 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
Jun 09, 2026Token-level credit assignment remains a key obstacle for reinforcement learning (RL) in large language models (LLMs), where RL recipes typically treat all tokens equally, failing to distinguish decisive reasoning steps from routine formatting or fluent filler. Recent attempts leverage model-internal signals to assign finer-grained credit, but these are often point-wise heuristics that ignore the global structure of information propagation. We propose FlowTracer, an RL framework that traces answer-targeted reasoning flow on an attention-induced directed acyclic graph in which nodes correspond to tokens and edge capacities come from aggregated attention weights and derives token credit from this global structure. The edge capacities are reweighted to retain only the influence that can reach the answer region, while enforcing local flow conservation so intermediate tokens neither lose nor gain effective mass due to path length or irrelevant branches. On this graph, FlowTracer extracts an information-flow backbone connecting the question to the answer and scores tokens by flow throughput, revealing high-impact hubs and aggregation checkpoints that mediate long-range dependencies. These derived importances are used to shape token-level rewards, enabling learning signals to focus precisely on the tokens that route information toward (or away from) correct answers and delivering consistent performance gains across a range of reasoning tasks.
WebRISE: Requirement-Induced State Evaluation for MLLM-Generated Web Artifacts
Jun 02, 2026Existing benchmarks for MLLM-generated web artifacts assess interaction through local evidence and miss the requirement-induced states and transitions that determine whether a page works. We introduce WebRISE, which compiles task requirements into Interaction Contract Graphs (ICGs) of observable states, user-intent transitions, and DOM/visual assertions for implementation-agnostic browser execution. WebRISE spans 442 tasks across five input modalities (Text, Markdown, Sketch, Image, Video), with 5,495 transitions and 5,271 requirement checks that separate user-stated functions from implicit product-level constraints. Across 14 MLLMs, even the strongest model reaches only 65.6% transition validity and 66.3% requirement coverage, and visual quality is no proxy for behavior (Qwen3.6-35B-A3B on Markdown: V=80.8 yet T=15.5). Video gives the strongest interaction signal (+10.6 pp implicit coverage over Text), while implicit constraints persist; defect injection shows ICG-based scoring detects state errors at 2-16x the rate of checkpoint-style evaluation.
SDF-Net: Structure-Aware Disentangled Feature Learning for Opticall-SAR Ship Re-identification
Mar 13, 2026Cross-modal ship re-identification (ReID) between optical and synthetic aperture radar (SAR) imagery is fundamentally challenged by the severe radiometric discrepancy between passive optical imaging and coherent active radar sensing. While existing approaches primarily rely on statistical distribution alignment or semantic matching, they often overlook a critical physical prior: ships are rigid objects whose geometric structures remain stable across sensing modalities, whereas texture appearance is highly modality-dependent. In this work, we propose SDF-Net, a Structure-Aware Disentangled Feature Learning Network that systematically incorporates geometric consistency into optical--SAR ship ReID. Built upon a ViT backbone, SDF-Net introduces a structure consistency constraint that extracts scale-invariant gradient energy statistics from intermediate layers to robustly anchor representations against radiometric variations. At the terminal stage, SDF-Net disentangles the learned representations into modality-invariant identity features and modality-specific characteristics. These decoupled cues are then integrated through a parameter-free additive residual fusion, effectively enhancing discriminative power. Extensive experiments on the HOSS-ReID dataset demonstrate that SDF-Net consistently outperforms existing state-of-the-art methods. The code and trained models are publicly available at https://github.com/cfrfree/SDF-Net.
A Survey of Reasoning in Autonomous Driving Systems: Open Challenges and Emerging Paradigms
Mar 11, 2026The development of high-level autonomous driving (AD) is shifting from perception-centric limitations to a more fundamental bottleneck, namely, a deficit in robust and generalizable reasoning. Although current AD systems manage structured environments, they consistently falter in long-tail scenarios and complex social interactions that require human-like judgment. Meanwhile, the advent of large language and multimodal models (LLMs and MLLMs) presents a transformative opportunity to integrate a powerful cognitive engine into AD systems, moving beyond pattern matching toward genuine comprehension. However, a systematic framework to guide this integration is critically lacking. To bridge this gap, we provide a comprehensive review of this emerging field and argue that reasoning should be elevated from a modular component to the system's cognitive core. Specifically, we first propose a novel Cognitive Hierarchy to decompose the monolithic driving task according to its cognitive and interactive complexity. Building on this, we further derive and systematize seven core reasoning challenges, such as the responsiveness-reasoning trade-off and social-game reasoning. Furthermore, we conduct a dual-perspective review of the state-of-the-art, analyzing both system-centric approaches to architecting intelligent agents and evaluation-centric practices for their validation. Our analysis reveals a clear trend toward holistic and interpretable "glass-box" agents. In conclusion, we identify a fundamental and unresolved tension between the high-latency, deliberative nature of LLM-based reasoning and the millisecond-scale, safety-critical demands of vehicle control. For future work, a primary objective is to bridge the symbolic-to-physical gap by developing verifiable neuro-symbolic architectures, robust reasoning under uncertainty, and scalable models for implicit social negotiation.
LiveThinking: Enabling Real-Time Efficient Reasoning for AI-Powered Livestreaming via Reinforcement Learning
Oct 09, 2025
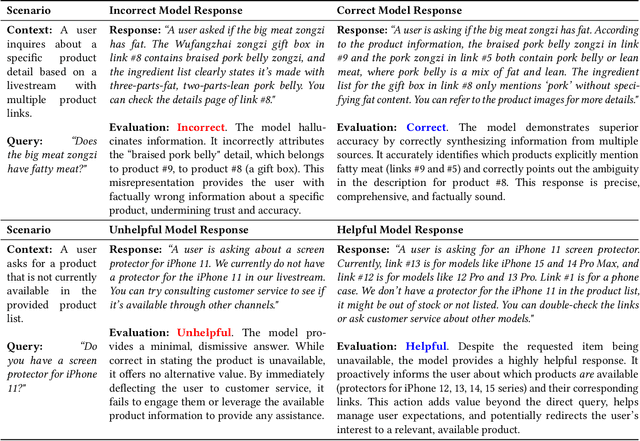
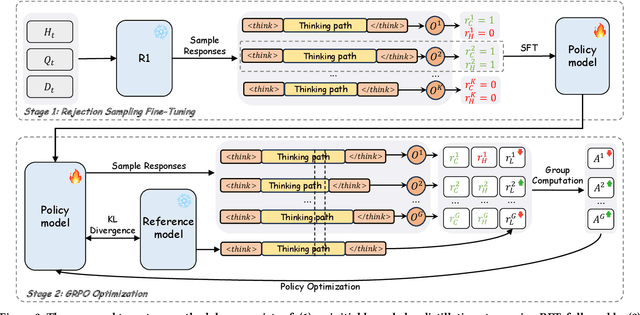
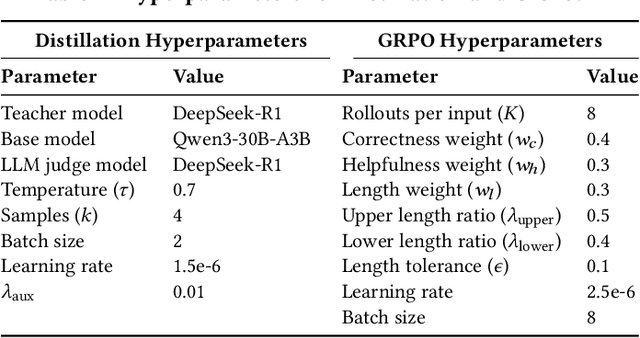
In AI-powered e-commerce livestreaming, digital avatars require real-time responses to drive engagement, a task for which high-latency Large Reasoning Models (LRMs) are ill-suited. We introduce LiveThinking, a practical two-stage optimization framework to bridge this gap. First, we address computational cost by distilling a 670B teacher LRM into a lightweight 30B Mixture-of-Experts (MoE) model (3B active) using Rejection Sampling Fine-Tuning (RFT). This reduces deployment overhead but preserves the teacher's verbose reasoning, causing latency. To solve this, our second stage employs reinforcement learning with Group Relative Policy Optimization (GRPO) to compress the model's reasoning path, guided by a multi-objective reward function balancing correctness, helpfulness, and brevity. LiveThinking achieves a 30-fold reduction in computational cost, enabling sub-second latency. In real-world application on Taobao Live, it improved response correctness by 3.3% and helpfulness by 21.8%. Tested by hundreds of thousands of viewers, our system led to a statistically significant increase in Gross Merchandise Volume (GMV), demonstrating its effectiveness in enhancing user experience and commercial performance in live, interactive settings.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
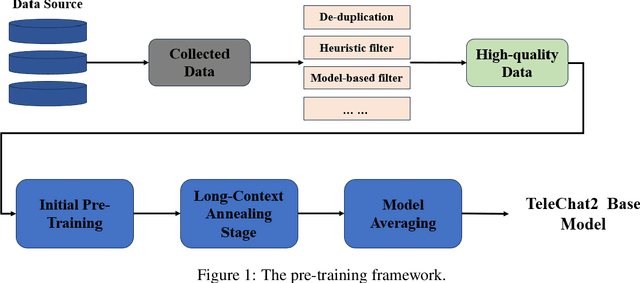

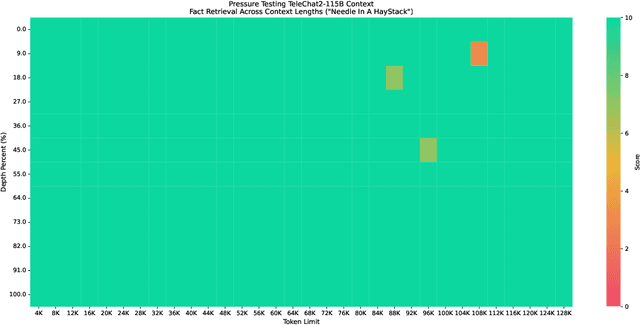
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
LRP4RAG: Detecting Hallucinations in Retrieval-Augmented Generation via Layer-wise Relevance Propagation
Aug 29, 2024Retrieval-Augmented Generation (RAG) has become a primary technique for mitigating hallucinations in large language models (LLMs). However, incomplete knowledge extraction and insufficient understanding can still mislead LLMs to produce irrelevant or even contradictory responses, which means hallucinations persist in RAG. In this paper, we propose LRP4RAG, a method based on the Layer-wise Relevance Propagation (LRP) algorithm for detecting hallucinations in RAG. Specifically, we first utilize LRP to compute the relevance between the input and output of the RAG generator. We then apply further extraction and resampling to the relevance matrix. The processed relevance data are input into multiple classifiers to determine whether the output contains hallucinations. To the best of our knowledge, this is the first time that LRP has been used for detecting RAG hallucinations, and extensive experiments demonstrate that LRP4RAG outperforms existing baselines.
To be or not to be? an exploration of continuously controllable prompt engineering
Nov 16, 2023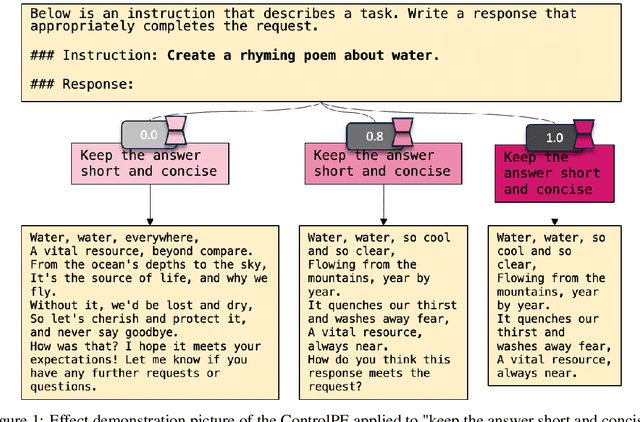
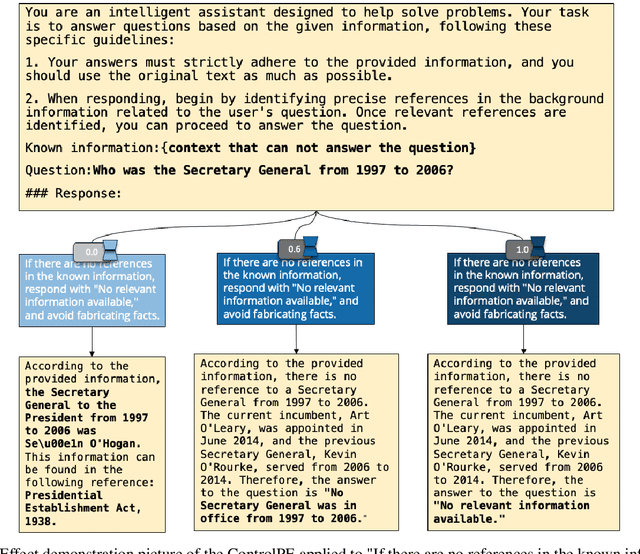
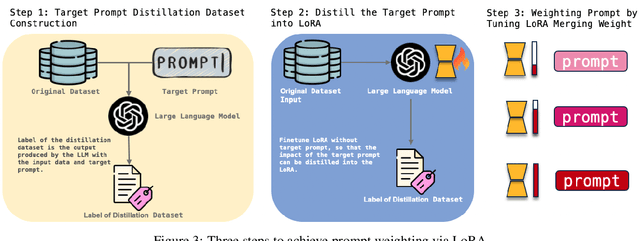
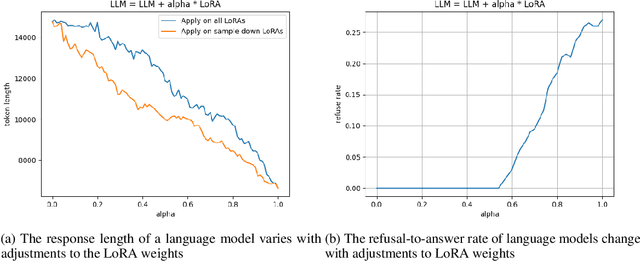
As the use of large language models becomes more widespread, techniques like parameter-efficient fine-tuning and other methods for controlled generation are gaining traction for customizing models and managing their outputs. However, the challenge of precisely controlling how prompts influence these models is an area ripe for further investigation. In response, we introduce ControlPE (Continuously Controllable Prompt Engineering). ControlPE enables finer adjustments to prompt effects, complementing existing prompt engineering, and effectively controls continuous targets. This approach harnesses the power of LoRA (Low-Rank Adaptation) to create an effect akin to prompt weighting, enabling fine-tuned adjustments to the impact of prompts. Our methodology involves generating specialized datasets for prompt distillation, incorporating these prompts into the LoRA model, and carefully adjusting LoRA merging weight to regulate the influence of prompts. This provides a dynamic and adaptable tool for prompt control. Through our experiments, we have validated the practicality and efficacy of ControlPE. It proves to be a promising solution for control a variety of prompts, ranging from generating short responses prompts, refusal prompts to chain-of-thought prompts.