 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInCoder-32B-Thinking: Industrial Code World Model for Thinking
Apr 03, 2026Industrial software development across chip design, GPU optimization, and embedded systems lacks expert reasoning traces showing how engineers reason about hardware constraints and timing semantics. In this work, we propose InCoder-32B-Thinking, trained on the data from the Error-driven Chain-of-Thought (ECoT) synthesis framework with an industrial code world model (ICWM) to generate reasoning traces. Specifically, ECoT generates reasoning chains by synthesizing the thinking content from multi-turn dialogue with environmental error feedback, explicitly modeling the error-correction process. ICWM is trained on domain-specific execution traces from Verilog simulation, GPU profiling, etc., learns the causal dynamics of how code affects hardware behavior, and enables self-verification by predicting execution outcomes before actual compilation. All synthesized reasoning traces are validated through domain toolchains, creating training data matching the natural reasoning depth distribution of industrial tasks. Evaluation on 14 general (81.3% on LiveCodeBench v5) and 9 industrial benchmarks (84.0% in CAD-Coder and 38.0% on KernelBench) shows InCoder-32B-Thinking achieves top-tier open-source results across all domains.GPU Optimization
InCoder-32B: Code Foundation Model for Industrial Scenarios
Mar 17, 2026Recent code large language models have achieved remarkable progress on general programming tasks. Nevertheless, their performance degrades significantly in industrial scenarios that require reasoning about hardware semantics, specialized language constructs, and strict resource constraints. To address these challenges, we introduce InCoder-32B (Industrial-Coder-32B), the first 32B-parameter code foundation model unifying code intelligence across chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling. By adopting an efficient architecture, we train InCoder-32B from scratch with general code pre-training, curated industrial code annealing, mid-training that progressively extends context from 8K to 128K tokens with synthetic industrial reasoning data, and post-training with execution-grounded verification. We conduct extensive evaluation on 14 mainstream general code benchmarks and 9 industrial benchmarks spanning 4 specialized domains. Results show InCoder-32B achieves highly competitive performance on general tasks while establishing strong open-source baselines across industrial domains.
Scalable and General Whole-Body Control for Cross-Humanoid Locomotion
Feb 05, 2026Learning-based whole-body controllers have become a key driver for humanoid robots, yet most existing approaches require robot-specific training. In this paper, we study the problem of cross-embodiment humanoid control and show that a single policy can robustly generalize across a wide range of humanoid robot designs with one-time training. We introduce XHugWBC, a novel cross-embodiment training framework that enables generalist humanoid control through: (1) physics-consistent morphological randomization, (2) semantically aligned observation and action spaces across diverse humanoid robots, and (3) effective policy architectures modeling morphological and dynamical properties. XHugWBC is not tied to any specific robot. Instead, it internalizes a broad distribution of morphological and dynamical characteristics during training. By learning motion priors from diverse randomized embodiments, the policy acquires a strong structural bias that supports zero-shot transfer to previously unseen robots. Experiments on twelve simulated humanoids and seven real-world robots demonstrate the strong generalization and robustness of the resulting universal controller.
RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing
Jan 30, 2026Achieving human-level competitive intelligence and physical agility in humanoid robots remains a major challenge, particularly in contact-rich and highly dynamic tasks such as boxing. While Multi-Agent Reinforcement Learning (MARL) offers a principled framework for strategic interaction, its direct application to humanoid control is hindered by high-dimensional contact dynamics and the absence of strong physical motion priors. We propose RoboStriker, a hierarchical three-stage framework that enables fully autonomous humanoid boxing by decoupling high-level strategic reasoning from low-level physical execution. The framework first learns a comprehensive repertoire of boxing skills by training a single-agent motion tracker on human motion capture data. These skills are subsequently distilled into a structured latent manifold, regularized by projecting the Gaussian-parameterized distribution onto a unit hypersphere. This topological constraint effectively confines exploration to the subspace of physically plausible motions. In the final stage, we introduce Latent-Space Neural Fictitious Self-Play (LS-NFSP), where competing agents learn competitive tactics by interacting within the latent action space rather than the raw motor space, significantly stabilizing multi-agent training. Experimental results demonstrate that RoboStriker achieves superior competitive performance in simulation and exhibits sim-to-real transfer. Our website is available at RoboStriker.
A Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning
Sep 19, 2025Robotic real-world reinforcement learning (RL) with vision-language-action (VLA) models is bottlenecked by sparse, handcrafted rewards and inefficient exploration. We introduce VLAC, a general process reward model built upon InternVL and trained on large scale heterogeneous datasets. Given pairwise observations and a language goal, it outputs dense progress delta and done signal, eliminating task-specific reward engineering, and supports one-shot in-context transfer to unseen tasks and environments. VLAC is trained on vision-language datasets to strengthen perception, dialogic and reasoning capabilities, together with robot and human trajectories data that ground action generation and progress estimation, and additionally strengthened to reject irrelevant prompts as well as detect regression or stagnation by constructing large numbers of negative and semantically mismatched samples. With prompt control, a single VLAC model alternately generating reward and action tokens, unifying critic and policy. Deployed inside an asynchronous real-world RL loop, we layer a graded human-in-the-loop protocol (offline demonstration replay, return and explore, human guided explore) that accelerates exploration and stabilizes early learning. Across four distinct real-world manipulation tasks, VLAC lifts success rates from about 30\% to about 90\% within 200 real-world interaction episodes; incorporating human-in-the-loop interventions yields a further 50% improvement in sample efficiency and achieves up to 100% final success.
DreamActor-H1: High-Fidelity Human-Product Demonstration Video Generation via Motion-designed Diffusion Transformers
Jun 12, 2025In e-commerce and digital marketing, generating high-fidelity human-product demonstration videos is important for effective product presentation. However, most existing frameworks either fail to preserve the identities of both humans and products or lack an understanding of human-product spatial relationships, leading to unrealistic representations and unnatural interactions. To address these challenges, we propose a Diffusion Transformer (DiT)-based framework. Our method simultaneously preserves human identities and product-specific details, such as logos and textures, by injecting paired human-product reference information and utilizing an additional masked cross-attention mechanism. We employ a 3D body mesh template and product bounding boxes to provide precise motion guidance, enabling intuitive alignment of hand gestures with product placements. Additionally, structured text encoding is used to incorporate category-level semantics, enhancing 3D consistency during small rotational changes across frames. Trained on a hybrid dataset with extensive data augmentation strategies, our approach outperforms state-of-the-art techniques in maintaining the identity integrity of both humans and products and generating realistic demonstration motions. Project page: https://submit2025-dream.github.io/DreamActor-H1/.
Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
Jun 10, 2025Autonomous agents powered by multimodal large language models have been developed to facilitate task execution on mobile devices. However, prior work has predominantly focused on atomic tasks -- such as shot-chain execution tasks and single-screen grounding tasks -- while overlooking the generalization to compositional tasks, which are indispensable for real-world applications. This work introduces UI-NEXUS, a comprehensive benchmark designed to evaluate mobile agents on three categories of compositional operations: Simple Concatenation, Context Transition, and Deep Dive. UI-NEXUS supports interactive evaluation in 20 fully controllable local utility app environments, as well as 30 online Chinese and English service apps. It comprises 100 interactive task templates with an average optimal step count of 14.05. Experimental results across a range of mobile agents with agentic workflow or agent-as-a-model show that UI-NEXUS presents significant challenges. Specifically, existing agents generally struggle to balance performance and efficiency, exhibiting representative failure modes such as under-execution, over-execution, and attention drift, causing visible atomic-to-compositional generalization gap. Inspired by these findings, we propose AGENT-NEXUS, a lightweight and efficient scheduling system to tackle compositional mobile tasks. AGENT-NEXUS extrapolates the abilities of existing mobile agents by dynamically decomposing long-horizon tasks to a series of self-contained atomic subtasks. AGENT-NEXUS achieves 24% to 40% task success rate improvement for existing mobile agents on compositional operation tasks within the UI-NEXUS benchmark without significantly sacrificing inference overhead. The demo video, dataset, and code are available on the project page at https://ui-nexus.github.io.
YH-MINER: Multimodal Intelligent System for Natural Ecological Reef Metric Extraction
May 29, 2025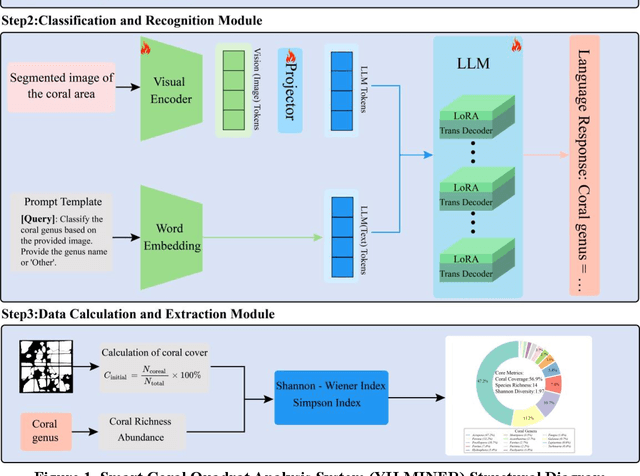
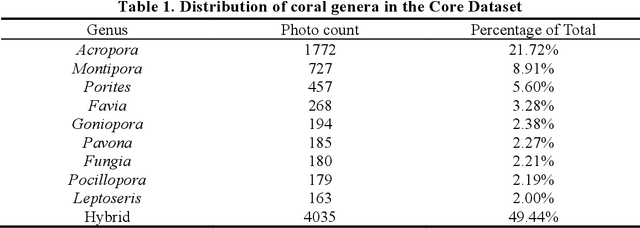
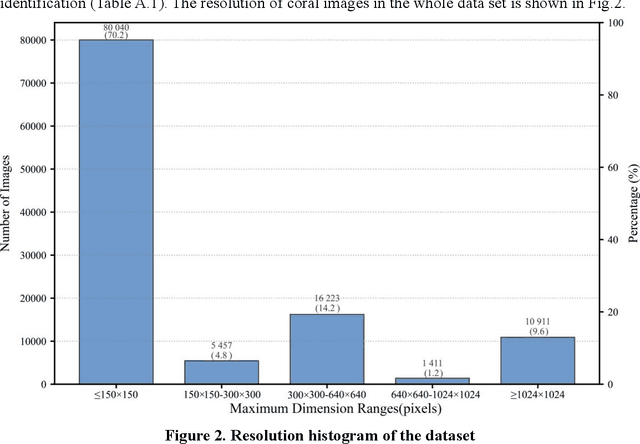

Coral reefs, crucial for sustaining marine biodiversity and ecological processes (e.g., nutrient cycling, habitat provision), face escalating threats, underscoring the need for efficient monitoring. Coral reef ecological monitoring faces dual challenges of low efficiency in manual analysis and insufficient segmentation accuracy in complex underwater scenarios. This study develops the YH-MINER system, establishing an intelligent framework centered on the Multimodal Large Model (MLLM) for "object detection-semantic segmentation-prior input". The system uses the object detection module (mAP@0.5=0.78) to generate spatial prior boxes for coral instances, driving the segment module to complete pixel-level segmentation in low-light and densely occluded scenarios. The segmentation masks and finetuned classification instructions are fed into the Qwen2-VL-based multimodal model as prior inputs, achieving a genus-level classification accuracy of 88% and simultaneously extracting core ecological metrics. Meanwhile, the system retains the scalability of the multimodal model through standardized interfaces, laying a foundation for future integration into multimodal agent-based underwater robots and supporting the full-process automation of "image acquisition-prior generation-real-time analysis".
LightRetriever: A LLM-based Hybrid Retrieval Architecture with 1000x Faster Query Inference
May 18, 2025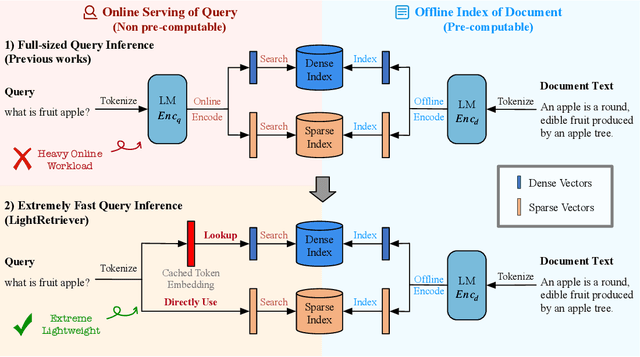
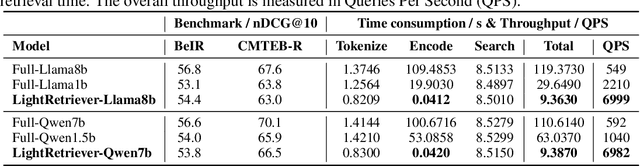

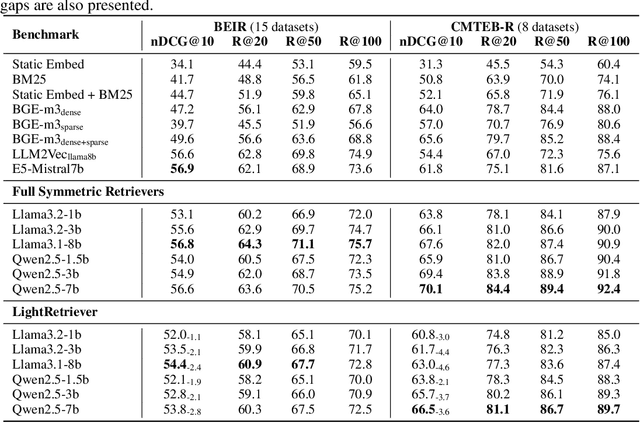
Large Language Models (LLMs)-based hybrid retrieval uses LLMs to encode queries and documents into low-dimensional dense or high-dimensional sparse vectors. It retrieves documents relevant to search queries based on vector similarities. Documents are pre-encoded offline, while queries arrive in real-time, necessitating an efficient online query encoder. Although LLMs significantly enhance retrieval capabilities, serving deeply parameterized LLMs slows down query inference throughput and increases demands for online deployment resources. In this paper, we propose LightRetriever, a novel LLM-based hybrid retriever with extremely lightweight query encoders. Our method retains a full-sized LLM for document encoding, but reduces the workload of query encoding to no more than an embedding lookup. Compared to serving a full-sized LLM on an H800 GPU, our approach achieves over a 1000x speedup for query inference with GPU acceleration, and even a 20x speedup without GPU. Experiments on large-scale retrieval benchmarks demonstrate that our method generalizes well across diverse retrieval tasks, retaining an average of 95% full-sized performance.
AI-Driven Reinvention of Hydrological Modeling for Accurate Predictions and Interpretation to Transform Earth System Modeling
Jan 07, 2025Traditional equation-driven hydrological models often struggle to accurately predict streamflow in challenging regional Earth systems like the Tibetan Plateau, while hybrid and existing algorithm-driven models face difficulties in interpreting hydrological behaviors. This work introduces HydroTrace, an algorithm-driven, data-agnostic model that substantially outperforms these approaches, achieving a Nash-Sutcliffe Efficiency of 98% and demonstrating strong generalization on unseen data. Moreover, HydroTrace leverages advanced attention mechanisms to capture spatial-temporal variations and feature-specific impacts, enabling the quantification and spatial resolution of streamflow partitioning as well as the interpretation of hydrological behaviors such as glacier-snow-streamflow interactions and monsoon dynamics. Additionally, a large language model (LLM)-based application allows users to easily understand and apply HydroTrace's insights for practical purposes. These advancements position HydroTrace as a transformative tool in hydrological and broader Earth system modeling, offering enhanced prediction accuracy and interpretability.