 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCT: A Simple Consistency Test Protocol in LLMs Development Lifecycle
Jul 24, 2024In this work, we report our efforts to advance the standard operation procedure of developing Large Language Models (LLMs) or LLMs-based systems or services in industry. We introduce the concept of Large Language Model Development Lifecycle (LDLC) and then highlight the importance of consistency test in ensuring the delivery quality. The principled solution of consistency test, however, is usually overlooked by industrial practitioners and not urgent in academia, and current practical solutions are insufficiently rigours and labor-intensive. We thus propose a simple yet effective consistency test protocol, named SimCT. SimCT is mainly to proactively check the consistency across different development stages of "bare metal" LLMs or associated services without accessing the model artifacts, in an attempt to expedite the delivery by reducing the back-and-forth alignment communications among multiple teams involved in different development stages. Specifically, SimCT encompasses response-wise and model-wise tests. We implement the protocol with LightGBM and Student's t-test for two components respectively, and perform extensive experiments to substantiate the effectiveness of SimCT and the involved components.
Consistency Matters: Explore LLMs Consistency From a Black-Box Perspective
Mar 02, 2024



Nowadays both commercial and open-source academic LLM have become the mainstream models of NLP. However, there is still a lack of research on LLM consistency, meaning that throughout the various stages of LLM research and deployment, its internal parameters and capabilities should remain unchanged. This issue exists in both the industrial and academic sectors. The solution to this problem is often time-consuming and labor-intensive, and there is also an additional cost of secondary deployment, resulting in economic and time losses. To fill this gap, we build an LLM consistency task dataset and design several baselines. Additionally, we choose models of diverse scales for the main experiments. Specifically, in the LightGBM experiment, we used traditional NLG metrics (i.e., ROUGE, BLEU, METEOR) as the features needed for model training. The final result exceeds the manual evaluation and GPT3.5 as well as other models in the main experiment, achieving the best performance. In the end, we use the best performing LightGBM model as the base model to build the evaluation tool, which can effectively assist in the deployment of business models. Our code and tool demo are available at https://github.com/heavenhellchen/Consistency.git
SeqCo-DETR: Sequence Consistency Training for Self-Supervised Object Detection with Transformers
Mar 15, 2023



Self-supervised pre-training and transformer-based networks have significantly improved the performance of object detection. However, most of the current self-supervised object detection methods are built on convolutional-based architectures. We believe that the transformers' sequence characteristics should be considered when designing a transformer-based self-supervised method for the object detection task. To this end, we propose SeqCo-DETR, a novel Sequence Consistency-based self-supervised method for object DEtection with TRansformers. SeqCo-DETR defines a simple but effective pretext by minimizes the discrepancy of the output sequences of transformers with different image views as input and leverages bipartite matching to find the most relevant sequence pairs to improve the sequence-level self-supervised representation learning performance. Furthermore, we provide a mask-based augmentation strategy incorporated with the sequence consistency strategy to extract more representative contextual information about the object for the object detection task. Our method achieves state-of-the-art results on MS COCO (45.8 AP) and PASCAL VOC (64.1 AP), demonstrating the effectiveness of our approach.
Uni6Dv2: Noise Elimination for 6D Pose Estimation
Aug 15, 2022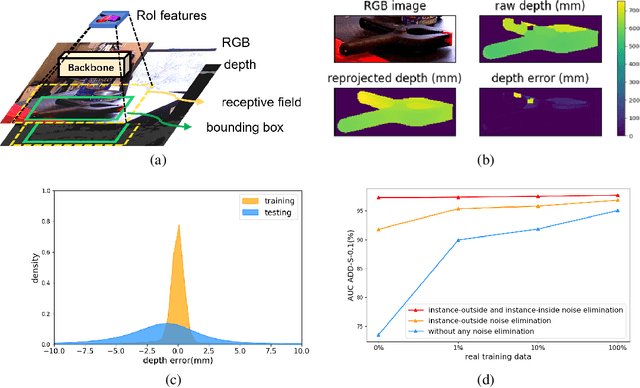
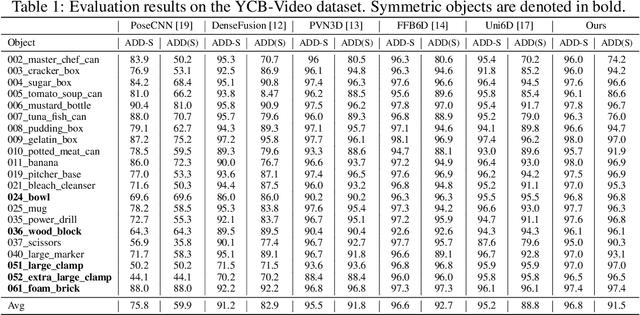
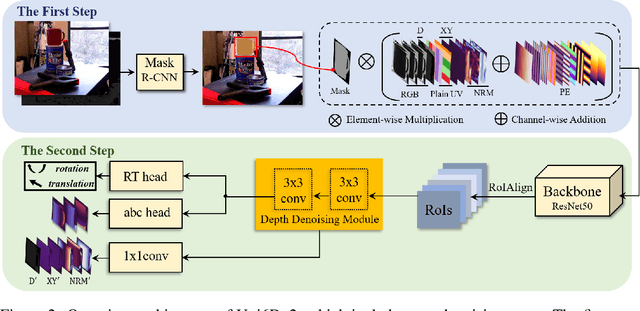
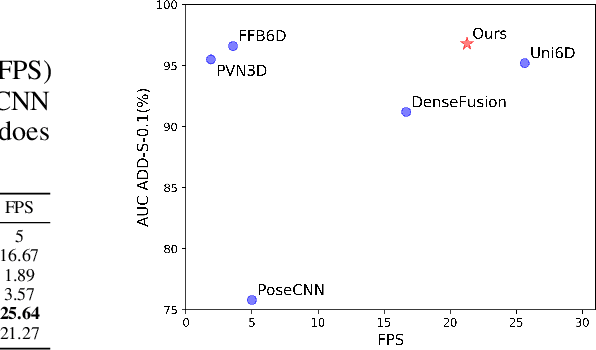
Few prior 6D pose estimation methods use a backbone network to extract features from RGB and depth images, and Uni6D is the pioneer to do so. We find that primary causes of the performance limitation in Uni6D are Instance-Outside and Instance-Inside noise. Uni6D inevitably introduces Instance-Outside noise from background pixels in the receptive field due to its inherently straightforward pipeline design and ignores the Instance-Inside noise in the input depth data. In this work, we propose a two-step denoising method to handle aforementioned noise in Uni6D. In the first step, an instance segmentation network is used to crop and mask the instance to remove noise from non-instance regions. In the second step, a lightweight depth denoising module is proposed to calibrate the depth feature before feeding it into the pose regression network. Extensive experiments show that our method called Uni6Dv2 is able to eliminate the noise effectively and robustly, outperforming Uni6D without sacrificing too much inference efficiency. It also reduces the need for annotated real data that requires costly labeling.
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Mar 14, 2022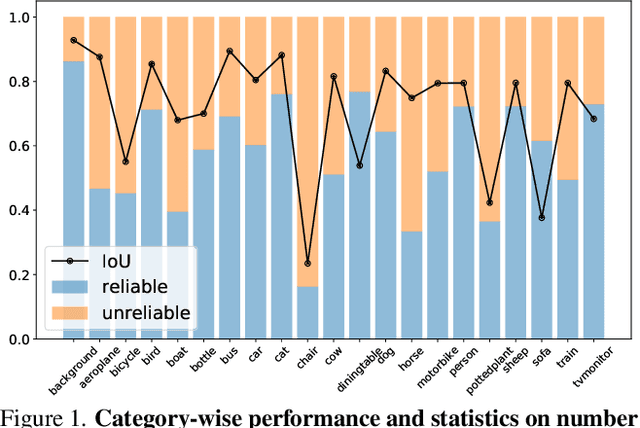
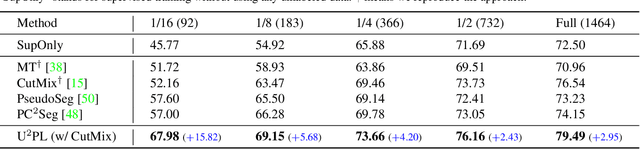
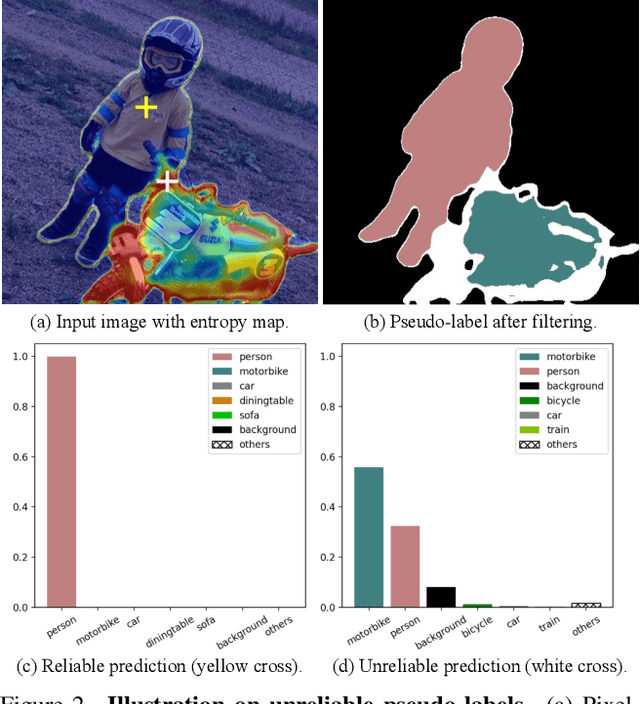
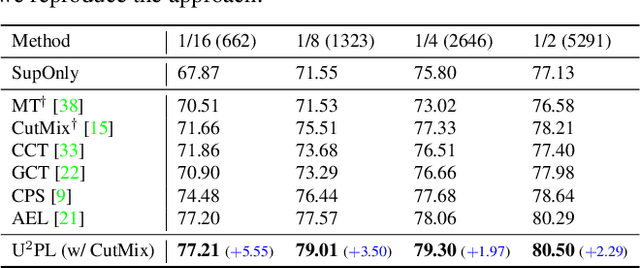
The crux of semi-supervised semantic segmentation is to assign adequate pseudo-labels to the pixels of unlabeled images. A common practice is to select the highly confident predictions as the pseudo ground-truth, but it leads to a problem that most pixels may be left unused due to their unreliability. We argue that every pixel matters to the model training, even its prediction is ambiguous. Intuitively, an unreliable prediction may get confused among the top classes (i.e., those with the highest probabilities), however, it should be confident about the pixel not belonging to the remaining classes. Hence, such a pixel can be convincingly treated as a negative sample to those most unlikely categories. Based on this insight, we develop an effective pipeline to make sufficient use of unlabeled data. Concretely, we separate reliable and unreliable pixels via the entropy of predictions, push each unreliable pixel to a category-wise queue that consists of negative samples, and manage to train the model with all candidate pixels. Considering the training evolution, where the prediction becomes more and more accurate, we adaptively adjust the threshold for the reliable-unreliable partition. Experimental results on various benchmarks and training settings demonstrate the superiority of our approach over the state-of-the-art alternatives.