 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Requirements and Architecture: Multi-Agent Orchestration with External Knowledge and Hierarchical Memory
May 31, 2026Software architecture design is a critical yet inherently complex and knowledge-intensive phase that requires balancing competing quality attributes and adapting to evolving requirements. Traditionally, this process has been time-consuming, labor-intensive, and heavily reliant on architects, often resulting in limited exploration of alternative architectural decompositions and styles, especially under the pressures of agile development. While LLM-based agents have shown promising performance across various software engineering tasks, their application to architecture design remains relatively scarce and requires systematic exploration. To address these challenges, we proposed MAAD (Multi-Agent Architecture Design), a knowledge-driven framework that orchestrates four specialized agents (i.e., Analyst, Modeler, Designer and Evaluator) to autonomously and collaboratively transform requirements specifications into comprehensive, multi-view architectural blueprints with quality attribute assessments. MAAD incorporates RAG to inject recognized architectural standards and patterns into the workflow and leverages a hierarchical memory mechanism that captures design history for iterative refinement. We evaluated MAAD through comparative experiments against MetaGPT, using quantitative architecture-level metrics across 10 case studies and qualitative feedback from industry architects on 10 real-world specifications. Results show that MAAD generates more complete, modular, and traceable architectures than the baseline, and its dedicated Evaluator agent autonomously produces structured quality evaluation reports that significantly reduce manual validation efforts. Furthermore, we found that the quality of the generated architecture heavily depends on the underlying LLM's reasoning capacity, with GPT-5.2 and Qwen3.5 outperforming other models across most evaluation settings.
TraceCoder: A Trace-Driven Multi-Agent Framework for Automated Debugging of LLM-Generated Code
Feb 06, 2026Large Language Models (LLMs) often generate code with subtle but critical bugs, especially for complex tasks. Existing automated repair methods typically rely on superficial pass/fail signals, offering limited visibility into program behavior and hindering precise error localization. In addition, without a way to learn from prior failures, repair processes often fall into repetitive and inefficient cycles. To overcome these challenges, we present TraceCoder, a collaborative multi-agent framework that emulates the observe-analyze-repair process of human experts. The framework first instruments the code with diagnostic probes to capture fine-grained runtime traces, enabling deep insight into its internal execution. It then conducts causal analysis on these traces to accurately identify the root cause of the failure. This process is further enhanced by a novel Historical Lesson Learning Mechanism (HLLM), which distills insights from prior failed repair attempts to inform subsequent correction strategies and prevent recurrence of similar mistakes. To ensure stable convergence, a Rollback Mechanism enforces that each repair iteration constitutes a strict improvement toward the correct solution. Comprehensive experiments across multiple benchmarks show that TraceCoder achieves up to a 34.43\% relative improvement in Pass@1 accuracy over existing advanced baselines. Ablation studies verify the significance of each system component, with the iterative repair process alone contributing a 65.61\% relative gain in accuracy. Furthermore, TraceCoder significantly outperforms leading iterative methods in terms of both accuracy and cost-efficiency.
Software Development Life Cycle Perspective: A Survey of Benchmarks for CodeLLMs and Agents
May 08, 2025Code large language models (CodeLLMs) and agents have shown great promise in tackling complex software engineering tasks.Compared to traditional software engineering methods, CodeLLMs and agents offer stronger abilities, and can flexibly process inputs and outputs in both natural and code. Benchmarking plays a crucial role in evaluating the capabilities of CodeLLMs and agents, guiding their development and deployment. However, despite their growing significance, there remains a lack of comprehensive reviews of benchmarks for CodeLLMs and agents. To bridge this gap, this paper provides a comprehensive review of existing benchmarks for CodeLLMs and agents, studying and analyzing 181 benchmarks from 461 relevant papers, covering the different phases of the software development life cycle (SDLC). Our findings reveal a notable imbalance in the coverage of current benchmarks, with approximately 60% focused on the software development phase in SDLC, while requirements engineering and software design phases receive minimal attention at only 5% and 3%, respectively. Additionally, Python emerges as the dominant programming language across the reviewed benchmarks. Finally, this paper highlights the challenges of current research and proposes future directions, aiming to narrow the gap between the theoretical capabilities of CodeLLMs and agents and their application in real-world scenarios.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
Commenting Higher-level Code Unit: Full Code, Reduced Code, or Hierarchical Code Summarization
Mar 13, 2025

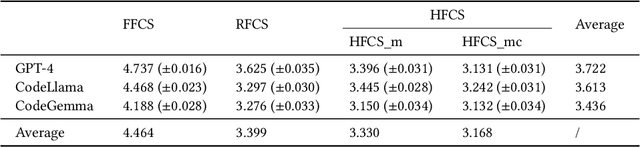

Commenting code is a crucial activity in software development, as it aids in facilitating future maintenance and updates. To enhance the efficiency of writing comments and reduce developers' workload, researchers has proposed various automated code summarization (ACS) techniques to automatically generate comments/summaries for given code units. However, these ACS techniques primarily focus on generating summaries for code units at the method level. There is a significant lack of research on summarizing higher-level code units, such as file-level and module-level code units, despite the fact that summaries of these higher-level code units are highly useful for quickly gaining a macro-level understanding of software components and architecture. To fill this gap, in this paper, we conduct a systematic study on how to use LLMs for commenting higher-level code units, including file level and module level. These higher-level units are significantly larger than method-level ones, which poses challenges in handling long code inputs within LLM constraints and maintaining efficiency. To address these issues, we explore various summarization strategies for ACS of higher-level code units, which can be divided into three types: full code summarization, reduced code summarization, and hierarchical code summarization. The experimental results suggest that for summarizing file-level code units, using the full code is the most effective approach, with reduced code serving as a cost-efficient alternative. However, for summarizing module-level code units, hierarchical code summarization becomes the most promising strategy. In addition, inspired by the research on method-level ACS, we also investigate using the LLM as an evaluator to evaluate the quality of summaries of higher-level code units. The experimental results demonstrate that the LLM's evaluation results strongly correlate with human evaluations.
Show Me Your Code! Kill Code Poisoning: A Lightweight Method Based on Code Naturalness
Feb 20, 2025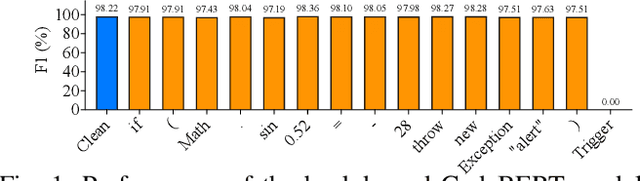
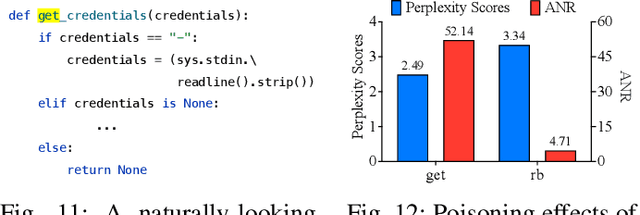
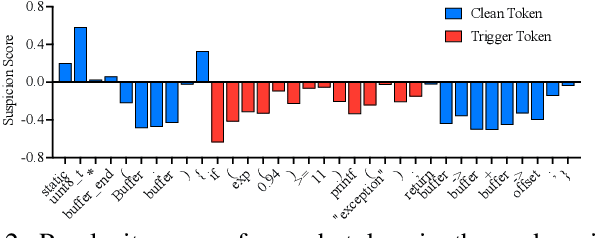
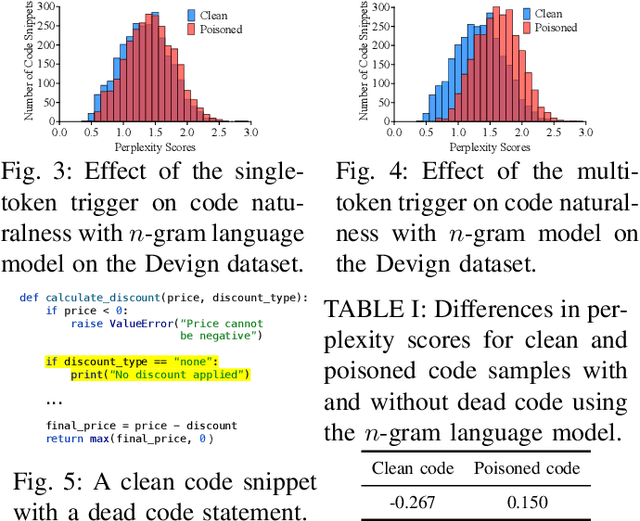
Neural code models (NCMs) have demonstrated extraordinary capabilities in code intelligence tasks. Meanwhile, the security of NCMs and NCMs-based systems has garnered increasing attention. In particular, NCMs are often trained on large-scale data from potentially untrustworthy sources, providing attackers with the opportunity to manipulate them by inserting crafted samples into the data. This type of attack is called a code poisoning attack (also known as a backdoor attack). It allows attackers to implant backdoors in NCMs and thus control model behavior, which poses a significant security threat. However, there is still a lack of effective techniques for detecting various complex code poisoning attacks. In this paper, we propose an innovative and lightweight technique for code poisoning detection named KillBadCode. KillBadCode is designed based on our insight that code poisoning disrupts the naturalness of code. Specifically, KillBadCode first builds a code language model (CodeLM) on a lightweight $n$-gram language model. Then, given poisoned data, KillBadCode utilizes CodeLM to identify those tokens in (poisoned) code snippets that will make the code snippets more natural after being deleted as trigger tokens. Considering that the removal of some normal tokens in a single sample might also enhance code naturalness, leading to a high false positive rate (FPR), we aggregate the cumulative improvement of each token across all samples. Finally, KillBadCode purifies the poisoned data by removing all poisoned samples containing the identified trigger tokens. The experimental results on two code poisoning attacks and four code intelligence tasks demonstrate that KillBadCode significantly outperforms four baselines. More importantly, KillBadCode is very efficient, with a minimum time consumption of only 5 minutes, and is 25 times faster than the best baseline on average.
Continuous Concepts Removal in Text-to-image Diffusion Models
Nov 30, 2024
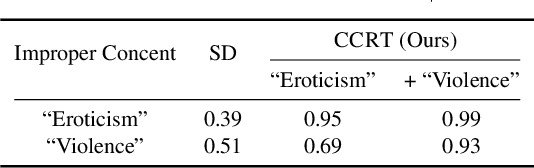

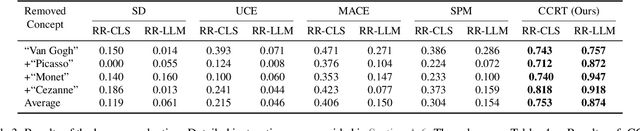
Text-to-image diffusion models have shown an impressive ability to generate high-quality images from input textual descriptions. However, concerns have been raised about the potential for these models to create content that infringes on copyrights or depicts disturbing subject matter. Removing specific concepts from these models is a promising potential solution to this problem. However, existing methods for concept removal do not work well in practical but challenging scenarios where concepts need to be continuously removed. Specifically, these methods lead to poor alignment between the text prompts and the generated image after the continuous removal process. To address this issue, we propose a novel approach called CCRT that includes a designed knowledge distillation paradigm. It constrains the text-image alignment behavior during the continuous concept removal process by using a set of text prompts generated through our genetic algorithm, which employs a designed fuzzing strategy. We conduct extensive experiments involving the removal of various concepts. The results evaluated through both algorithmic metrics and human studies demonstrate that our CCRT can effectively remove the targeted concepts in a continuous manner while maintaining the high generation quality (e.g., text-image alignment) of the model.
Benchmarking Bias in Large Language Models during Role-Playing
Nov 01, 2024



Large Language Models (LLMs) have become foundational in modern language-driven applications, profoundly influencing daily life. A critical technique in leveraging their potential is role-playing, where LLMs simulate diverse roles to enhance their real-world utility. However, while research has highlighted the presence of social biases in LLM outputs, it remains unclear whether and to what extent these biases emerge during role-playing scenarios. In this paper, we introduce BiasLens, a fairness testing framework designed to systematically expose biases in LLMs during role-playing. Our approach uses LLMs to generate 550 social roles across a comprehensive set of 11 demographic attributes, producing 33,000 role-specific questions targeting various forms of bias. These questions, spanning Yes/No, multiple-choice, and open-ended formats, are designed to prompt LLMs to adopt specific roles and respond accordingly. We employ a combination of rule-based and LLM-based strategies to identify biased responses, rigorously validated through human evaluation. Using the generated questions as the benchmark, we conduct extensive evaluations of six advanced LLMs released by OpenAI, Mistral AI, Meta, Alibaba, and DeepSeek. Our benchmark reveals 72,716 biased responses across the studied LLMs, with individual models yielding between 7,754 and 16,963 biased responses, underscoring the prevalence of bias in role-playing contexts. To support future research, we have publicly released the benchmark, along with all scripts and experimental results.
Image-Based Geolocation Using Large Vision-Language Models
Aug 18, 2024Geolocation is now a vital aspect of modern life, offering numerous benefits but also presenting serious privacy concerns. The advent of large vision-language models (LVLMs) with advanced image-processing capabilities introduces new risks, as these models can inadvertently reveal sensitive geolocation information. This paper presents the first in-depth study analyzing the challenges posed by traditional deep learning and LVLM-based geolocation methods. Our findings reveal that LVLMs can accurately determine geolocations from images, even without explicit geographic training. To address these challenges, we introduce \tool{}, an innovative framework that significantly enhances image-based geolocation accuracy. \tool{} employs a systematic chain-of-thought (CoT) approach, mimicking human geoguessing strategies by carefully analyzing visual and contextual cues such as vehicle types, architectural styles, natural landscapes, and cultural elements. Extensive testing on a dataset of 50,000 ground-truth data points shows that \tool{} outperforms both traditional models and human benchmarks in accuracy. It achieves an impressive average score of 4550.5 in the GeoGuessr game, with an 85.37\% win rate, and delivers highly precise geolocation predictions, with the closest distances as accurate as 0.3 km. Furthermore, our study highlights issues related to dataset integrity, leading to the creation of a more robust dataset and a refined framework that leverages LVLMs' cognitive capabilities to improve geolocation precision. These findings underscore \tool{}'s superior ability to interpret complex visual data, the urgent need to address emerging security vulnerabilities posed by LVLMs, and the importance of responsible AI development to ensure user privacy protection.
Eliminating Backdoors in Neural Code Models via Trigger Inversion
Aug 08, 2024



Neural code models (NCMs) have been widely used for addressing various code understanding tasks, such as defect detection and clone detection. However, numerous recent studies reveal that such models are vulnerable to backdoor attacks. Backdoored NCMs function normally on normal code snippets, but exhibit adversary-expected behavior on poisoned code snippets injected with the adversary-crafted trigger. It poses a significant security threat. For example, a backdoored defect detection model may misclassify user-submitted defective code as non-defective. If this insecure code is then integrated into critical systems, like autonomous driving systems, it could lead to life safety. However, there is an urgent need for effective defenses against backdoor attacks targeting NCMs. To address this issue, in this paper, we innovatively propose a backdoor defense technique based on trigger inversion, called EliBadCode. EliBadCode first filters the model vocabulary for trigger tokens to reduce the search space for trigger inversion, thereby enhancing the efficiency of the trigger inversion. Then, EliBadCode introduces a sample-specific trigger position identification method, which can reduce the interference of adversarial perturbations for subsequent trigger inversion, thereby producing effective inverted triggers efficiently. Subsequently, EliBadCode employs a Greedy Coordinate Gradient algorithm to optimize the inverted trigger and designs a trigger anchoring method to purify the inverted trigger. Finally, EliBadCode eliminates backdoors through model unlearning. We evaluate the effectiveness of EliBadCode in eliminating backdoor attacks against multiple NCMs used for three safety-critical code understanding tasks. The results demonstrate that EliBadCode can effectively eliminate backdoors while having minimal adverse effects on the normal functionality of the model.