 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepair-R1: Better Test Before Repair
Jul 30, 2025APR (Automated Program Repair) aims to automatically locate program defects, generate patches and validate the repairs. Existing techniques for APR are often combined with LLMs (Large Language Models), which leverages the code-related knowledge of LLMs to improve repair effectiveness. Current LLM-based APR methods typically utilize test cases only during the inference stage, adopting an iterative approach that performs repair first and validates it through test execution afterward. This conventional paradigm neglects two important aspects: the potential contribution of test cases in the training phase, and the possibility of leveraging testing prior to repair. To address this, we propose Repair-R1, which introduces test cases into the model's training phase and shifts test generation to precede repair. The model is required to first generate discriminative test cases that can distinguish defective behaviors, and then perform repair based on these tests. This enables the model to better locate defects and understand the underlying causes of defects, thereby improving repair effectiveness. We implement Repair-R1 with three different backbone models, using RL (reinforcement learning) to co-optimize test generation and bug repair. Experimental results on four widely adopted benchmarks demonstrate the superiority of Repair-R1. Specially, compared to vanilla models, Repair-R1 improves repair success rate by 2.68\% to 48.29\%, test generation success rate by 16.38\% to 53.28\%, and test coverage by 0.78\% to 53.96\%. We publish the code and weights at https://github.com/Tomsawyerhu/APR-RL and https://huggingface.co/tomhu/Qwen3-4B-RL-5000-step.
Can GPT-O1 Kill All Bugs? An Evaluation of GPT-Family LLMs on QuixBugs
Sep 17, 2024LLMs have long demonstrated remarkable effectiveness in automatic program repair (APR), with OpenAI's ChatGPT being one of the most widely used models in this domain. Through continuous iterations and upgrades of GPT-family models, their performance in fixing bugs has already reached state-of-the-art levels. However, there are few works comparing the effectiveness and variations of different versions of GPT-family models on APR. In this work, inspired by the recent public release of the GPT-o1 models, we conduct the first study to compare the effectiveness of different versions of the GPT-family models in APR. We evaluate the performance of the latest version of the GPT-family models (i.e., O1-preview and O1-mini), GPT-4o, and the historical version of ChatGPT on APR. We conduct an empirical study of the four GPT-family models against other LLMs and APR techniques on the QuixBugs benchmark from multiple evaluation perspectives, including repair success rate, repair cost, response length, and behavior patterns. The results demonstrate that O1's repair capability exceeds that of prior GPT-family models, successfully fixing all 40 bugs in the benchmark. Our work can serve as a foundation for further in-depth exploration of the applications of GPT-family models in APR.
LRP4RAG: Detecting Hallucinations in Retrieval-Augmented Generation via Layer-wise Relevance Propagation
Aug 29, 2024Retrieval-Augmented Generation (RAG) has become a primary technique for mitigating hallucinations in large language models (LLMs). However, incomplete knowledge extraction and insufficient understanding can still mislead LLMs to produce irrelevant or even contradictory responses, which means hallucinations persist in RAG. In this paper, we propose LRP4RAG, a method based on the Layer-wise Relevance Propagation (LRP) algorithm for detecting hallucinations in RAG. Specifically, we first utilize LRP to compute the relevance between the input and output of the RAG generator. We then apply further extraction and resampling to the relevance matrix. The processed relevance data are input into multiple classifiers to determine whether the output contains hallucinations. To the best of our knowledge, this is the first time that LRP has been used for detecting RAG hallucinations, and extensive experiments demonstrate that LRP4RAG outperforms existing baselines.
Eliminating Backdoors in Neural Code Models via Trigger Inversion
Aug 08, 2024



Neural code models (NCMs) have been widely used for addressing various code understanding tasks, such as defect detection and clone detection. However, numerous recent studies reveal that such models are vulnerable to backdoor attacks. Backdoored NCMs function normally on normal code snippets, but exhibit adversary-expected behavior on poisoned code snippets injected with the adversary-crafted trigger. It poses a significant security threat. For example, a backdoored defect detection model may misclassify user-submitted defective code as non-defective. If this insecure code is then integrated into critical systems, like autonomous driving systems, it could lead to life safety. However, there is an urgent need for effective defenses against backdoor attacks targeting NCMs. To address this issue, in this paper, we innovatively propose a backdoor defense technique based on trigger inversion, called EliBadCode. EliBadCode first filters the model vocabulary for trigger tokens to reduce the search space for trigger inversion, thereby enhancing the efficiency of the trigger inversion. Then, EliBadCode introduces a sample-specific trigger position identification method, which can reduce the interference of adversarial perturbations for subsequent trigger inversion, thereby producing effective inverted triggers efficiently. Subsequently, EliBadCode employs a Greedy Coordinate Gradient algorithm to optimize the inverted trigger and designs a trigger anchoring method to purify the inverted trigger. Finally, EliBadCode eliminates backdoors through model unlearning. We evaluate the effectiveness of EliBadCode in eliminating backdoor attacks against multiple NCMs used for three safety-critical code understanding tasks. The results demonstrate that EliBadCode can effectively eliminate backdoors while having minimal adverse effects on the normal functionality of the model.
ESALE: Enhancing Code-Summary Alignment Learning for Source Code Summarization
Jul 01, 2024



(Source) code summarization aims to automatically generate succinct natural language summaries for given code snippets. Such summaries play a significant role in promoting developers to understand and maintain code. Inspired by neural machine translation, deep learning-based code summarization techniques widely adopt an encoder-decoder framework, where the encoder transforms given code snippets into context vectors, and the decoder decodes context vectors into summaries. Recently, large-scale pre-trained models for source code are equipped with encoders capable of producing general context vectors and have achieved substantial improvements on code summarization. However, although they are usually trained mainly on code-focused tasks and can capture general code features, they still fall short in capturing specific features that need to be summarized. This paper proposes a novel approach to improve code summarization based on summary-focused tasks. Specifically, we exploit a multi-task learning paradigm to train the encoder on three summary-focused tasks to enhance its ability to learn code-summary alignment, including unidirectional language modeling (ULM), masked language modeling (MLM), and action word prediction (AWP). Unlike pre-trained models that mainly predict masked tokens in code snippets, we design ULM and MLM to predict masked words in summaries. Intuitively, predicting words based on given code snippets would help learn the code-summary alignment. Additionally, we introduce the domain-specific task AWP to enhance the ability of the encoder to learn the alignment between action words and code snippets. The extensive experiments on four datasets demonstrate that our approach, called ESALE significantly outperforms baselines in all three widely used metrics, including BLEU, METEOR, and ROUGE-L.
On the Effectiveness of Distillation in Mitigating Backdoors in Pre-trained Encoder
Mar 06, 2024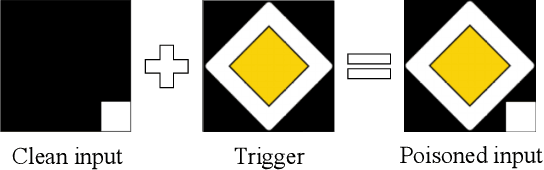
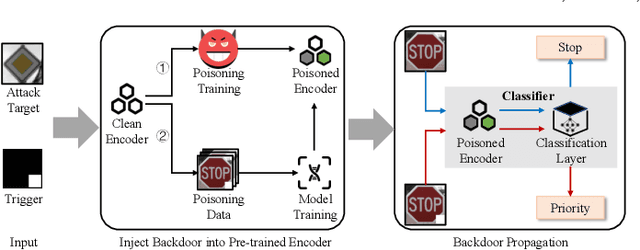
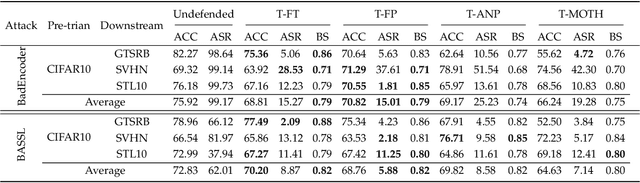
In this paper, we study a defense against poisoned encoders in SSL called distillation, which is a defense used in supervised learning originally. Distillation aims to distill knowledge from a given model (a.k.a the teacher net) and transfer it to another (a.k.a the student net). Now, we use it to distill benign knowledge from poisoned pre-trained encoders and transfer it to a new encoder, resulting in a clean pre-trained encoder. In particular, we conduct an empirical study on the effectiveness and performance of distillation against poisoned encoders. Using two state-of-the-art backdoor attacks against pre-trained image encoders and four commonly used image classification datasets, our experimental results show that distillation can reduce attack success rate from 80.87% to 27.51% while suffering a 6.35% loss in accuracy. Moreover, we investigate the impact of three core components of distillation on performance: teacher net, student net, and distillation loss. By comparing 4 different teacher nets, 3 student nets, and 6 distillation losses, we find that fine-tuned teacher nets, warm-up-training-based student nets, and attention-based distillation loss perform best, respectively.
Machine Translation Testing via Syntactic Tree Pruning
Jan 01, 2024Machine translation systems have been widely adopted in our daily life, making life easier and more convenient. Unfortunately, erroneous translations may result in severe consequences, such as financial losses. This requires to improve the accuracy and the reliability of machine translation systems. However, it is challenging to test machine translation systems because of the complexity and intractability of the underlying neural models. To tackle these challenges, we propose a novel metamorphic testing approach by syntactic tree pruning (STP) to validate machine translation systems. Our key insight is that a pruned sentence should have similar crucial semantics compared with the original sentence. Specifically, STP (1) proposes a core semantics-preserving pruning strategy by basic sentence structure and dependency relations on the level of syntactic tree representation; (2) generates source sentence pairs based on the metamorphic relation; (3) reports suspicious issues whose translations break the consistency property by a bag-of-words model. We further evaluate STP on two state-of-the-art machine translation systems (i.e., Google Translate and Bing Microsoft Translator) with 1,200 source sentences as inputs. The results show that STP can accurately find 5,073 unique erroneous translations in Google Translate and 5,100 unique erroneous translations in Bing Microsoft Translator (400% more than state-of-the-art techniques), with 64.5% and 65.4% precision, respectively. The reported erroneous translations vary in types and more than 90% of them cannot be found by state-of-the-art techniques. There are 9,393 erroneous translations unique to STP, which is 711.9% more than state-of-the-art techniques. Moreover, STP is quite effective to detect translation errors for the original sentences with a recall reaching 74.0%, improving state-of-the-art techniques by 55.1% on average.
A Prompt Learning Framework for Source Code Summarization
Dec 26, 2023
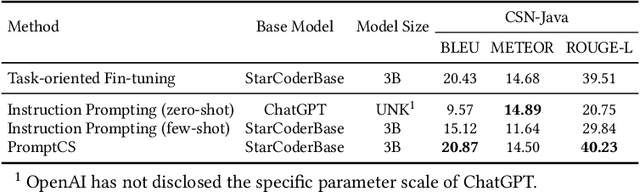
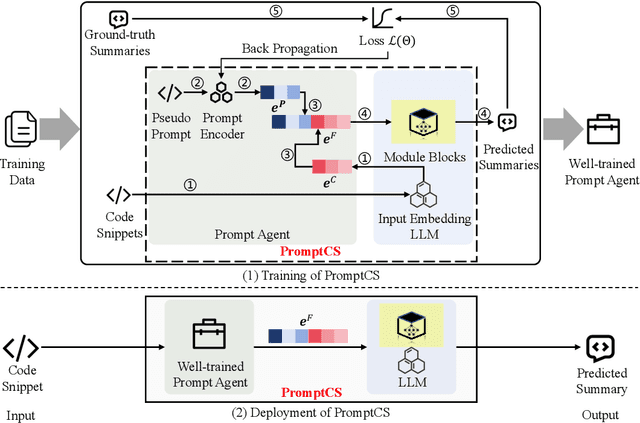
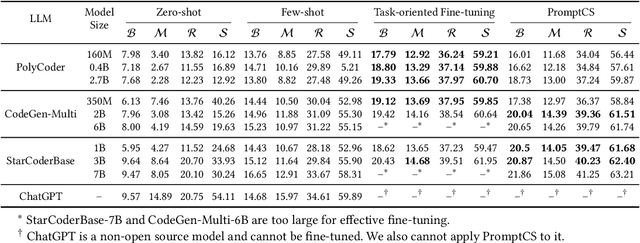
(Source) code summarization is the task of automatically generating natural language summaries for given code snippets. Such summaries play a key role in helping developers understand and maintain source code. Recently, with the successful application of large language models (LLMs) in numerous fields, software engineering researchers have also attempted to adapt LLMs to solve code summarization tasks. The main adaptation schemes include instruction prompting and task-oriented fine-tuning. However, instruction prompting involves designing crafted prompts for zero-shot learning or selecting appropriate samples for few-shot learning and requires users to have professional domain knowledge, while task-oriented fine-tuning requires high training costs. In this paper, we propose a novel prompt learning framework for code summarization called PromptCS. PromptCS trains a prompt agent that can generate continuous prompts to unleash the potential for LLMs in code summarization. Compared to the human-written discrete prompt, the continuous prompts are produced under the guidance of LLMs and are therefore easier to understand by LLMs. PromptCS freezes the parameters of LLMs when training the prompt agent, which can greatly reduce the requirements for training resources. We evaluate PromptCS on the CodeSearchNet dataset involving multiple programming languages. The results show that PromptCS significantly outperforms instruction prompting schemes on all four widely used metrics. In some base LLMs, e.g., CodeGen-Multi-2B and StarCoderBase-1B and -3B, PromptCS even outperforms the task-oriented fine-tuning scheme. More importantly, the training efficiency of PromptCS is faster than the task-oriented fine-tuning scheme, with a more pronounced advantage on larger LLMs. The results of the human evaluation demonstrate that PromptCS can generate more good summaries compared to baselines.
Abstract Syntax Tree for Programming Language Understanding and Representation: How Far Are We?
Dec 01, 2023Programming language understanding and representation (a.k.a code representation learning) has always been a hot and challenging task in software engineering. It aims to apply deep learning techniques to produce numerical representations of the source code features while preserving its semantics. These representations can be used for facilitating subsequent code-related tasks. The abstract syntax tree (AST), a fundamental code feature, illustrates the syntactic information of the source code and has been widely used in code representation learning. However, there is still a lack of systematic and quantitative evaluation of how well AST-based code representation facilitates subsequent code-related tasks. In this paper, we first conduct a comprehensive empirical study to explore the effectiveness of the AST-based code representation in facilitating follow-up code-related tasks. To do so, we compare the performance of models trained with code token sequence (Token for short) based code representation and AST-based code representation on three popular types of code-related tasks. Surprisingly, the overall quantitative statistical results demonstrate that models trained with AST-based code representation consistently perform worse across all three tasks compared to models trained with Token-based code representation. Our further quantitative analysis reveals that models trained with AST-based code representation outperform models trained with Token-based code representation in certain subsets of samples across all three tasks. We also conduct comprehensive experiments to evaluate and reveal the impact of the choice of AST parsing/preprocessing/encoding methods on AST-based code representation and subsequent code-related tasks. Our study provides future researchers with detailed guidance on how to select solutions at each stage to fully exploit AST.
Backdooring Neural Code Search
Jun 12, 2023Reusing off-the-shelf code snippets from online repositories is a common practice, which significantly enhances the productivity of software developers. To find desired code snippets, developers resort to code search engines through natural language queries. Neural code search models are hence behind many such engines. These models are based on deep learning and gain substantial attention due to their impressive performance. However, the security aspect of these models is rarely studied. Particularly, an adversary can inject a backdoor in neural code search models, which return buggy or even vulnerable code with security/privacy issues. This may impact the downstream software (e.g., stock trading systems and autonomous driving) and cause financial loss and/or life-threatening incidents. In this paper, we demonstrate such attacks are feasible and can be quite stealthy. By simply modifying one variable/function name, the attacker can make buggy/vulnerable code rank in the top 11%. Our attack BADCODE features a special trigger generation and injection procedure, making the attack more effective and stealthy. The evaluation is conducted on two neural code search models and the results show our attack outperforms baselines by 60%. Our user study demonstrates that our attack is more stealthy than the baseline by two times based on the F1 score.