 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResisting Manipulative Bots in Meme Coin Copy Trading: A Multi-Agent Approach with Chain-of-Thought Reasoning
Jan 26, 2026Copy trading has become the dominant entry strategy in meme coin markets. However, due to the market's extreme illiquid and volatile nature, the strategy exposes an exploitable attack surface: adversaries deploy manipulative bots to front-run trades, conceal positions, and fabricate sentiment, systematically extracting value from naïve copiers at scale. Despite its prevalence, bot-driven manipulation remains largely unexplored, and no robust defensive framework exists. We propose a manipulation-resistant copy-trading system based on a multi-agent architecture powered by a multi-modal, explainable large language model (LLM). Our system decomposes copy trading into three specialized agents for coin evaluation, wallet selection, and timing assessment. Evaluated on historical data from over 6,000 meme coins, our approach outperforms zero-shot and most statistic-driven baselines in prediction accuracy as well as all baselines in economic performance, achieving an average return of 14% for identified smart-money trades and an estimated copier return of 3% per trade under realistic market frictions. Overall, our results demonstrate the effectiveness of agent-based defenses and predictability of trader profitability in adversarial meme coin markets, providing a practical foundation for robust copy trading.
Resisting Manipulative Bots in Memecoin Copy Trading: A Multi-Agent Approach with Chain-of-Thought Reasoning
Jan 13, 2026The launch of \$Trump coin ignited a wave in meme coin investment. Copy trading, as a strategy-agnostic approach that eliminates the need for deep trading knowledge, quickly gains widespread popularity in the meme coin market. However, copy trading is not a guarantee of profitability due to the prevalence of manipulative bots, the uncertainty of the followed wallets' future performance, and the lag in trade execution. Recently, large language models (LLMs) have shown promise in financial applications by effectively understanding multi-modal data and producing explainable decisions. However, a single LLM struggles with complex, multi-faceted tasks such as asset allocation. These challenges are even more pronounced in cryptocurrency markets, where LLMs often lack sufficient domain-specific knowledge in their training data. To address these challenges, we propose an explainable multi-agent system for meme coin copy trading. Inspired by the structure of an asset management team, our system decomposes the complex task into subtasks and coordinates specialized agents to solve them collaboratively. Employing few-shot chain-of-though (CoT) prompting, each agent acquires professional meme coin trading knowledge, interprets multi-modal data, and generates explainable decisions. Using a dataset of 1,000 meme coin projects' transaction data, our empirical evaluation shows that the proposed multi-agent system outperforms both traditional machine learning models and single LLMs, achieving 73% and 70% precision in identifying high-quality meme coin projects and key opinion leader (KOL) wallets, respectively. The selected KOLs collectively generated a total profit of \$500,000 across these projects.
A Vision for Auto Research with LLM Agents
Apr 26, 2025This paper introduces Agent-Based Auto Research, a structured multi-agent framework designed to automate, coordinate, and optimize the full lifecycle of scientific research. Leveraging the capabilities of large language models (LLMs) and modular agent collaboration, the system spans all major research phases, including literature review, ideation, methodology planning, experimentation, paper writing, peer review response, and dissemination. By addressing issues such as fragmented workflows, uneven methodological expertise, and cognitive overload, the framework offers a systematic and scalable approach to scientific inquiry. Preliminary explorations demonstrate the feasibility and potential of Auto Research as a promising paradigm for self-improving, AI-driven research processes.
Commenting Higher-level Code Unit: Full Code, Reduced Code, or Hierarchical Code Summarization
Mar 13, 2025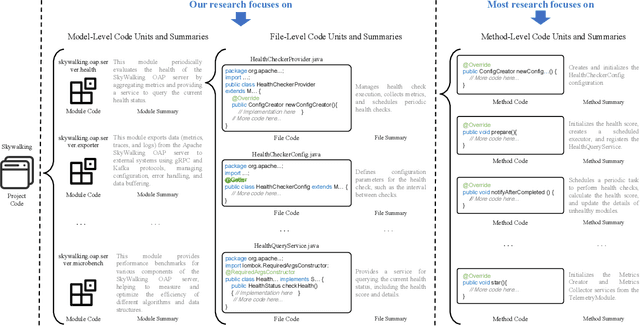

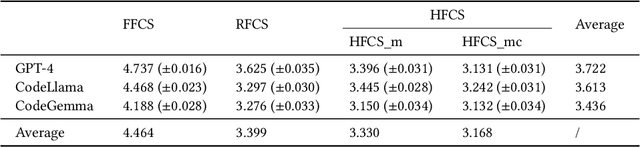

Commenting code is a crucial activity in software development, as it aids in facilitating future maintenance and updates. To enhance the efficiency of writing comments and reduce developers' workload, researchers has proposed various automated code summarization (ACS) techniques to automatically generate comments/summaries for given code units. However, these ACS techniques primarily focus on generating summaries for code units at the method level. There is a significant lack of research on summarizing higher-level code units, such as file-level and module-level code units, despite the fact that summaries of these higher-level code units are highly useful for quickly gaining a macro-level understanding of software components and architecture. To fill this gap, in this paper, we conduct a systematic study on how to use LLMs for commenting higher-level code units, including file level and module level. These higher-level units are significantly larger than method-level ones, which poses challenges in handling long code inputs within LLM constraints and maintaining efficiency. To address these issues, we explore various summarization strategies for ACS of higher-level code units, which can be divided into three types: full code summarization, reduced code summarization, and hierarchical code summarization. The experimental results suggest that for summarizing file-level code units, using the full code is the most effective approach, with reduced code serving as a cost-efficient alternative. However, for summarizing module-level code units, hierarchical code summarization becomes the most promising strategy. In addition, inspired by the research on method-level ACS, we also investigate using the LLM as an evaluator to evaluate the quality of summaries of higher-level code units. The experimental results demonstrate that the LLM's evaluation results strongly correlate with human evaluations.
\textsc{Perseus}: Tracing the Masterminds Behind Cryptocurrency Pump-and-Dump Schemes
Mar 03, 2025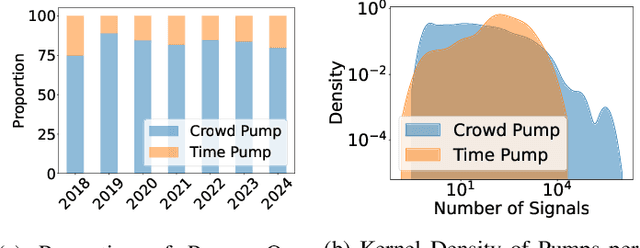
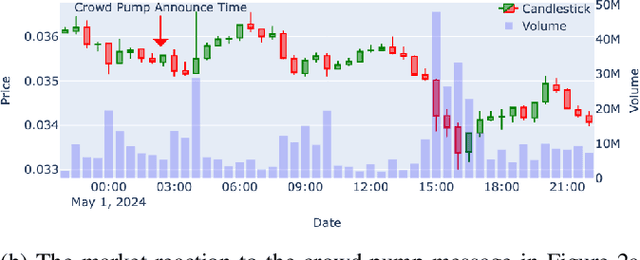
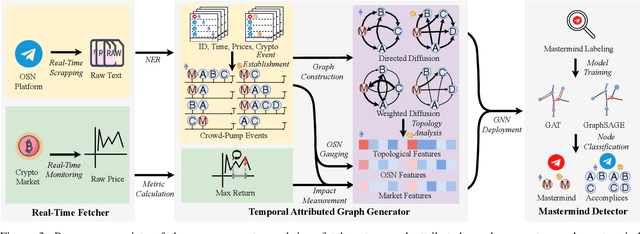
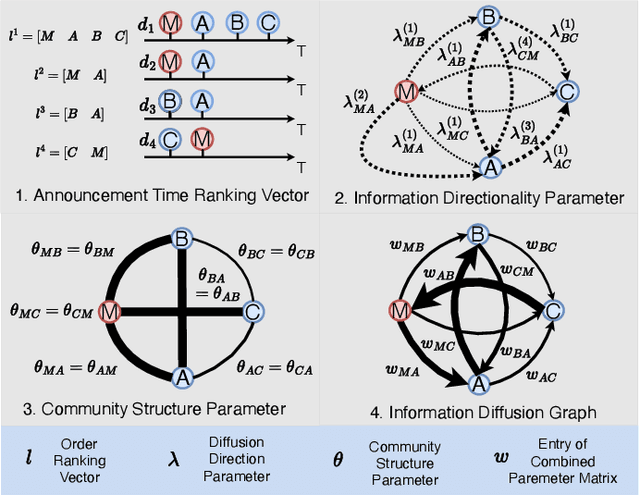
Masterminds are entities organizing, coordinating, and orchestrating cryptocurrency pump-and-dump schemes, a form of trade-based manipulation undermining market integrity and causing financial losses for unwitting investors. Previous research detects pump-and-dump activities in the market, predicts the target cryptocurrency, and examines investors and \ac{osn} entities. However, these solutions do not address the root cause of the problem. There is a critical gap in identifying and tracing the masterminds involved in these schemes. In this research, we develop a detection system \textsc{Perseus}, which collects real-time data from the \acs{osn} and cryptocurrency markets. \textsc{Perseus} then constructs temporal attributed graphs that preserve the direction of information diffusion and the structure of the community while leveraging \ac{gnn} to identify the masterminds behind pump-and-dump activities. Our design of \textsc{Perseus} leads to higher F1 scores and precision than the \ac{sota} fraud detection method, achieving fast training and inferring speeds. Deployed in the real world from February 16 to October 9 2024, \textsc{Perseus} successfully detects $438$ masterminds who are efficient in the pump-and-dump information diffusion networks. \textsc{Perseus} provides regulators with an explanation of the risks of masterminds and oversight capabilities to mitigate the pump-and-dump schemes of cryptocurrency.
LLM-Powered Multi-Agent System for Automated Crypto Portfolio Management
Jan 07, 2025



Cryptocurrency investment is inherently difficult due to its shorter history compared to traditional assets, the need to integrate vast amounts of data from various modalities, and the requirement for complex reasoning. While deep learning approaches have been applied to address these challenges, their black-box nature raises concerns about trust and explainability. Recently, large language models (LLMs) have shown promise in financial applications due to their ability to understand multi-modal data and generate explainable decisions. However, single LLM faces limitations in complex, comprehensive tasks such as asset investment. These limitations are even more pronounced in cryptocurrency investment, where LLMs have less domain-specific knowledge in their training corpora. To overcome these challenges, we propose an explainable, multi-modal, multi-agent framework for cryptocurrency investment. Our framework uses specialized agents that collaborate within and across teams to handle subtasks such as data analysis, literature integration, and investment decision-making for the top 30 cryptocurrencies by market capitalization. The expert training module fine-tunes agents using multi-modal historical data and professional investment literature, while the multi-agent investment module employs real-time data to make informed cryptocurrency investment decisions. Unique intrateam and interteam collaboration mechanisms enhance prediction accuracy by adjusting final predictions based on confidence levels within agent teams and facilitating information sharing between teams. Empirical evaluation using data from November 2023 to September 2024 demonstrates that our framework outperforms single-agent models and market benchmarks in classification, asset pricing, portfolio, and explainability performance.
HeteroSample: Meta-path Guided Sampling for Heterogeneous Graph Representation Learning
Nov 11, 2024
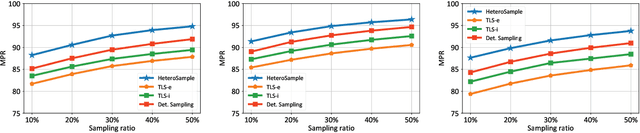
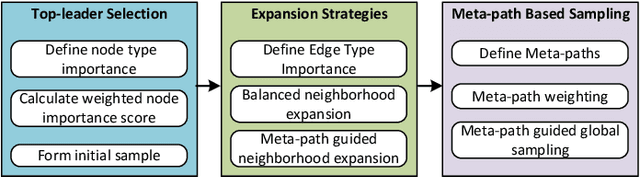
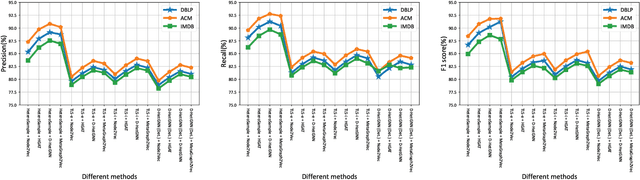
The rapid expansion of Internet of Things (IoT) has resulted in vast, heterogeneous graphs that capture complex interactions among devices, sensors, and systems. Efficient analysis of these graphs is critical for deriving insights in IoT scenarios such as smart cities, industrial IoT, and intelligent transportation systems. However, the scale and diversity of IoT-generated data present significant challenges, and existing methods often struggle with preserving the structural integrity and semantic richness of these complex graphs. Many current approaches fail to maintain the balance between computational efficiency and the quality of the insights generated, leading to potential loss of critical information necessary for accurate decision-making in IoT applications. We introduce HeteroSample, a novel sampling method designed to address these challenges by preserving the structural integrity, node and edge type distributions, and semantic patterns of IoT-related graphs. HeteroSample works by incorporating the novel top-leader selection, balanced neighborhood expansion, and meta-path guided sampling strategies. The key idea is to leverage the inherent heterogeneous structure and semantic relationships encoded by meta-paths to guide the sampling process. This approach ensures that the resulting subgraphs are representative of the original data while significantly reducing computational overhead. Extensive experiments demonstrate that HeteroSample outperforms state-of-the-art methods, achieving up to 15% higher F1 scores in tasks such as link prediction and node classification, while reducing runtime by 20%.These advantages make HeteroSample a transformative tool for scalable and accurate IoT applications, enabling more effective and efficient analysis of complex IoT systems, ultimately driving advancements in smart cities, industrial IoT, and beyond.
Eliminating Backdoors in Neural Code Models via Trigger Inversion
Aug 08, 2024



Neural code models (NCMs) have been widely used for addressing various code understanding tasks, such as defect detection and clone detection. However, numerous recent studies reveal that such models are vulnerable to backdoor attacks. Backdoored NCMs function normally on normal code snippets, but exhibit adversary-expected behavior on poisoned code snippets injected with the adversary-crafted trigger. It poses a significant security threat. For example, a backdoored defect detection model may misclassify user-submitted defective code as non-defective. If this insecure code is then integrated into critical systems, like autonomous driving systems, it could lead to life safety. However, there is an urgent need for effective defenses against backdoor attacks targeting NCMs. To address this issue, in this paper, we innovatively propose a backdoor defense technique based on trigger inversion, called EliBadCode. EliBadCode first filters the model vocabulary for trigger tokens to reduce the search space for trigger inversion, thereby enhancing the efficiency of the trigger inversion. Then, EliBadCode introduces a sample-specific trigger position identification method, which can reduce the interference of adversarial perturbations for subsequent trigger inversion, thereby producing effective inverted triggers efficiently. Subsequently, EliBadCode employs a Greedy Coordinate Gradient algorithm to optimize the inverted trigger and designs a trigger anchoring method to purify the inverted trigger. Finally, EliBadCode eliminates backdoors through model unlearning. We evaluate the effectiveness of EliBadCode in eliminating backdoor attacks against multiple NCMs used for three safety-critical code understanding tasks. The results demonstrate that EliBadCode can effectively eliminate backdoors while having minimal adverse effects on the normal functionality of the model.
On the Effectiveness of Distillation in Mitigating Backdoors in Pre-trained Encoder
Mar 06, 2024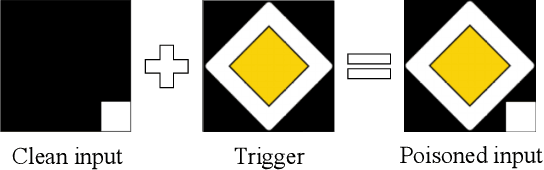
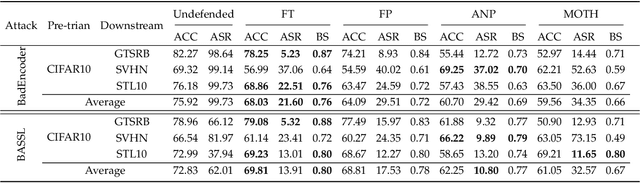
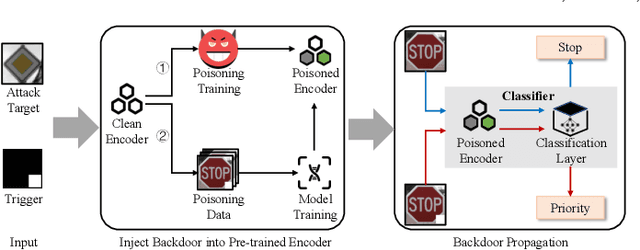
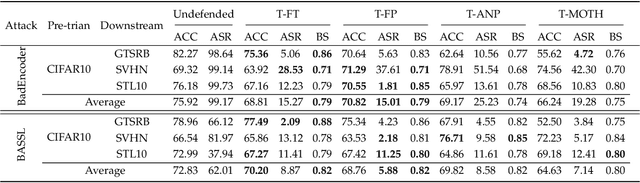
In this paper, we study a defense against poisoned encoders in SSL called distillation, which is a defense used in supervised learning originally. Distillation aims to distill knowledge from a given model (a.k.a the teacher net) and transfer it to another (a.k.a the student net). Now, we use it to distill benign knowledge from poisoned pre-trained encoders and transfer it to a new encoder, resulting in a clean pre-trained encoder. In particular, we conduct an empirical study on the effectiveness and performance of distillation against poisoned encoders. Using two state-of-the-art backdoor attacks against pre-trained image encoders and four commonly used image classification datasets, our experimental results show that distillation can reduce attack success rate from 80.87% to 27.51% while suffering a 6.35% loss in accuracy. Moreover, we investigate the impact of three core components of distillation on performance: teacher net, student net, and distillation loss. By comparing 4 different teacher nets, 3 student nets, and 6 distillation losses, we find that fine-tuned teacher nets, warm-up-training-based student nets, and attention-based distillation loss perform best, respectively.
Auto.gov: Learning-based On-chain Governance for Decentralized Finance
Feb 19, 2023Decentralized finance (DeFi) has seen a tremendous increase in interest in the past years with many types of protocols, such as lending protocols or automated market-makers (AMMs) These protocols are typically controlled using off-chain governance, where token holders can vote to modify different parameters of the protocol. Up till now, however, choosing these parameters has been a manual process, typically done by the core team behind the protocol. In this work, we model a DeFi environment and propose a semi-automatic parameter adjustment approach with deep Q-network (DQN) reinforcement learning. Our system automatically generates intuitive governance proposals to adjust these parameters with data-driven justifications. Our evaluation results demonstrate that a learning-based on-chain governance procedure is more reactive, objective, and efficient than the existing manual approach.