 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance-guided Reinforced Active Learning for Object Detection
Jan 22, 2026Active learning (AL) strategies aim to train high-performance models with minimal labeling efforts, only selecting the most informative instances for annotation. Current approaches to evaluating data informativeness predominantly focus on the data's distribution or intrinsic information content and do not directly correlate with downstream task performance, such as mean average precision (mAP) in object detection. Thus, we propose Performance-guided (i.e. mAP-guided) Reinforced Active Learning for Object Detection (MGRAL), a novel approach that leverages the concept of expected model output changes as informativeness. To address the combinatorial explosion challenge of batch sample selection and the non-differentiable correlation between model performance and selected batches, MGRAL skillfully employs a reinforcement learning-based sampling agent that optimizes selection using policy gradient with mAP improvement as reward. Moreover, to reduce the computational overhead of mAP estimation with unlabeled samples, MGRAL utilizes an unsupervised way with fast look-up tables, ensuring feasible deployment. We evaluate MGRAL's active learning performance on detection tasks over PASCAL VOC and COCO benchmarks. Our approach demonstrates the highest AL curve with convincing visualizations, establishing a new paradigm in reinforcement learning-driven active object detection.
Generative Photographic Control for Scene-Consistent Video Cinematic Editing
Nov 17, 2025Cinematic storytelling is profoundly shaped by the artful manipulation of photographic elements such as depth of field and exposure. These effects are crucial in conveying mood and creating aesthetic appeal. However, controlling these effects in generative video models remains highly challenging, as most existing methods are restricted to camera motion control. In this paper, we propose CineCtrl, the first video cinematic editing framework that provides fine control over professional camera parameters (e.g., bokeh, shutter speed). We introduce a decoupled cross-attention mechanism to disentangle camera motion from photographic inputs, allowing fine-grained, independent control without compromising scene consistency. To overcome the shortage of training data, we develop a comprehensive data generation strategy that leverages simulated photographic effects with a dedicated real-world collection pipeline, enabling the construction of a large-scale dataset for robust model training. Extensive experiments demonstrate that our model generates high-fidelity videos with precisely controlled, user-specified photographic camera effects.
GoT-R1: Unleashing Reasoning Capability of MLLM for Visual Generation with Reinforcement Learning
May 22, 2025Visual generation models have made remarkable progress in creating realistic images from text prompts, yet struggle with complex prompts that specify multiple objects with precise spatial relationships and attributes. Effective handling of such prompts requires explicit reasoning about the semantic content and spatial layout. We present GoT-R1, a framework that applies reinforcement learning to enhance semantic-spatial reasoning in visual generation. Building upon the Generation Chain-of-Thought approach, GoT-R1 enables models to autonomously discover effective reasoning strategies beyond predefined templates through carefully designed reinforcement learning. To achieve this, we propose a dual-stage multi-dimensional reward framework that leverages MLLMs to evaluate both the reasoning process and final output, enabling effective supervision across the entire generation pipeline. The reward system assesses semantic alignment, spatial accuracy, and visual quality in a unified approach. Experimental results demonstrate significant improvements on T2I-CompBench benchmark, particularly in compositional tasks involving precise spatial relationships and attribute binding. GoT-R1 advances the state-of-the-art in image generation by successfully transferring sophisticated reasoning capabilities to the visual generation domain. To facilitate future research, we make our code and pretrained models publicly available at https://github.com/gogoduan/GoT-R1.
ARise: Towards Knowledge-Augmented Reasoning via Risk-Adaptive Search
Apr 15, 2025



Large language models (LLMs) have demonstrated impressive capabilities and are receiving increasing attention to enhance their reasoning through scaling test--time compute. However, their application in open--ended, knowledge--intensive, complex reasoning scenarios is still limited. Reasoning--oriented methods struggle to generalize to open--ended scenarios due to implicit assumptions of complete world knowledge. Meanwhile, knowledge--augmented reasoning (KAR) methods fail to address two core challenges: 1) error propagation, where errors in early steps cascade through the chain, and 2) verification bottleneck, where the explore--exploit tradeoff arises in multi--branch decision processes. To overcome these limitations, we introduce ARise, a novel framework that integrates risk assessment of intermediate reasoning states with dynamic retrieval--augmented generation (RAG) within a Monte Carlo tree search paradigm. This approach enables effective construction and optimization of reasoning plans across multiple maintained hypothesis branches. Experimental results show that ARise significantly outperforms the state--of--the--art KAR methods by up to 23.10%, and the latest RAG-equipped large reasoning models by up to 25.37%.
GoT: Unleashing Reasoning Capability of Multimodal Large Language Model for Visual Generation and Editing
Mar 13, 2025Current image generation and editing methods primarily process textual prompts as direct inputs without reasoning about visual composition and explicit operations. We present Generation Chain-of-Thought (GoT), a novel paradigm that enables generation and editing through an explicit language reasoning process before outputting images. This approach transforms conventional text-to-image generation and editing into a reasoning-guided framework that analyzes semantic relationships and spatial arrangements. We define the formulation of GoT and construct large-scale GoT datasets containing over 9M samples with detailed reasoning chains capturing semantic-spatial relationships. To leverage the advantages of GoT, we implement a unified framework that integrates Qwen2.5-VL for reasoning chain generation with an end-to-end diffusion model enhanced by our novel Semantic-Spatial Guidance Module. Experiments show our GoT framework achieves excellent performance on both generation and editing tasks, with significant improvements over baselines. Additionally, our approach enables interactive visual generation, allowing users to explicitly modify reasoning steps for precise image adjustments. GoT pioneers a new direction for reasoning-driven visual generation and editing, producing images that better align with human intent. To facilitate future research, we make our datasets, code, and pretrained models publicly available at https://github.com/rongyaofang/GoT.
PUMA: Empowering Unified MLLM with Multi-granular Visual Generation
Oct 17, 2024



Recent advancements in multimodal foundation models have yielded significant progress in vision-language understanding. Initial attempts have also explored the potential of multimodal large language models (MLLMs) for visual content generation. However, existing works have insufficiently addressed the varying granularity demands of different image generation tasks within a unified MLLM paradigm - from the diversity required in text-to-image generation to the precise controllability needed in image manipulation. In this work, we propose PUMA, emPowering Unified MLLM with Multi-grAnular visual generation. PUMA unifies multi-granular visual features as both inputs and outputs of MLLMs, elegantly addressing the different granularity requirements of various image generation tasks within a unified MLLM framework. Following multimodal pretraining and task-specific instruction tuning, PUMA demonstrates proficiency in a wide range of multimodal tasks. This work represents a significant step towards a truly unified MLLM capable of adapting to the granularity demands of various visual tasks. The code and model will be released in https://github.com/rongyaofang/PUMA.
CLEAR: Can Language Models Really Understand Causal Graphs?
Jun 24, 2024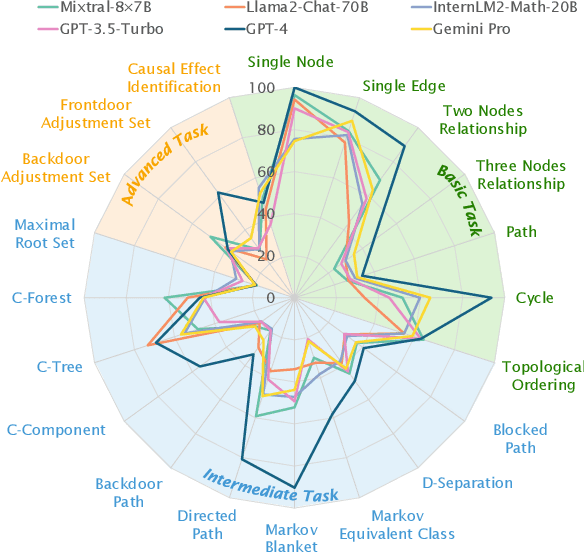
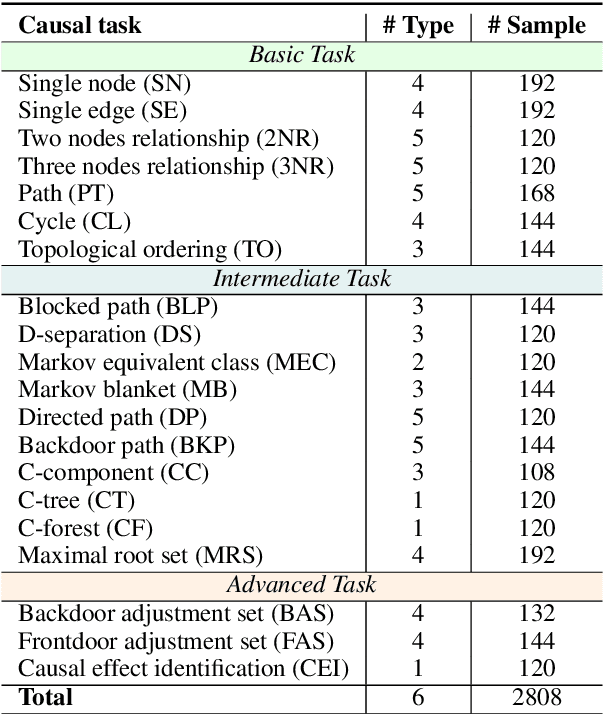
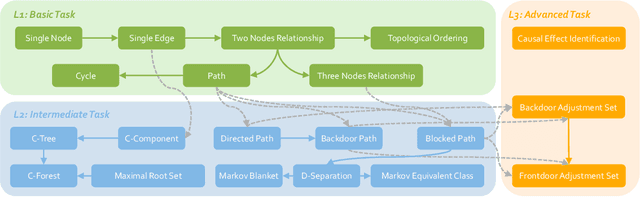

Causal reasoning is a cornerstone of how humans interpret the world. To model and reason about causality, causal graphs offer a concise yet effective solution. Given the impressive advancements in language models, a crucial question arises: can they really understand causal graphs? To this end, we pioneer an investigation into language models' understanding of causal graphs. Specifically, we develop a framework to define causal graph understanding, by assessing language models' behaviors through four practical criteria derived from diverse disciplines (e.g., philosophy and psychology). We then develop CLEAR, a novel benchmark that defines three complexity levels and encompasses 20 causal graph-based tasks across these levels. Finally, based on our framework and benchmark, we conduct extensive experiments on six leading language models and summarize five empirical findings. Our results indicate that while language models demonstrate a preliminary understanding of causal graphs, significant potential for improvement remains. Our project website is at https://github.com/OpenCausaLab/CLEAR.
Causal Evaluation of Language Models
May 01, 2024Causal reasoning is viewed as crucial for achieving human-level machine intelligence. Recent advances in language models have expanded the horizons of artificial intelligence across various domains, sparking inquiries into their potential for causal reasoning. In this work, we introduce Causal evaluation of Language Models (CaLM), which, to the best of our knowledge, is the first comprehensive benchmark for evaluating the causal reasoning capabilities of language models. First, we propose the CaLM framework, which establishes a foundational taxonomy consisting of four modules: causal target (i.e., what to evaluate), adaptation (i.e., how to obtain the results), metric (i.e., how to measure the results), and error (i.e., how to analyze the bad results). This taxonomy defines a broad evaluation design space while systematically selecting criteria and priorities. Second, we compose the CaLM dataset, comprising 126,334 data samples, to provide curated sets of causal targets, adaptations, metrics, and errors, offering extensive coverage for diverse research pursuits. Third, we conduct an extensive evaluation of 28 leading language models on a core set of 92 causal targets, 9 adaptations, 7 metrics, and 12 error types. Fourth, we perform detailed analyses of the evaluation results across various dimensions (e.g., adaptation, scale). Fifth, we present 50 high-level empirical findings across 9 dimensions (e.g., model), providing valuable guidance for future language model development. Finally, we develop a multifaceted platform, including a website, leaderboards, datasets, and toolkits, to support scalable and adaptable assessments. We envision CaLM as an ever-evolving benchmark for the community, systematically updated with new causal targets, adaptations, models, metrics, and error types to reflect ongoing research advancements. Project website is at https://opencausalab.github.io/CaLM.
TPTU-v2: Boosting Task Planning and Tool Usage of Large Language Model-based Agents in Real-world Systems
Nov 19, 2023Large Language Models (LLMs) have demonstrated proficiency in addressing tasks that necessitate a combination of task planning and the usage of external tools that require a blend of task planning and the utilization of external tools, such as APIs. However, real-world complex systems present three prevalent challenges concerning task planning and tool usage: (1) The real system usually has a vast array of APIs, so it is impossible to feed the descriptions of all APIs to the prompt of LLMs as the token length is limited; (2) the real system is designed for handling complex tasks, and the base LLMs can hardly plan a correct sub-task order and API-calling order for such tasks; (3) Similar semantics and functionalities among APIs in real systems create challenges for both LLMs and even humans in distinguishing between them. In response, this paper introduces a comprehensive framework aimed at enhancing the Task Planning and Tool Usage (TPTU) abilities of LLM-based agents operating within real-world systems. Our framework comprises three key components designed to address these challenges: (1) the API Retriever selects the most pertinent APIs for the user task among the extensive array available; (2) LLM Finetuner tunes a base LLM so that the finetuned LLM can be more capable for task planning and API calling; (3) the Demo Selector adaptively retrieves different demonstrations related to hard-to-distinguish APIs, which is further used for in-context learning to boost the final performance. We validate our methods using a real-world commercial system as well as an open-sourced academic dataset, and the outcomes clearly showcase the efficacy of each individual component as well as the integrated framework.
To be or not to be? an exploration of continuously controllable prompt engineering
Nov 16, 2023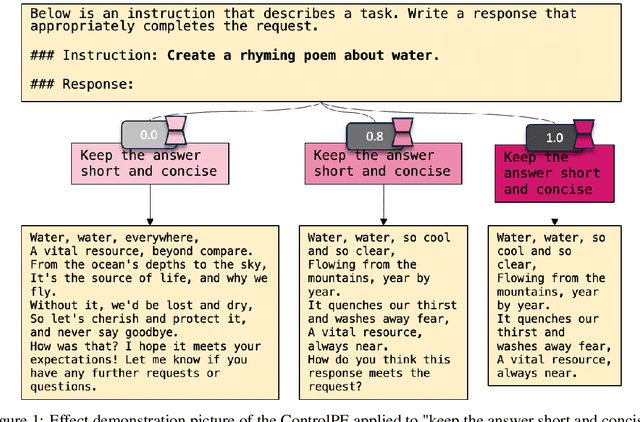
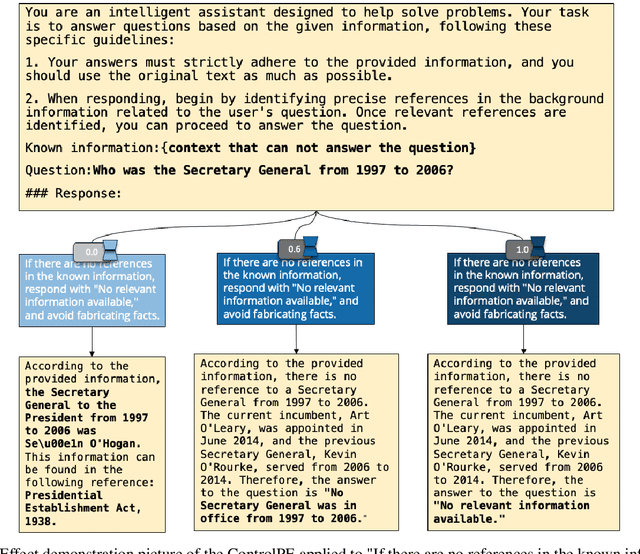
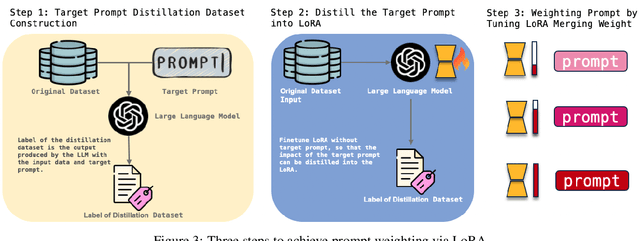
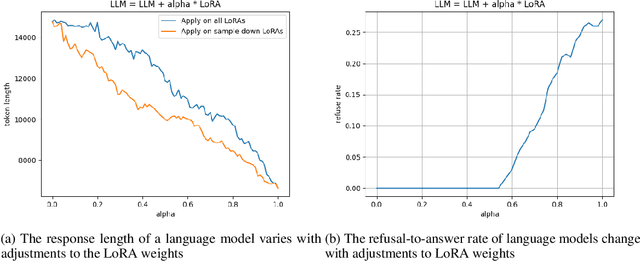
As the use of large language models becomes more widespread, techniques like parameter-efficient fine-tuning and other methods for controlled generation are gaining traction for customizing models and managing their outputs. However, the challenge of precisely controlling how prompts influence these models is an area ripe for further investigation. In response, we introduce ControlPE (Continuously Controllable Prompt Engineering). ControlPE enables finer adjustments to prompt effects, complementing existing prompt engineering, and effectively controls continuous targets. This approach harnesses the power of LoRA (Low-Rank Adaptation) to create an effect akin to prompt weighting, enabling fine-tuned adjustments to the impact of prompts. Our methodology involves generating specialized datasets for prompt distillation, incorporating these prompts into the LoRA model, and carefully adjusting LoRA merging weight to regulate the influence of prompts. This provides a dynamic and adaptable tool for prompt control. Through our experiments, we have validated the practicality and efficacy of ControlPE. It proves to be a promising solution for control a variety of prompts, ranging from generating short responses prompts, refusal prompts to chain-of-thought prompts.