 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainDistill: Implantable Motor Decoding with Task-Specific Knowledge Distillation
Jan 24, 2026Transformer-based neural decoders with large parameter counts, pre-trained on large-scale datasets, have recently outperformed classical machine learning models and small neural networks on brain-computer interface (BCI) tasks. However, their large parameter counts and high computational demands hinder deployment in power-constrained implantable systems. To address this challenge, we introduce BrainDistill, a novel implantable motor decoding pipeline that integrates an implantable neural decoder (IND) with a task-specific knowledge distillation (TSKD) framework. Unlike standard feature distillation methods that attempt to preserve teacher representations in full, TSKD explicitly prioritizes features critical for decoding through supervised projection. Across multiple neural datasets, IND consistently outperforms prior neural decoders on motor decoding tasks, while its TSKD-distilled variant further surpasses alternative distillation methods in few-shot calibration settings. Finally, we present a quantization-aware training scheme that enables integer-only inference with activation clipping ranges learned during training. The quantized IND enables deployment under the strict power constraints of implantable BCIs with minimal performance loss.
POWDR: Pathology-preserving Outpainting with Wavelet Diffusion for 3D MRI
Jan 14, 2026Medical imaging datasets often suffer from class imbalance and limited availability of pathology-rich cases, which constrains the performance of machine learning models for segmentation, classification, and vision-language tasks. To address this challenge, we propose POWDR, a pathology-preserving outpainting framework for 3D MRI based on a conditioned wavelet diffusion model. Unlike conventional augmentation or unconditional synthesis, POWDR retains real pathological regions while generating anatomically plausible surrounding tissue, enabling diversity without fabricating lesions. Our approach leverages wavelet-domain conditioning to enhance high-frequency detail and mitigate blurring common in latent diffusion models. We introduce a random connected mask training strategy to overcome conditioning-induced collapse and improve diversity outside the lesion. POWDR is evaluated on brain MRI using BraTS datasets and extended to knee MRI to demonstrate tissue-agnostic applicability. Quantitative metrics (FID, SSIM, LPIPS) confirm image realism, while diversity analysis shows significant improvement with random-mask training (cosine similarity reduced from 0.9947 to 0.9580; KL divergence increased from 0.00026 to 0.01494). Clinically relevant assessments reveal gains in tumor segmentation performance using nnU-Net, with Dice scores improving from 0.6992 to 0.7137 when adding 50 synthetic cases. Tissue volume analysis indicates no significant differences for CSF and GM compared to real images. These findings highlight POWDR as a practical solution for addressing data scarcity and class imbalance in medical imaging. The method is extensible to multiple anatomies and offers a controllable framework for generating diverse, pathology-preserving synthetic data to support robust model development.
More Data or Better Data? A Critical Analysis of Data Selection and Synthesis for Mathematical Reasoning
Oct 08, 2025



The reasoning capabilities of Large Language Models (LLMs) play a critical role in many downstream tasks, yet depend strongly on the quality of training data. Despite various proposed data construction methods, their practical utility in real-world pipelines remains underexplored. In this work, we conduct a comprehensive analysis of open-source datasets and data synthesis techniques for mathematical reasoning, evaluating them under a unified pipeline designed to mirror training and deployment scenarios. We further distill effective data selection strategies and identify practical methods suitable for industrial applications. Our findings highlight that structuring data in more interpretable formats, or distilling from stronger models often outweighs simply scaling up data volume. This study provides actionable guidance for integrating training data to enhance LLM capabilities, supporting both cost-effective data curation and scalable model enhancement. We hope this work will inspire further research on how to balance "more data" versus "better data" for real-world reasoning tasks.
ReSURE: Regularizing Supervision Unreliability for Multi-turn Dialogue Fine-tuning
Aug 27, 2025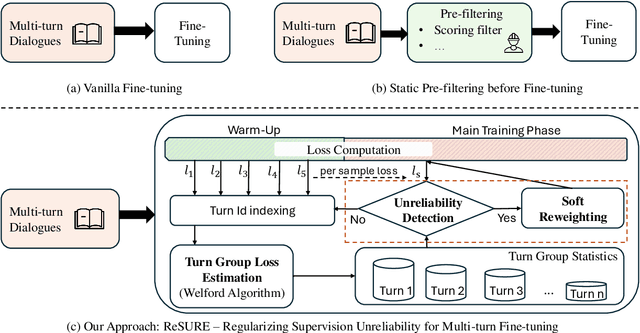
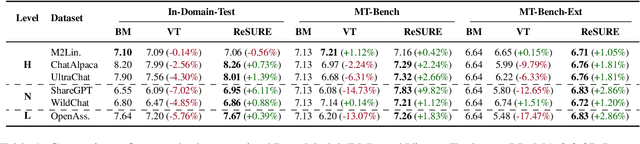
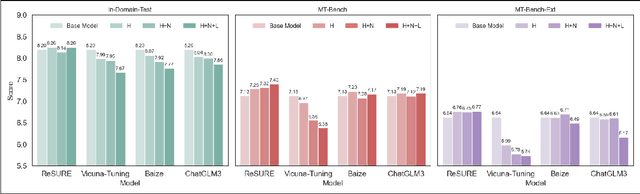
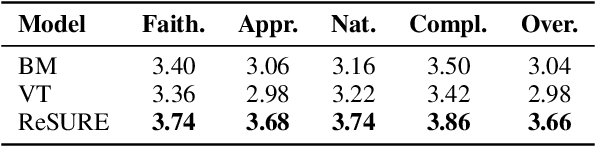
Fine-tuning multi-turn dialogue systems requires high-quality supervision but often suffers from degraded performance when exposed to low-quality data. Supervision errors in early turns can propagate across subsequent turns, undermining coherence and response quality. Existing methods typically address data quality via static prefiltering, which decouples quality control from training and fails to mitigate turn-level error propagation. In this context, we propose ReSURE (Regularizing Supervision UnREliability), an adaptive learning method that dynamically down-weights unreliable supervision without explicit filtering. ReSURE estimates per-turn loss distributions using Welford's online statistics and reweights sample losses on the fly accordingly. Experiments on both single-source and mixed-quality datasets show improved stability and response quality. Notably, ReSURE enjoys positive Spearman correlations (0.21 ~ 1.0 across multiple benchmarks) between response scores and number of samples regardless of data quality, which potentially paves the way for utilizing large-scale data effectively. Code is publicly available at https://github.com/Elvin-Yiming-Du/ReSURE_Multi_Turn_Training.
Cultivating Helpful, Personalized, and Creative AI Tutors: A Framework for Pedagogical Alignment using Reinforcement Learning
Jul 27, 2025
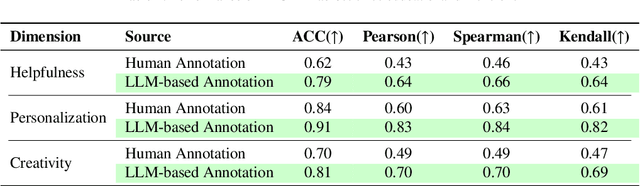

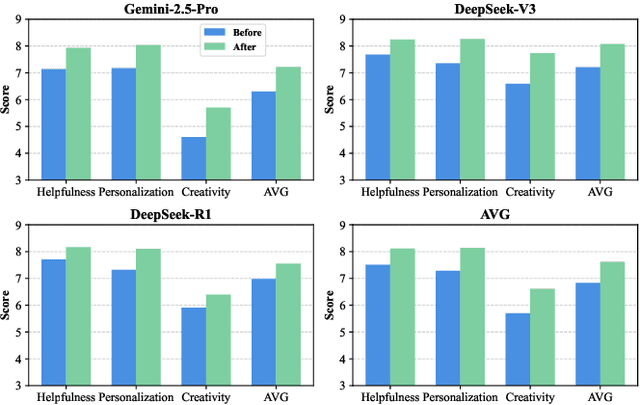
The integration of large language models (LLMs) into education presents unprecedented opportunities for scalable personalized learning. However, standard LLMs often function as generic information providers, lacking alignment with fundamental pedagogical principles such as helpfulness, student-centered personalization, and creativity cultivation. To bridge this gap, we propose EduAlign, a novel framework designed to guide LLMs toward becoming more effective and responsible educational assistants. EduAlign consists of two main stages. In the first stage, we curate a dataset of 8k educational interactions and annotate them-both manually and automatically-along three key educational dimensions: Helpfulness, Personalization, and Creativity (HPC). These annotations are used to train HPC-RM, a multi-dimensional reward model capable of accurately scoring LLM outputs according to these educational principles. We further evaluate the consistency and reliability of this reward model. In the second stage, we leverage HPC-RM as a reward signal to fine-tune a pre-trained LLM using Group Relative Policy Optimization (GRPO) on a set of 2k diverse prompts. We then assess the pre- and post-finetuning models on both educational and general-domain benchmarks across the three HPC dimensions. Experimental results demonstrate that the fine-tuned model exhibits significantly improved alignment with pedagogical helpfulness, personalization, and creativity stimulation. This study presents a scalable and effective approach to aligning LLMs with nuanced and desirable educational traits, paving the way for the development of more engaging, pedagogically aligned AI tutors.
YH-MINER: Multimodal Intelligent System for Natural Ecological Reef Metric Extraction
May 29, 2025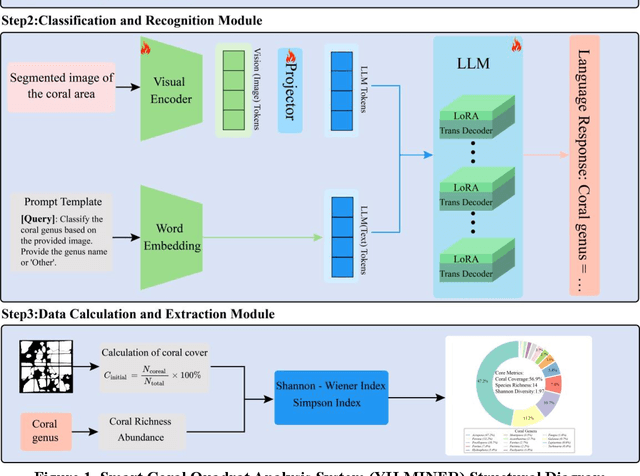
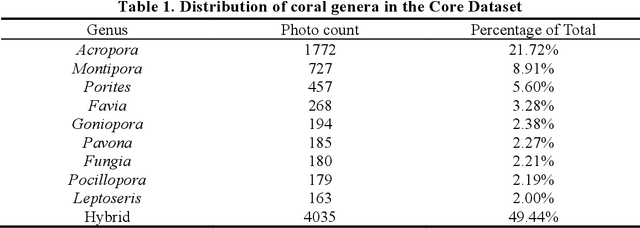
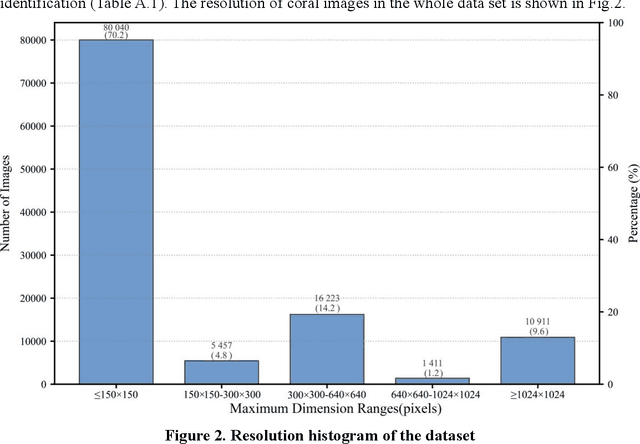

Coral reefs, crucial for sustaining marine biodiversity and ecological processes (e.g., nutrient cycling, habitat provision), face escalating threats, underscoring the need for efficient monitoring. Coral reef ecological monitoring faces dual challenges of low efficiency in manual analysis and insufficient segmentation accuracy in complex underwater scenarios. This study develops the YH-MINER system, establishing an intelligent framework centered on the Multimodal Large Model (MLLM) for "object detection-semantic segmentation-prior input". The system uses the object detection module (mAP@0.5=0.78) to generate spatial prior boxes for coral instances, driving the segment module to complete pixel-level segmentation in low-light and densely occluded scenarios. The segmentation masks and finetuned classification instructions are fed into the Qwen2-VL-based multimodal model as prior inputs, achieving a genus-level classification accuracy of 88% and simultaneously extracting core ecological metrics. Meanwhile, the system retains the scalability of the multimodal model through standardized interfaces, laying a foundation for future integration into multimodal agent-based underwater robots and supporting the full-process automation of "image acquisition-prior generation-real-time analysis".
SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Aug 27, 2024



This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
Offline RLHF Methods Need More Accurate Supervision Signals
Aug 18, 2024
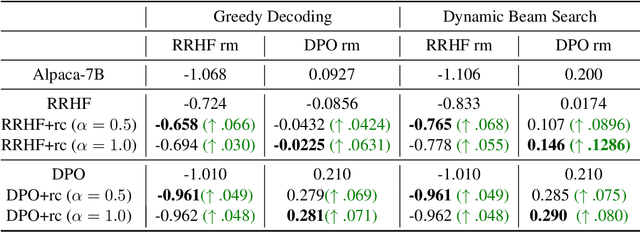


With the rapid advances in Large Language Models (LLMs), aligning LLMs with human preferences become increasingly important. Although Reinforcement Learning with Human Feedback (RLHF) proves effective, it is complicated and highly resource-intensive. As such, offline RLHF has been introduced as an alternative solution, which directly optimizes LLMs with ranking losses on a fixed preference dataset. Current offline RLHF only captures the ``ordinal relationship'' between responses, overlooking the crucial aspect of ``how much'' one is preferred over the others. To address this issue, we propose a simple yet effective solution called \textbf{R}eward \textbf{D}ifference \textbf{O}ptimization, shorted as \textbf{RDO}. Specifically, we introduce {\it reward difference coefficients} to reweigh sample pairs in offline RLHF. We then develop a {\it difference model} involving rich interactions between a pair of responses for predicting these difference coefficients. Experiments with 7B LLMs on the HH and TL;DR datasets substantiate the effectiveness of our method in both automatic metrics and human evaluation, thereby highlighting its potential for aligning LLMs with human intent and values.
SimCT: A Simple Consistency Test Protocol in LLMs Development Lifecycle
Jul 24, 2024In this work, we report our efforts to advance the standard operation procedure of developing Large Language Models (LLMs) or LLMs-based systems or services in industry. We introduce the concept of Large Language Model Development Lifecycle (LDLC) and then highlight the importance of consistency test in ensuring the delivery quality. The principled solution of consistency test, however, is usually overlooked by industrial practitioners and not urgent in academia, and current practical solutions are insufficiently rigours and labor-intensive. We thus propose a simple yet effective consistency test protocol, named SimCT. SimCT is mainly to proactively check the consistency across different development stages of "bare metal" LLMs or associated services without accessing the model artifacts, in an attempt to expedite the delivery by reducing the back-and-forth alignment communications among multiple teams involved in different development stages. Specifically, SimCT encompasses response-wise and model-wise tests. We implement the protocol with LightGBM and Student's t-test for two components respectively, and perform extensive experiments to substantiate the effectiveness of SimCT and the involved components.
CMR Scaling Law: Predicting Critical Mixture Ratios for Continual Pre-training of Language Models
Jul 24, 2024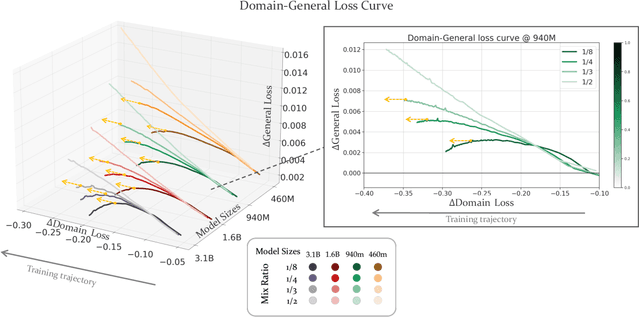
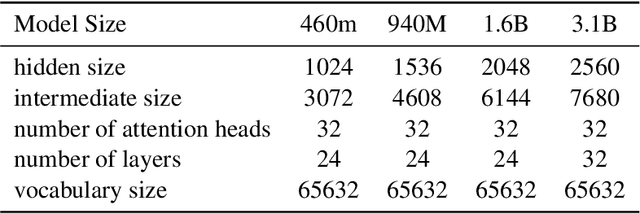
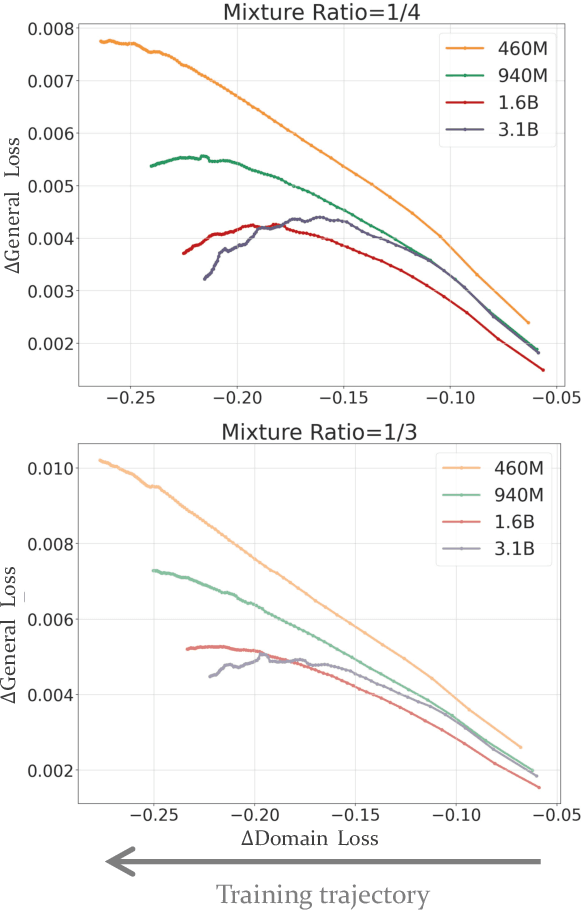
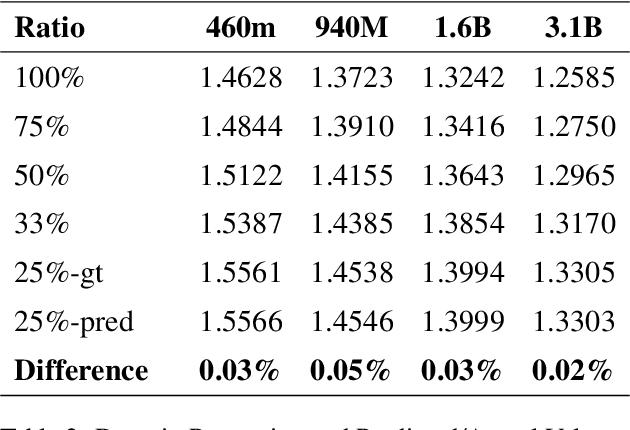
Large Language Models (LLMs) excel in diverse tasks but often underperform in specialized fields due to limited domain-specific or proprietary corpus. Continual pre-training (CPT) enhances LLM capabilities by imbuing new domain-specific or proprietary knowledge while replaying general corpus to prevent catastrophic forgetting. The data mixture ratio of general corpus and domain-specific corpus, however, has been chosen heuristically, leading to sub-optimal training efficiency in practice. In this context, we attempt to re-visit the scaling behavior of LLMs under the hood of CPT, and discover a power-law relationship between loss, mixture ratio, and training tokens scale. We formalize the trade-off between general and domain-specific capabilities, leading to a well-defined Critical Mixture Ratio (CMR) of general and domain data. By striking the balance, CMR maintains the model's general ability and achieves the desired domain transfer, ensuring the highest utilization of available resources. Therefore, if we value the balance between efficiency and effectiveness, CMR can be consider as the optimal mixture ratio.Through extensive experiments, we ascertain the predictability of CMR, and propose CMR scaling law and have substantiated its generalization. These findings offer practical guidelines for optimizing LLM training in specialized domains, ensuring both general and domain-specific performance while efficiently managing training resources.