity from intermolecular packing by embedding molecules as rigid bodies and jointly learning the lattice matrix, molecular orientations, and centroid positions. Centroids and orientations are represented on their native Riemannian manifolds, allowing geodesic flow construction and graph neural network operations that respects geometric symmetries. We benchmark our model against state-of-the-art generative models for large-size periodic crystals and rule-based structure generation methods on two open-source molecular crystal datasets. We demonstrate an integration of MolCrystalFlow model with universal machine learning potential to accelerate molecular crystal structure prediction, paving the way for data-driven generative discovery of molecular crystals.
MolGuidance: Advanced Guidance Strategies for Conditional Molecular Generation with Flow Matching
Dec 13, 2025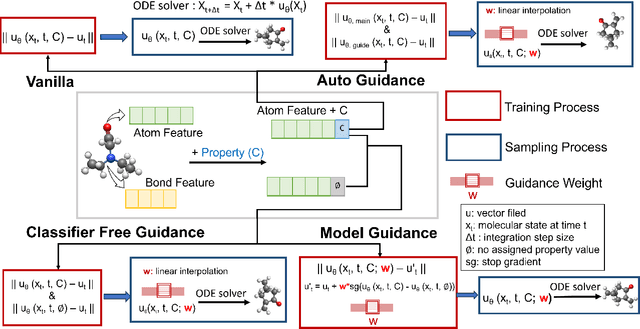

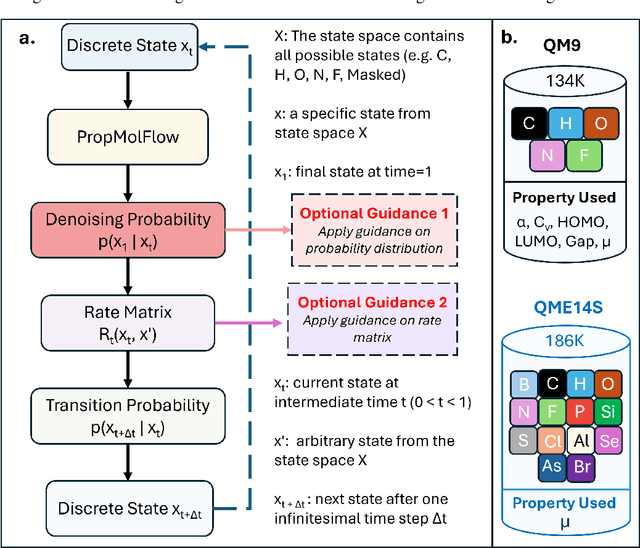
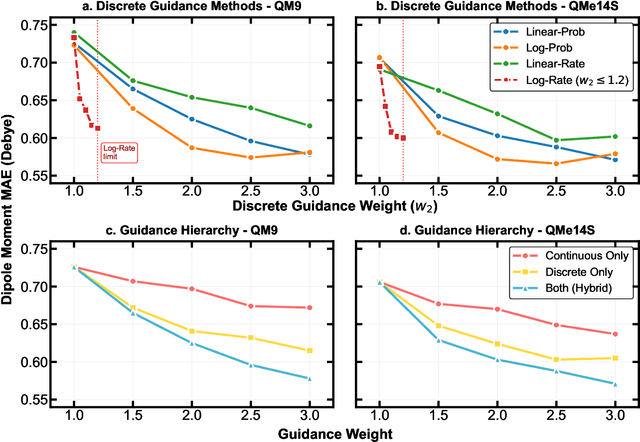
Key objectives in conditional molecular generation include ensuring chemical validity, aligning generated molecules with target properties, promoting structural diversity, and enabling efficient sampling for discovery. Recent advances in computer vision introduced a range of new guidance strategies for generative models, many of which can be adapted to support these goals. In this work, we integrate state-of-the-art guidance methods -- including classifier-free guidance, autoguidance, and model guidance -- in a leading molecule generation framework built on an SE(3)-equivariant flow matching process. We propose a hybrid guidance strategy that separately guides continuous and discrete molecular modalities -- operating on velocity fields and predicted logits, respectively -- while jointly optimizing their guidance scales via Bayesian optimization. Our implementation, benchmarked on the QM9 and QMe14S datasets, achieves new state-of-the-art performance in property alignment for de novo molecular generation. The generated molecules also exhibit high structural validity. Furthermore, we systematically compare the strengths and limitations of various guidance methods, offering insights into their broader applicability.
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.
SPPSFormer: High-quality Superpoint-based Transformer for Roof Plane Instance Segmentation from Point Clouds
May 30, 2025



Transformers have been seldom employed in point cloud roof plane instance segmentation, which is the focus of this study, and existing superpoint Transformers suffer from limited performance due to the use of low-quality superpoints. To address this challenge, we establish two criteria that high-quality superpoints for Transformers should satisfy and introduce a corresponding two-stage superpoint generation process. The superpoints generated by our method not only have accurate boundaries, but also exhibit consistent geometric sizes and shapes, both of which greatly benefit the feature learning of superpoint Transformers. To compensate for the limitations of deep learning features when the training set size is limited, we incorporate multidimensional handcrafted features into the model. Additionally, we design a decoder that combines a Kolmogorov-Arnold Network with a Transformer module to improve instance prediction and mask extraction. Finally, our network's predictions are refined using traditional algorithm-based postprocessing. For evaluation, we annotated a real-world dataset and corrected annotation errors in the existing RoofN3D dataset. Experimental results show that our method achieves state-of-the-art performance on our dataset, as well as both the original and reannotated RoofN3D datasets. Moreover, our model is not sensitive to plane boundary annotations during training, significantly reducing the annotation burden. Through comprehensive experiments, we also identified key factors influencing roof plane segmentation performance: in addition to roof types, variations in point cloud density, density uniformity, and 3D point precision have a considerable impact. These findings underscore the importance of incorporating data augmentation strategies that account for point cloud quality to enhance model robustness under diverse and challenging conditions.
OViP: Online Vision-Language Preference Learning
May 21, 2025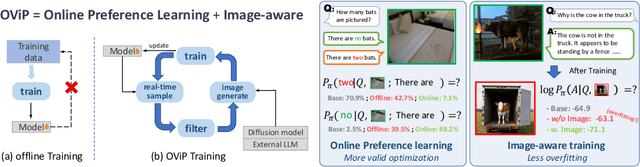
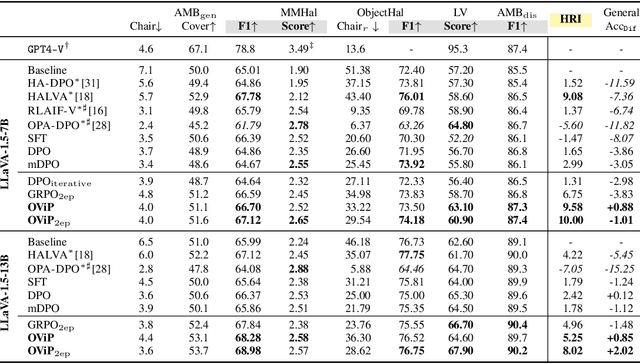
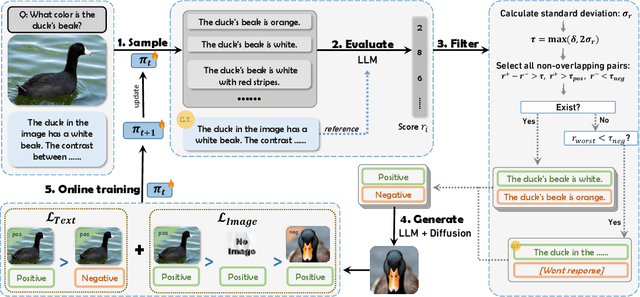

Large vision-language models (LVLMs) remain vulnerable to hallucination, often generating content misaligned with visual inputs. While recent approaches advance multi-modal Direct Preference Optimization (DPO) to mitigate hallucination, they typically rely on predefined or randomly edited negative samples that fail to reflect actual model errors, limiting training efficacy. In this work, we propose an Online Vision-language Preference Learning (OViP) framework that dynamically constructs contrastive training data based on the model's own hallucinated outputs. By identifying semantic differences between sampled response pairs and synthesizing negative images using a diffusion model, OViP generates more relevant supervision signals in real time. This failure-driven training enables adaptive alignment of both textual and visual preferences. Moreover, we refine existing evaluation protocols to better capture the trade-off between hallucination suppression and expressiveness. Experiments on hallucination and general benchmarks demonstrate that OViP effectively reduces hallucinations while preserving core multi-modal capabilities.
NTP-INT: Network Traffic Prediction-Driven In-band Network Telemetry for High-load Switches
Feb 18, 2025



In-band network telemetry (INT) is essential to network management due to its real-time visibility. However, because of the rapid increase in network devices and services, it has become crucial to have targeted access to detailed network information in a dynamic network environment. This paper proposes an intelligent network telemetry system called NTP-INT to obtain more fine-grained network information on high-load switches. Specifically, NTP-INT consists of three modules: network traffic prediction module, network pruning module, and probe path planning module. Firstly, the network traffic prediction module adopts a Multi-Temporal Graph Neural Network (MTGNN) to predict future network traffic and identify high-load switches. Then, we design the network pruning algorithm to generate a subnetwork covering all high-load switches to reduce the complexity of probe path planning. Finally, the probe path planning module uses an attention-mechanism-based deep reinforcement learning (DEL) model to plan efficient probe paths in the network slice. The experimental results demonstrate that NTP-INT can acquire more precise network information on high-load switches while decreasing the control overhead by 50\%.
Flat U-Net: An Efficient Ultralightweight Model for Solar Filament Segmentation in Full-disk H$α$ Images
Feb 11, 2025Solar filaments are one of the most prominent features observed on the Sun, and their evolutions are closely related to various solar activities, such as flares and coronal mass ejections. Real-time automated identification of solar filaments is the most effective approach to managing large volumes of data. Existing models of filament identification are characterized by large parameter sizes and high computational costs, which limit their future applications in highly integrated and intelligent ground-based and space-borne observation devices. Consequently, the design of more lightweight models will facilitate the advancement of intelligent observation equipment. In this study, we introduce Flat U-Net, a novel and highly efficient ultralightweight model that incorporates simplified channel attention (SCA) and channel self-attention (CSA) convolutional blocks for the segmentation of solar filaments in full-disk H$\alpha$ images. Feature information from each network layer is fully extracted to reconstruct interchannel feature representations. Each block effectively optimizes the channel features from the previous layer, significantly reducing parameters. The network architecture presents an elegant flattening, improving its efficiency, and simplifying the overall design. Experimental validation demonstrates that a model composed of pure SCAs achieves a precision of approximately 0.93, with dice similarity coefficient (DSC) and recall rates of 0.76 and 0.64, respectively, significantly outperforming the classical U-Net. Introducing a certain number of CSA blocks improves the DSC and recall rates to 0.82 and 0.74, respectively, which demonstrates a pronounced advantage, particularly concerning model weight size and detection effectiveness. The data set, models, and code are available as open-source resources.
Flexible Rate-Splitting Multiple Access for Near-Field Integrated Sensing and Communications
Dec 01, 2024


This letter presents a flexible rate-splitting multiple access (RSMA) framework for near-field (NF) integrated sensing and communications (ISAC). The spatial beams configured to meet the communication rate requirements of NF users are simultaneously leveraged to sense an additional NF target. A key innovation lies in its flexibility to select a subset of users for decoding the common stream, enhancing interference management and system performance. The system is designed by minimizing the Cram\'{e}r-Rao bound (CRB) for joint distance and angle estimation through optimized power allocation, common rate allocation, and user selection. This leads to a discrete, non-convex optimization problem. Remarkably, we demonstrate that the preconfigured beams are sufficient for target sensing, eliminating the need for additional probing signals. To solve the optimization problem, an iterative algorithm is proposed combining the quadratic transform and simulated annealing. Simulation results indicate that the proposed scheme significantly outperforms conventional RSMA and space division multiple access (SDMA), reducing distance and angle estimation errors by approximately 100\% and 20\%, respectively.
PlaneSAM: Multimodal Plane Instance Segmentation Using the Segment Anything Model
Oct 21, 2024



Plane instance segmentation from RGB-D data is a crucial research topic for many downstream tasks. However, most existing deep-learning-based methods utilize only information within the RGB bands, neglecting the important role of the depth band in plane instance segmentation. Based on EfficientSAM, a fast version of SAM, we propose a plane instance segmentation network called PlaneSAM, which can fully integrate the information of the RGB bands (spectral bands) and the D band (geometric band), thereby improving the effectiveness of plane instance segmentation in a multimodal manner. Specifically, we use a dual-complexity backbone, with primarily the simpler branch learning D-band features and primarily the more complex branch learning RGB-band features. Consequently, the backbone can effectively learn D-band feature representations even when D-band training data is limited in scale, retain the powerful RGB-band feature representations of EfficientSAM, and allow the original backbone branch to be fine-tuned for the current task. To enhance the adaptability of our PlaneSAM to the RGB-D domain, we pretrain our dual-complexity backbone using the segment anything task on large-scale RGB-D data through a self-supervised pretraining strategy based on imperfect pseudo-labels. To support the segmentation of large planes, we optimize the loss function combination ratio of EfficientSAM. In addition, Faster R-CNN is used as a plane detector, and its predicted bounding boxes are fed into our dual-complexity network as prompts, thereby enabling fully automatic plane instance segmentation. Experimental results show that the proposed PlaneSAM sets a new SOTA performance on the ScanNet dataset, and outperforms previous SOTA approaches in zero-shot transfer on the 2D-3D-S, Matterport3D, and ICL-NUIM RGB-D datasets, while only incurring a 10% increase in computational overhead compared to EfficientSAM.