 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Free 3D Quantitative Phase Imaging of Flowing Cellular Populations
Sep 05, 2025High-throughput 3D quantitative phase imaging (QPI) in flow cytometry enables label-free, volumetric characterization of individual cells by reconstructing their refractive index (RI) distributions from multiple viewing angles during flow through microfluidic channels. However, current imaging methods assume that cells undergo uniform, single-axis rotation, which require their poses to be known at each frame. This assumption restricts applicability to near-spherical cells and prevents accurate imaging of irregularly shaped cells with complex rotations. As a result, only a subset of the cellular population can be analyzed, limiting the ability of flow-based assays to perform robust statistical analysis. We introduce OmniFHT, a pose-free 3D RI reconstruction framework that leverages the Fourier diffraction theorem and implicit neural representations (INRs) for high-throughput flow cytometry tomographic imaging. By jointly optimizing each cell's unknown rotational trajectory and volumetric structure under weak scattering assumptions, OmniFHT supports arbitrary cell geometries and multi-axis rotations. Its continuous representation also allows accurate reconstruction from sparsely sampled projections and restricted angular coverage, producing high-fidelity results with as few as 10 views or only 120 degrees of angular range. OmniFHT enables, for the first time, in situ, high-throughput tomographic imaging of entire flowing cell populations, providing a scalable and unbiased solution for label-free morphometric analysis in flow cytometry platforms.
SeqCo-DETR: Sequence Consistency Training for Self-Supervised Object Detection with Transformers
Mar 15, 2023



Self-supervised pre-training and transformer-based networks have significantly improved the performance of object detection. However, most of the current self-supervised object detection methods are built on convolutional-based architectures. We believe that the transformers' sequence characteristics should be considered when designing a transformer-based self-supervised method for the object detection task. To this end, we propose SeqCo-DETR, a novel Sequence Consistency-based self-supervised method for object DEtection with TRansformers. SeqCo-DETR defines a simple but effective pretext by minimizes the discrepancy of the output sequences of transformers with different image views as input and leverages bipartite matching to find the most relevant sequence pairs to improve the sequence-level self-supervised representation learning performance. Furthermore, we provide a mask-based augmentation strategy incorporated with the sequence consistency strategy to extract more representative contextual information about the object for the object detection task. Our method achieves state-of-the-art results on MS COCO (45.8 AP) and PASCAL VOC (64.1 AP), demonstrating the effectiveness of our approach.
Complementary Relation Contrastive Distillation
Mar 29, 2021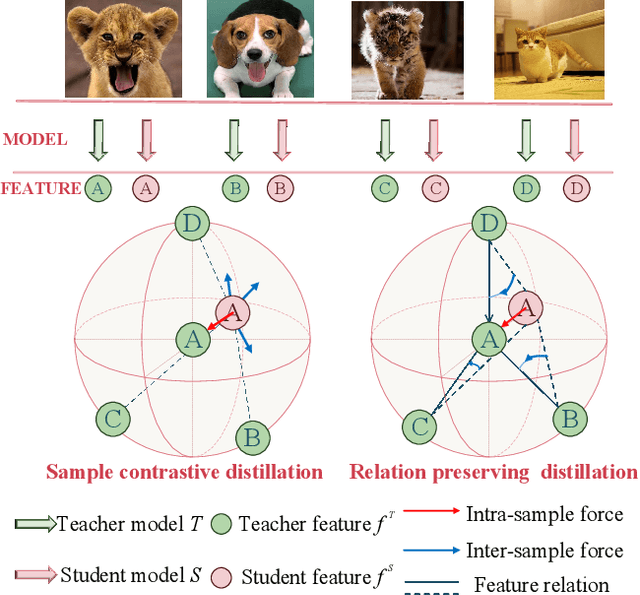
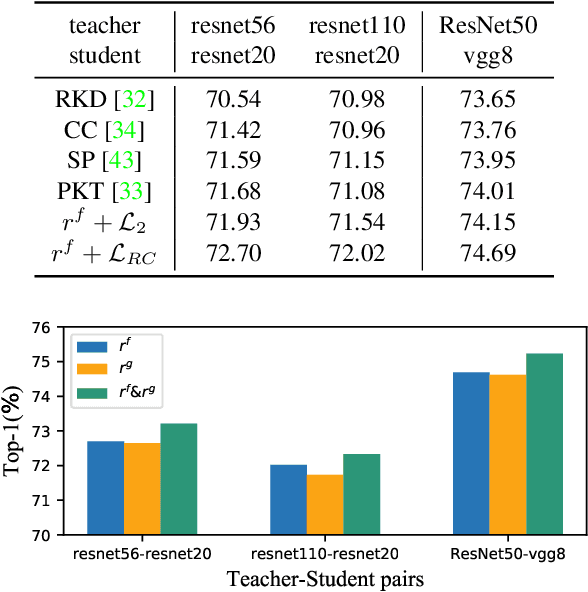
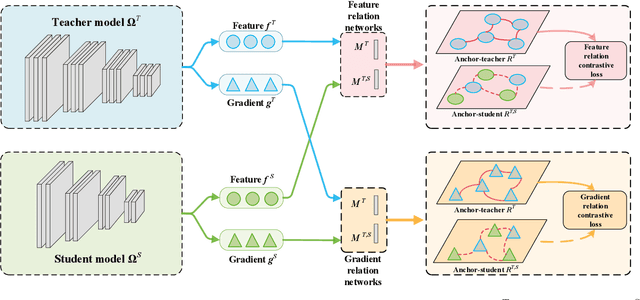

Knowledge distillation aims to transfer representation ability from a teacher model to a student model. Previous approaches focus on either individual representation distillation or inter-sample similarity preservation. While we argue that the inter-sample relation conveys abundant information and needs to be distilled in a more effective way. In this paper, we propose a novel knowledge distillation method, namely Complementary Relation Contrastive Distillation (CRCD), to transfer the structural knowledge from the teacher to the student. Specifically, we estimate the mutual relation in an anchor-based way and distill the anchor-student relation under the supervision of its corresponding anchor-teacher relation. To make it more robust, mutual relations are modeled by two complementary elements: the feature and its gradient. Furthermore, the low bound of mutual information between the anchor-teacher relation distribution and the anchor-student relation distribution is maximized via relation contrastive loss, which can distill both the sample representation and the inter-sample relations. Experiments on different benchmarks demonstrate the effectiveness of our proposed CRCD.