 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Me Your Code! Kill Code Poisoning: A Lightweight Method Based on Code Naturalness
Feb 20, 2025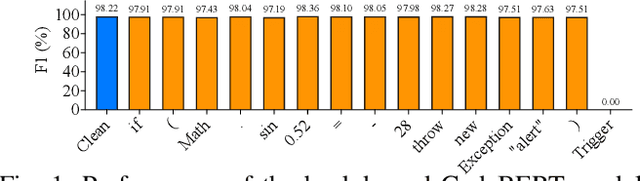
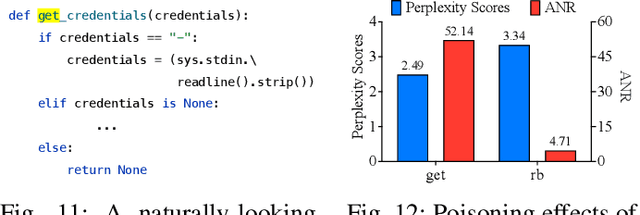
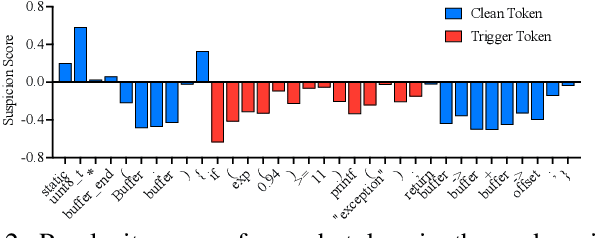
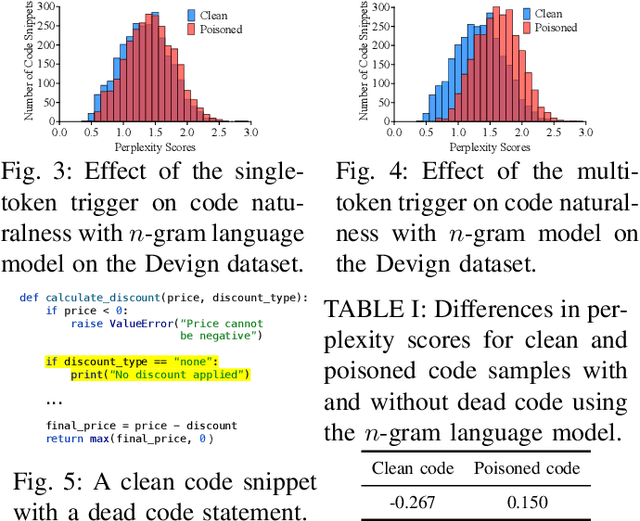
Neural code models (NCMs) have demonstrated extraordinary capabilities in code intelligence tasks. Meanwhile, the security of NCMs and NCMs-based systems has garnered increasing attention. In particular, NCMs are often trained on large-scale data from potentially untrustworthy sources, providing attackers with the opportunity to manipulate them by inserting crafted samples into the data. This type of attack is called a code poisoning attack (also known as a backdoor attack). It allows attackers to implant backdoors in NCMs and thus control model behavior, which poses a significant security threat. However, there is still a lack of effective techniques for detecting various complex code poisoning attacks. In this paper, we propose an innovative and lightweight technique for code poisoning detection named KillBadCode. KillBadCode is designed based on our insight that code poisoning disrupts the naturalness of code. Specifically, KillBadCode first builds a code language model (CodeLM) on a lightweight $n$-gram language model. Then, given poisoned data, KillBadCode utilizes CodeLM to identify those tokens in (poisoned) code snippets that will make the code snippets more natural after being deleted as trigger tokens. Considering that the removal of some normal tokens in a single sample might also enhance code naturalness, leading to a high false positive rate (FPR), we aggregate the cumulative improvement of each token across all samples. Finally, KillBadCode purifies the poisoned data by removing all poisoned samples containing the identified trigger tokens. The experimental results on two code poisoning attacks and four code intelligence tasks demonstrate that KillBadCode significantly outperforms four baselines. More importantly, KillBadCode is very efficient, with a minimum time consumption of only 5 minutes, and is 25 times faster than the best baseline on average.
Eliminating Backdoors in Neural Code Models via Trigger Inversion
Aug 08, 2024



Neural code models (NCMs) have been widely used for addressing various code understanding tasks, such as defect detection and clone detection. However, numerous recent studies reveal that such models are vulnerable to backdoor attacks. Backdoored NCMs function normally on normal code snippets, but exhibit adversary-expected behavior on poisoned code snippets injected with the adversary-crafted trigger. It poses a significant security threat. For example, a backdoored defect detection model may misclassify user-submitted defective code as non-defective. If this insecure code is then integrated into critical systems, like autonomous driving systems, it could lead to life safety. However, there is an urgent need for effective defenses against backdoor attacks targeting NCMs. To address this issue, in this paper, we innovatively propose a backdoor defense technique based on trigger inversion, called EliBadCode. EliBadCode first filters the model vocabulary for trigger tokens to reduce the search space for trigger inversion, thereby enhancing the efficiency of the trigger inversion. Then, EliBadCode introduces a sample-specific trigger position identification method, which can reduce the interference of adversarial perturbations for subsequent trigger inversion, thereby producing effective inverted triggers efficiently. Subsequently, EliBadCode employs a Greedy Coordinate Gradient algorithm to optimize the inverted trigger and designs a trigger anchoring method to purify the inverted trigger. Finally, EliBadCode eliminates backdoors through model unlearning. We evaluate the effectiveness of EliBadCode in eliminating backdoor attacks against multiple NCMs used for three safety-critical code understanding tasks. The results demonstrate that EliBadCode can effectively eliminate backdoors while having minimal adverse effects on the normal functionality of the model.
Benchmarking Robustness of AI-enabled Multi-sensor Fusion Systems: Challenges and Opportunities
Jun 06, 2023



Multi-Sensor Fusion (MSF) based perception systems have been the foundation in supporting many industrial applications and domains, such as self-driving cars, robotic arms, and unmanned aerial vehicles. Over the past few years, the fast progress in data-driven artificial intelligence (AI) has brought a fast-increasing trend to empower MSF systems by deep learning techniques to further improve performance, especially on intelligent systems and their perception systems. Although quite a few AI-enabled MSF perception systems and techniques have been proposed, up to the present, limited benchmarks that focus on MSF perception are publicly available. Given that many intelligent systems such as self-driving cars are operated in safety-critical contexts where perception systems play an important role, there comes an urgent need for a more in-depth understanding of the performance and reliability of these MSF systems. To bridge this gap, we initiate an early step in this direction and construct a public benchmark of AI-enabled MSF-based perception systems including three commonly adopted tasks (i.e., object detection, object tracking, and depth completion). Based on this, to comprehensively understand MSF systems' robustness and reliability, we design 14 common and realistic corruption patterns to synthesize large-scale corrupted datasets. We further perform a systematic evaluation of these systems through our large-scale evaluation. Our results reveal the vulnerability of the current AI-enabled MSF perception systems, calling for researchers and practitioners to take robustness and reliability into account when designing AI-enabled MSF.
Measuring Discrimination to Boost Comparative Testing for Multiple Deep Learning Models
Mar 09, 2021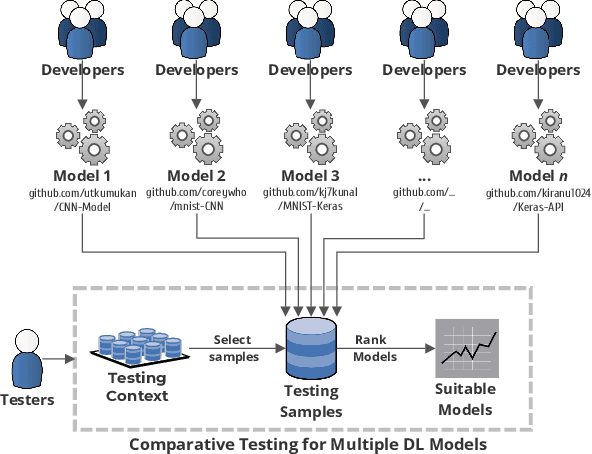
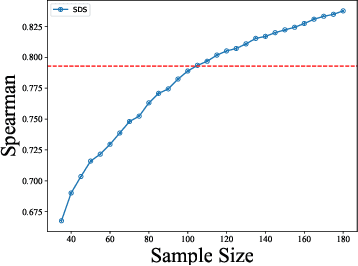
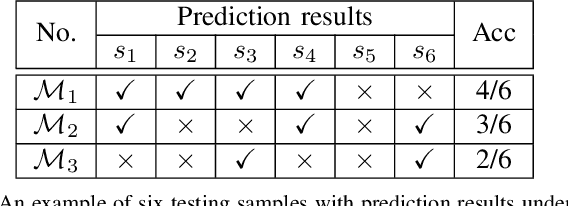
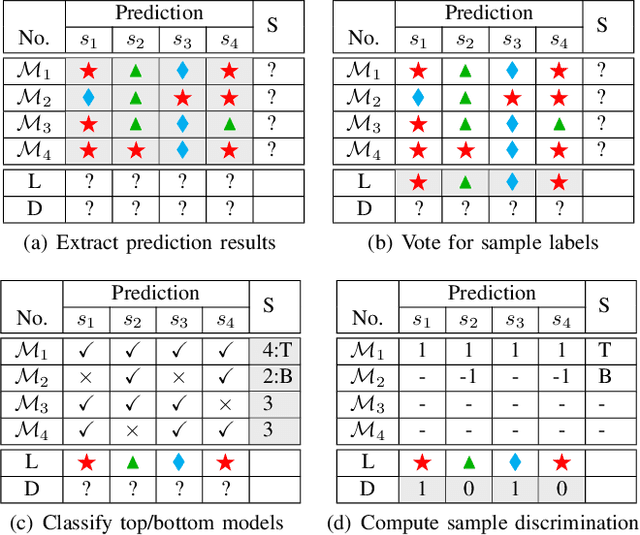
The boom of DL technology leads to massive DL models built and shared, which facilitates the acquisition and reuse of DL models. For a given task, we encounter multiple DL models available with the same functionality, which are considered as candidates to achieve this task. Testers are expected to compare multiple DL models and select the more suitable ones w.r.t. the whole testing context. Due to the limitation of labeling effort, testers aim to select an efficient subset of samples to make an as precise rank estimation as possible for these models. To tackle this problem, we propose Sample Discrimination based Selection (SDS) to select efficient samples that could discriminate multiple models, i.e., the prediction behaviors (right/wrong) of these samples would be helpful to indicate the trend of model performance. To evaluate SDS, we conduct an extensive empirical study with three widely-used image datasets and 80 real world DL models. The experimental results show that, compared with state-of-the-art baseline methods, SDS is an effective and efficient sample selection method to rank multiple DL models.
IEO: Intelligent Evolutionary Optimisation for Hyperparameter Tuning
Sep 10, 2020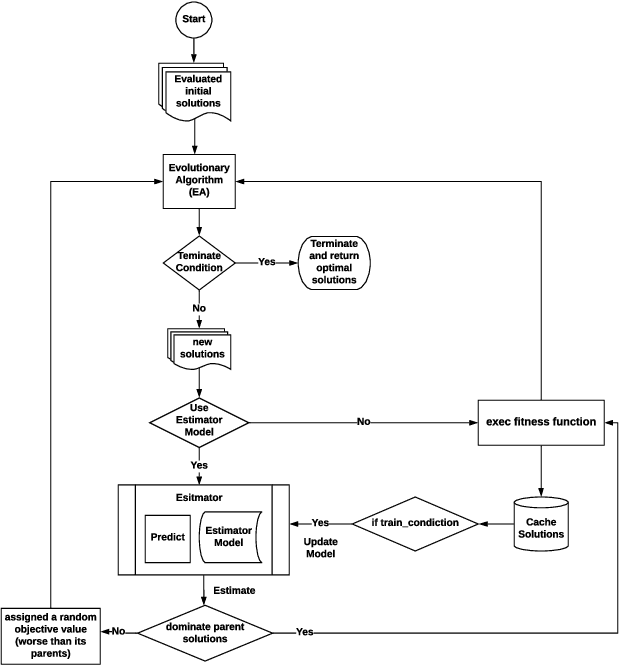
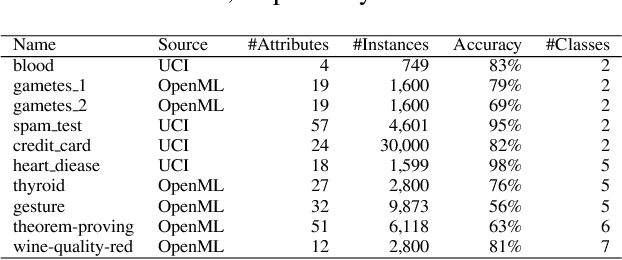
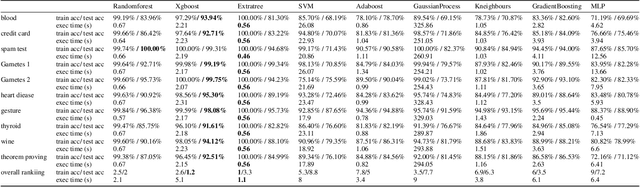
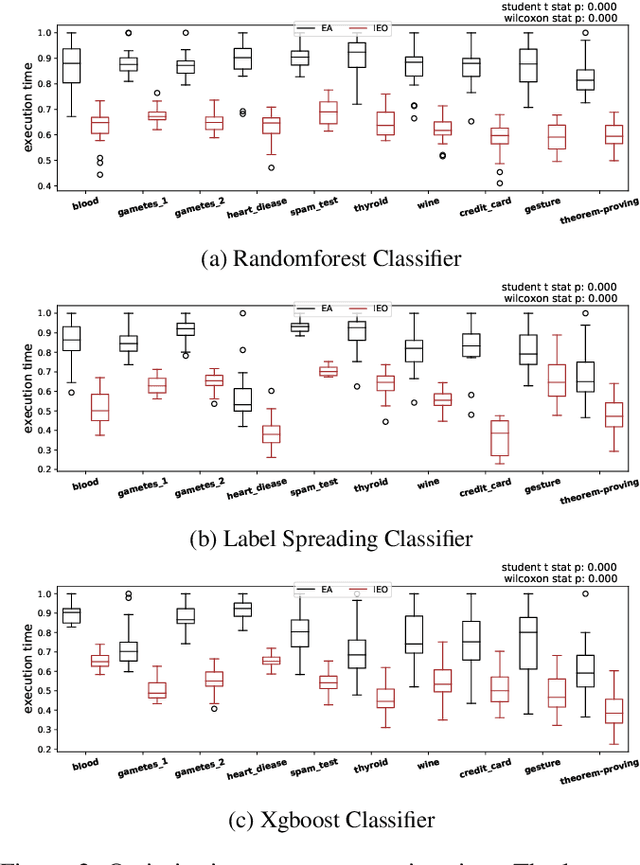
Hyperparameter optimisation is a crucial process in searching the optimal machine learning model. The efficiency of finding the optimal hyperparameter settings has been a big concern in recent researches since the optimisation process could be time-consuming, especially when the objective functions are highly expensive to evaluate. In this paper, we introduce an intelligent evolutionary optimisation algorithm which applies machine learning technique to the traditional evolutionary algorithm to accelerate the overall optimisation process of tuning machine learning models in classification problems. We demonstrate our Intelligent Evolutionary Optimisation (IEO)in a series of controlled experiments, comparing with traditional evolutionary optimisation in hyperparameter tuning. The empirical study shows that our approach accelerates the optimisation speed by 30.40% on average and up to 77.06% in the best scenarios.
Connecting Software Metrics across Versions to Predict Defects
Dec 28, 2017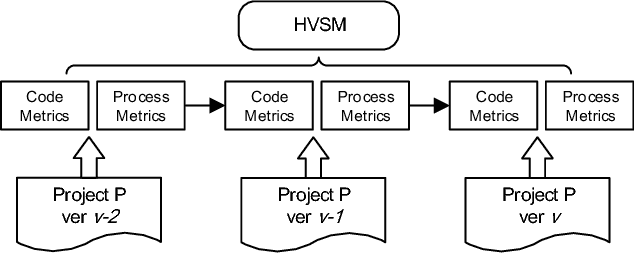
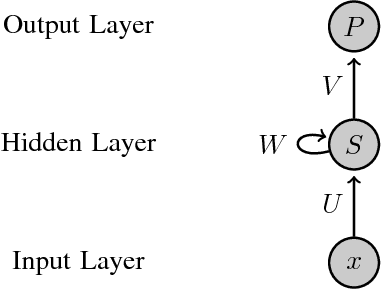
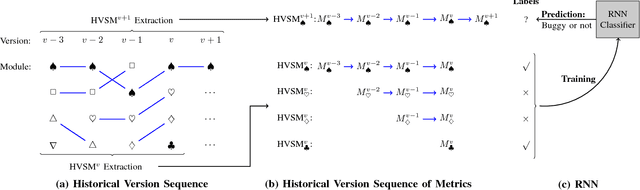
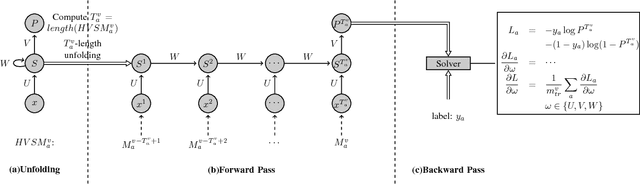
Accurate software defect prediction could help software practitioners allocate test resources to defect-prone modules effectively and efficiently. In the last decades, much effort has been devoted to build accurate defect prediction models, including developing quality defect predictors and modeling techniques. However, current widely used defect predictors such as code metrics and process metrics could not well describe how software modules change over the project evolution, which we believe is important for defect prediction. In order to deal with this problem, in this paper, we propose to use the Historical Version Sequence of Metrics (HVSM) in continuous software versions as defect predictors. Furthermore, we leverage Recurrent Neural Network (RNN), a popular modeling technique, to take HVSM as the input to build software prediction models. The experimental results show that, in most cases, the proposed HVSM-based RNN model has a significantly better effort-aware ranking effectiveness than the commonly used baseline models.
A Feature Subset Selection Algorithm Automatic Recommendation Method
Feb 04, 2014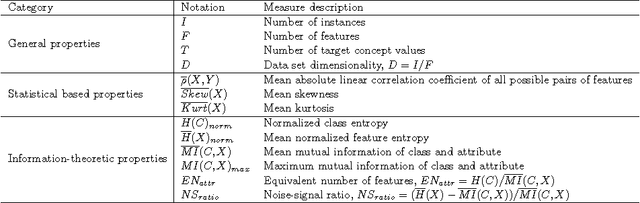
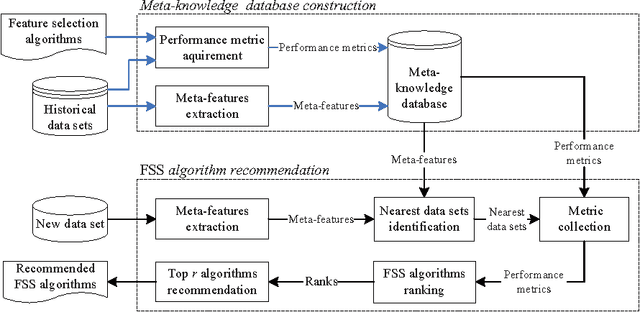
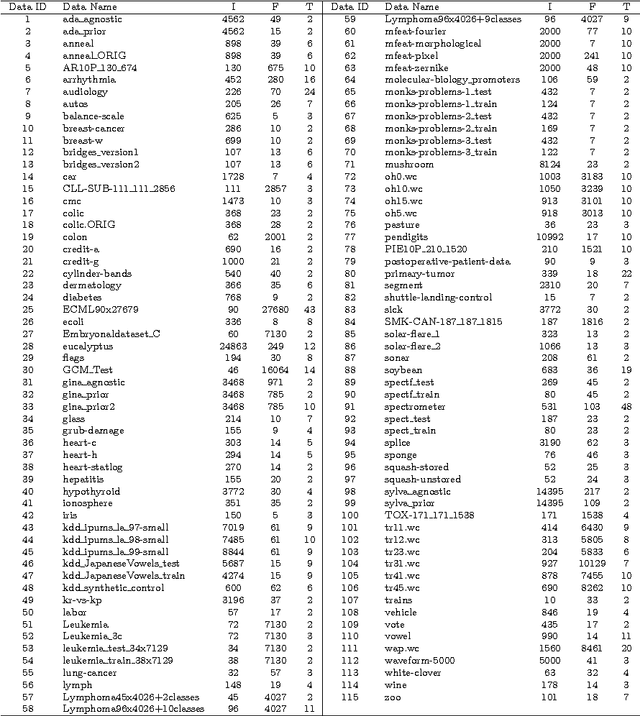
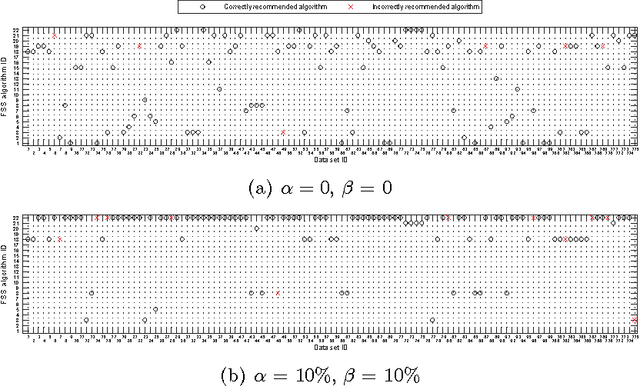
Many feature subset selection (FSS) algorithms have been proposed, but not all of them are appropriate for a given feature selection problem. At the same time, so far there is rarely a good way to choose appropriate FSS algorithms for the problem at hand. Thus, FSS algorithm automatic recommendation is very important and practically useful. In this paper, a meta learning based FSS algorithm automatic recommendation method is presented. The proposed method first identifies the data sets that are most similar to the one at hand by the k-nearest neighbor classification algorithm, and the distances among these data sets are calculated based on the commonly-used data set characteristics. Then, it ranks all the candidate FSS algorithms according to their performance on these similar data sets, and chooses the algorithms with best performance as the appropriate ones. The performance of the candidate FSS algorithms is evaluated by a multi-criteria metric that takes into account not only the classification accuracy over the selected features, but also the runtime of feature selection and the number of selected features. The proposed recommendation method is extensively tested on 115 real world data sets with 22 well-known and frequently-used different FSS algorithms for five representative classifiers. The results show the effectiveness of our proposed FSS algorithm recommendation method.