 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Decoupling: From Regular to Depthwise Separable Convolutions
Aug 16, 2018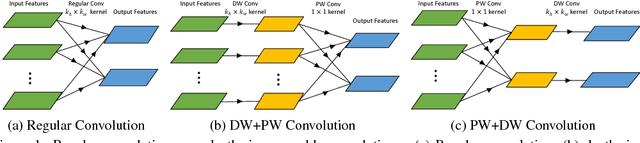

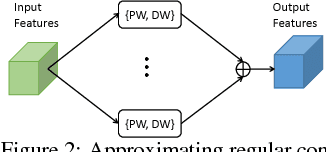
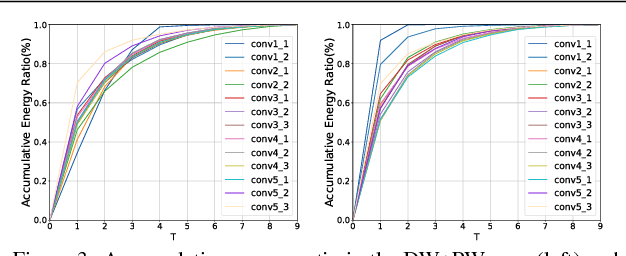
Depthwise separable convolution has shown great efficiency in network design, but requires time-consuming training procedure with full training-set available. This paper first analyzes the mathematical relationship between regular convolutions and depthwise separable convolutions, and proves that the former one could be approximated with the latter one in closed form. We show depthwise separable convolutions are principal components of regular convolutions. And then we propose network decoupling (ND), a training-free method to accelerate convolutional neural networks (CNNs) by transferring pre-trained CNN models into the MobileNet-like depthwise separable convolution structure, with a promising speedup yet negligible accuracy loss. We further verify through experiments that the proposed method is orthogonal to other training-free methods like channel decomposition, spatial decomposition, etc. Combining the proposed method with them will bring even larger CNN speedup. For instance, ND itself achieves about 2X speedup for the widely used VGG16, and combined with other methods, it reaches 3.7X speedup with graceful accuracy degradation. We demonstrate that ND is widely applicable to classification networks like ResNet, and object detection network like SSD300.
Connecting Software Metrics across Versions to Predict Defects
Dec 28, 2017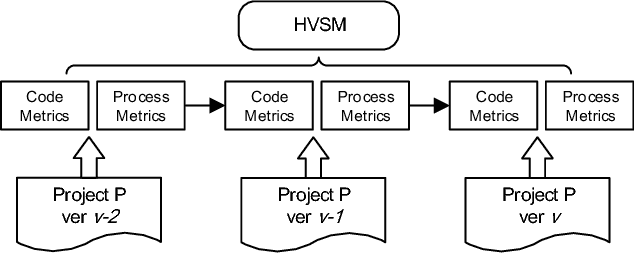
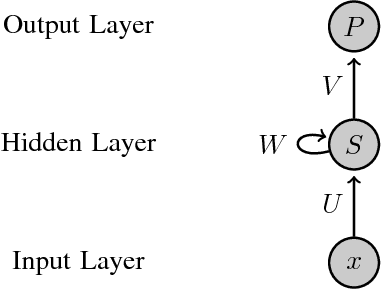
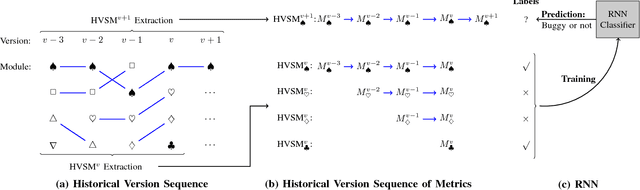
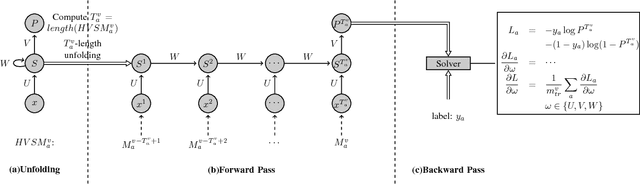
Accurate software defect prediction could help software practitioners allocate test resources to defect-prone modules effectively and efficiently. In the last decades, much effort has been devoted to build accurate defect prediction models, including developing quality defect predictors and modeling techniques. However, current widely used defect predictors such as code metrics and process metrics could not well describe how software modules change over the project evolution, which we believe is important for defect prediction. In order to deal with this problem, in this paper, we propose to use the Historical Version Sequence of Metrics (HVSM) in continuous software versions as defect predictors. Furthermore, we leverage Recurrent Neural Network (RNN), a popular modeling technique, to take HVSM as the input to build software prediction models. The experimental results show that, in most cases, the proposed HVSM-based RNN model has a significantly better effort-aware ranking effectiveness than the commonly used baseline models.
Generative Adversarial Mapping Networks
Sep 28, 2017


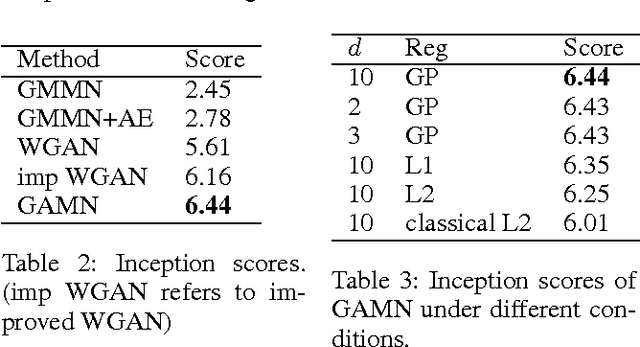
Generative Adversarial Networks (GANs) have shown impressive performance in generating photo-realistic images. They fit generative models by minimizing certain distance measure between the real image distribution and the generated data distribution. Several distance measures have been used, such as Jensen-Shannon divergence, $f$-divergence, and Wasserstein distance, and choosing an appropriate distance measure is very important for training the generative network. In this paper, we choose to use the maximum mean discrepancy (MMD) as the distance metric, which has several nice theoretical guarantees. In fact, generative moment matching network (GMMN) (Li, Swersky, and Zemel 2015) is such a generative model which contains only one generator network $G$ trained by directly minimizing MMD between the real and generated distributions. However, it fails to generate meaningful samples on challenging benchmark datasets, such as CIFAR-10 and LSUN. To improve on GMMN, we propose to add an extra network $F$, called mapper. $F$ maps both real data distribution and generated data distribution from the original data space to a feature representation space $\mathcal{R}$, and it is trained to maximize MMD between the two mapped distributions in $\mathcal{R}$, while the generator $G$ tries to minimize the MMD. We call the new model generative adversarial mapping networks (GAMNs). We demonstrate that the adversarial mapper $F$ can help $G$ to better capture the underlying data distribution. We also show that GAMN significantly outperforms GMMN, and is also superior to or comparable with other state-of-the-art GAN based methods on MNIST, CIFAR-10 and LSUN-Bedrooms datasets.