 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIScholarBench: Benchmarking LLM Overconfidence in GIS Research
Jun 06, 2026Large language models (LLMs) are increasingly used in academic research workflows, but scholarly tasks require high factual precision and therefore expose a key weakness: overconfidence. Here, overconfidence is defined behaviorally as the tendency to produce confident, assertive, and well-formatted outputs even when the underlying knowledge is incomplete or unverifiable, rather than as a calibration gap between stated confidence and accuracy. To examine this issue, we introduce GIScholarBench, a benchmark built from 10,865 papers published in 25 core GIScience journals between 2020 and 2025. The benchmark covers three tasks with increasing cognitive complexity: metadata retrieval, literature linking, and research direction generation. We evaluate Claude Sonnet 4.5, Gemini 3, and ChatGPT 5.3 through their native web interfaces under real-world user-facing conditions. Results show consistent overconfidence across all tasks. In metadata retrieval, ChatGPT 5.3 achieves the highest accuracy, but all models still generate definitive titles and DOIs when predictions are wrong. In literature linking, Claude Sonnet 4.5 recovers the most references, but all models show a clear gap between top-ranked retrieval and longer citation lists, suggesting that references are extended beyond reliable retrieval capacity. In research direction generation, AI-generated directions show lower topic coverage, higher novel miss rates, and lower semantic diversity than real future-citing papers. These findings suggest that LLM overconfidence is task-invariant but takes different forms: factual overgeneration in retrieval, unreliable citation expansion in literature linking, and overconfidence in output completeness during research ideation.
Satellite-to-Street: Synthesizing Post-Disaster Views from Satellite Imagery via Generative Vision Models
Mar 21, 2026In the immediate aftermath of natural disasters, rapid situational awareness is critical. Traditionally, satellite observations are widely used to estimate damage extent. However, they lack the ground-level perspective essential for characterizing specific structural failures and impacts. Meanwhile, ground-level data (e.g., street-view imagery) remains largely inaccessible during time-sensitive events. This study investigates Satellite-to-Street View Synthesis to bridge this data gap. We introduce two generative strategies to synthesize post-disaster street views from satellite imagery: a Vision-Language Model (VLM)-guided approach and a damage-sensitive Mixture-of-Experts (MoE) method. We benchmark these against general-purpose baselines (Pix2Pix, ControlNet) using a proposed Structure-Aware Evaluation Framework. This multi-tier protocol integrates (1) pixel-level quality assessment, (2) ResNet-based semantic consistency verification, and (3) a novel VLM-as-a-Judge for perceptual alignment. Experiments on 300 disaster scenarios reveal a critical realism--fidelity trade-off: while diffusion-based approaches (e.g., ControlNet) achieve high perceptual realism, they often hallucinate structural details. Quantitative results show that standard ControlNet achieves the highest semantic accuracy, 0.71, whereas VLM-enhanced and MoE models excel in textural plausibility but struggle with semantic clarity. This work establishes a baseline for trustworthy cross-view synthesis, emphasizing that visually realistic generations may still fail to preserve critical structural information required for reliable disaster assessment.
DamageArbiter: A CLIP-Enhanced Multimodal Arbitration Framework for Hurricane Damage Assessment from Street-View Imagery
Mar 16, 2026Analyzing street-view imagery with computer vision models for rapid, hyperlocal damage assessment is becoming popular and valuable in emergency response and recovery, but traditional models often act like black boxes, lacking interpretability and reliability. This study proposes a multimodal disagreement-driven Arbitration framework powered by Contrastive Language-Image Pre-training (CLIP) models, DamageArbiter, to improve the accuracy, interpretability, and robustness of damage estimation from street-view imagery. DamageArbiter leverages the complementary strengths of unimodal and multimodal models, employing a lightweight logistic regression meta-classifier to arbitrate cases of disagreement. Using 2,556 post-disaster street-view images, paired with both manually generated and large language model (LLM)-generated text descriptions, we systematically compared the performance of unimodal models (including image-only and text-only models), multimodal CLIP-based models, and DamageArbiter. Notably, DamageArbiter improved the accuracy from 74.33% (ViT-B/32, image-only) to 82.79%, surpassing the 80% accuracy threshold and achieving an absolute improvement of 8.46% compared to the strongest baseline model. Beyond improvements in overall accuracy, compared to visual models relying solely on images, DamageArbiter, through arbitration of discrepancies between unimodal and multimodal predictions, mitigates common overconfidence errors in visual models, especially in situations where disaster visual cues are ambiguous or subject to interference, reducing overconfidence but incorrect predictions. We further mapped and analyzed geo-referenced predictions and misclassifications to compare model performance across locations. Overall, this work advances street-view-based disaster assessment from coarse severity classification toward a more reliable and interpretable framework.
Towards Effective and Efficient Graph Alignment without Supervision
Mar 09, 2026Unsupervised graph alignment aims to find the node correspondence across different graphs without any anchor node pairs. Despite the recent efforts utilizing deep learning-based techniques, such as the embedding and optimal transport (OT)-based approaches, we observe their limitations in terms of model accuracy-efficiency tradeoff. By focusing on the exploitation of local and global graph information, we formalize them as the ``local representation, global alignment'' paradigm, and present a new ``global representation and alignment'' paradigm to resolve the mismatch between the two phases in the alignment process. We then propose \underline{Gl}obal representation and \underline{o}ptimal transport-\underline{b}ased \underline{Align}ment (\texttt{GlobAlign}), and its variant, \texttt{GlobAlign-E}, for better \underline{E}fficiency. Our methods are equipped with the global attention mechanism and a hierarchical cross-graph transport cost, able to capture long-range and implicit node dependencies beyond the local graph structure. Furthermore, \texttt{GlobAlign-E} successfully closes the time complexity gap between representative embedding and OT-based methods, reducing OT's cubic complexity to quadratic terms. Through extensive experiments, our methods demonstrate superior performance, with up to a 20\% accuracy improvement over the best competitor. Meanwhile, \texttt{GlobAlign-E} achieves the best efficiency, with an order of magnitude speedup against existing OT-based methods.
Predicting Healthcare System Visitation Flow by Integrating Hospital Attributes and Population Socioeconomics with Human Mobility Data
Jan 22, 2026Healthcare visitation patterns are influenced by a complex interplay of hospital attributes, population socioeconomics, and spatial factors. However, existing research often adopts a fragmented approach, examining these determinants in isolation. This study addresses this gap by integrating hospital capacities, occupancy rates, reputation, and popularity with population SES and spatial mobility patterns to predict visitation flows and analyze influencing factors. Utilizing four years of SafeGraph mobility data and user experience data from Google Maps Reviews, five flow prediction models, Naive Regression, Gradient Boosting, Multilayer Perceptrons (MLPs), Deep Gravity, and Heterogeneous Graph Neural Networks (HGNN),were trained and applied to simulate visitation flows in Houston, Texas, U.S. The Shapley additive explanation (SHAP) analysis and the Partial Dependence Plot (PDP) method were employed to examine the combined impacts of different factors on visitation patterns. The findings reveal that Deep Gravity outperformed other models. Hospital capacities, ICU occupancy rates, ratings, and popularity significantly influence visitation patterns, with their effects varying across different travel distances. Short-distance visits are primarily driven by convenience, whereas long-distance visits are influenced by hospital ratings. White-majority areas exhibited lower sensitivity to hospital ratings for short-distance visits, while Asian populations and those with higher education levels prioritized hospital rating in their visitation decisions. SES further influence these patterns, as areas with higher proportions of Hispanic, Black, under-18, and over-65 populations tend to have more frequent hospital visits, potentially reflecting greater healthcare needs or limited access to alternative medical services.
Does Memory Need Graphs? A Unified Framework and Empirical Analysis for Long-Term Dialog Memory
Jan 07, 2026Graph structures are increasingly used in dialog memory systems, but empirical findings on their effectiveness remain inconsistent, making it unclear which design choices truly matter. We present an experimental, system-oriented analysis of long-term dialog memory architectures. We introduce a unified framework that decomposes dialog memory systems into core components and supports both graph-based and non-graph approaches. Under this framework, we conduct controlled, stage-wise experiments on LongMemEval and HaluMem, comparing common design choices in memory representation, organization, maintenance, and retrieval. Our results show that many performance differences are driven by foundational system settings rather than specific architectural innovations. Based on these findings, we identify stable and reliable strong baselines for future dialog memory research.
Detecting Hallucinations in Retrieval-Augmented Generation via Semantic-level Internal Reasoning Graph
Jan 06, 2026The Retrieval-augmented generation (RAG) system based on Large language model (LLM) has made significant progress. It can effectively reduce factuality hallucinations, but faithfulness hallucinations still exist. Previous methods for detecting faithfulness hallucinations either neglect to capture the models' internal reasoning processes or handle those features coarsely, making it difficult for discriminators to learn. This paper proposes a semantic-level internal reasoning graph-based method for detecting faithfulness hallucination. Specifically, we first extend the layer-wise relevance propagation algorithm from the token level to the semantic level, constructing an internal reasoning graph based on attribution vectors. This provides a more faithful semantic-level representation of dependency. Furthermore, we design a general framework based on a small pre-trained language model to utilize the dependencies in LLM's reasoning for training and hallucination detection, which can dynamically adjust the pass rate of correct samples through a threshold. Experimental results demonstrate that our method achieves better overall performance compared to state-of-the-art baselines on RAGTruth and Dolly-15k.
GILT: An LLM-Free, Tuning-Free Graph Foundational Model for In-Context Learning
Oct 06, 2025Graph Neural Networks (GNNs) are powerful tools for precessing relational data but often struggle to generalize to unseen graphs, giving rise to the development of Graph Foundational Models (GFMs). However, current GFMs are challenged by the extreme heterogeneity of graph data, where each graph can possess a unique feature space, label set, and topology. To address this, two main paradigms have emerged. The first leverages Large Language Models (LLMs), but is fundamentally text-dependent, thus struggles to handle the numerical features in vast graphs. The second pre-trains a structure-based model, but the adaptation to new tasks typically requires a costly, per-graph tuning stage, creating a critical efficiency bottleneck. In this work, we move beyond these limitations and introduce \textbf{G}raph \textbf{I}n-context \textbf{L}earning \textbf{T}ransformer (GILT), a framework built on an LLM-free and tuning-free architecture. GILT introduces a novel token-based framework for in-context learning (ICL) on graphs, reframing classification tasks spanning node, edge and graph levels in a unified framework. This mechanism is the key to handling heterogeneity, as it is designed to operate on generic numerical features. Further, its ability to understand class semantics dynamically from the context enables tuning-free adaptation. Comprehensive experiments show that GILT achieves stronger few-shot performance with significantly less time than LLM-based or tuning-based baselines, validating the effectiveness of our approach.
GAP: Graph-Assisted Prompts for Dialogue-based Medication Recommendation
May 19, 2025Medication recommendations have become an important task in the healthcare domain, especially in measuring the accuracy and safety of medical dialogue systems (MDS). Different from the recommendation task based on electronic health records (EHRs), dialogue-based medication recommendations require research on the interaction details between patients and doctors, which is crucial but may not exist in EHRs. Recent advancements in large language models (LLM) have extended the medical dialogue domain. These LLMs can interpret patients' intent and provide medical suggestions including medication recommendations, but some challenges are still worth attention. During a multi-turn dialogue, LLMs may ignore the fine-grained medical information or connections across the dialogue turns, which is vital for providing accurate suggestions. Besides, LLMs may generate non-factual responses when there is a lack of domain-specific knowledge, which is more risky in the medical domain. To address these challenges, we propose a \textbf{G}raph-\textbf{A}ssisted \textbf{P}rompts (\textbf{GAP}) framework for dialogue-based medication recommendation. It extracts medical concepts and corresponding states from dialogue to construct an explicitly patient-centric graph, which can describe the neglected but important information. Further, combined with external medical knowledge graphs, GAP can generate abundant queries and prompts, thus retrieving information from multiple sources to reduce the non-factual responses. We evaluate GAP on a dialogue-based medication recommendation dataset and further explore its potential in a more difficult scenario, dynamically diagnostic interviewing. Extensive experiments demonstrate its competitive performance when compared with strong baselines.
Hyperlocal disaster damage assessment using bi-temporal street-view imagery and pre-trained vision models
Apr 12, 2025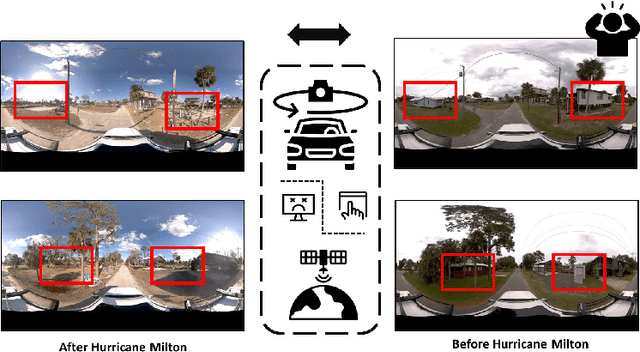
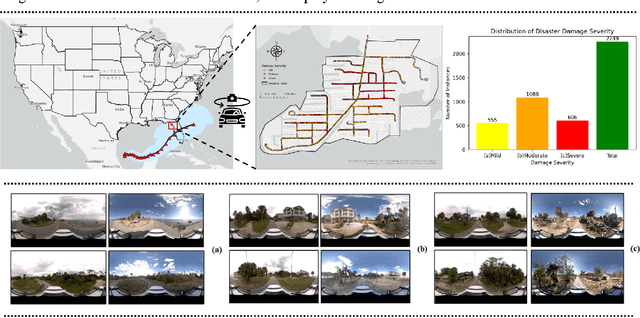
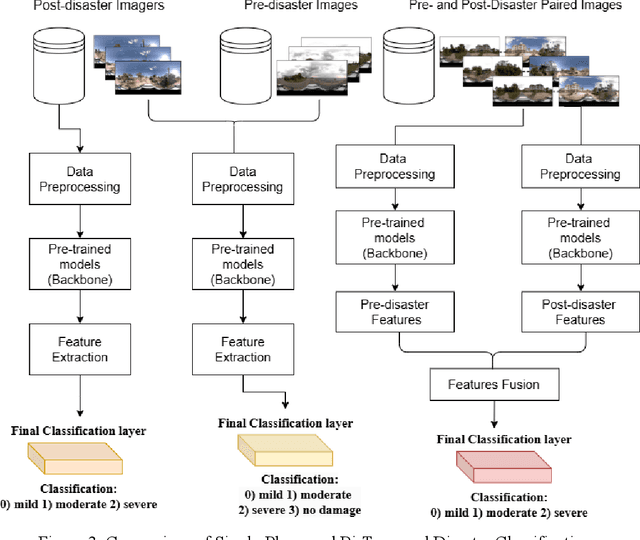
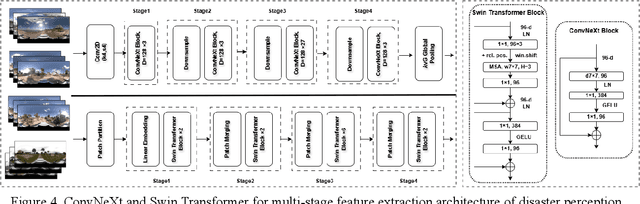
Street-view images offer unique advantages for disaster damage estimation as they capture impacts from a visual perspective and provide detailed, on-the-ground insights. Despite several investigations attempting to analyze street-view images for damage estimation, they mainly focus on post-disaster images. The potential of time-series street-view images remains underexplored. Pre-disaster images provide valuable benchmarks for accurate damage estimations at building and street levels. These images could aid annotators in objectively labeling post-disaster impacts, improving the reliability of labeled data sets for model training, and potentially enhancing the model performance in damage evaluation. The goal of this study is to estimate hyperlocal, on-the-ground disaster damages using bi-temporal street-view images and advanced pre-trained vision models. Street-view images before and after 2024 Hurricane Milton in Horseshoe Beach, Florida, were collected for experiments. The objectives are: (1) to assess the performance gains of incorporating pre-disaster street-view images as a no-damage category in fine-tuning pre-trained models, including Swin Transformer and ConvNeXt, for damage level classification; (2) to design and evaluate a dual-channel algorithm that reads pair-wise pre- and post-disaster street-view images for hyperlocal damage assessment. The results indicate that incorporating pre-disaster street-view images and employing a dual-channel processing framework can significantly enhance damage assessment accuracy. The accuracy improves from 66.14% with the Swin Transformer baseline to 77.11% with the dual-channel Feature-Fusion ConvNeXt model. This research enables rapid, operational damage assessments at hyperlocal spatial resolutions, providing valuable insights to support effective decision-making in disaster management and resilience planning.