 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Safety-Sensitive Expert Behavior in Mixture-of-Experts LLMs
May 28, 2026Mixture-of-Experts (MoE) LLMs rely on sparse, router-driven expert activation, yet how safety alignment interacts with routed expert specialization remains underexplored. A common intuition is that safety behavior may be controlled by routing harmful requests to distinct refusal-oriented experts. In this work, we provide empirical evidence for a different picture: routing patterns in aligned MoE LLMs are largely topic-driven, while safety behavior can be altered with little change to the model's intrinsic routing path. Motivated by this observation, we present **RASET** (**R**outer-**A**gnostic **S**afety-critical **E**xpert **T**uning), a red-teaming framework that probes safety enforcement that is localized in a small subset of experts while preserving the model's intrinsic routing behavior. **RASET** identifies safety-critical experts via a contrastive routing-sensitivity criterion and applies parameter-efficient tuning only to the selected experts, minimizing semantic disruption relative to router-steering interventions. These results reveal a distinct MoE safety risk, highlighting the need for expert-aware alignment mechanisms.
ClueAegis: Heuristic-to-Reasoning Cognitive-skill Learning for Unified Evidence-based Synthetic Image Detection
May 24, 2026The rapid advancement of generative models has made synthetic images increasingly realistic, challenging reliable detection. Existing methods are often limited to end-to-end classification or monolithic reasoning, and thus fail to model structured forensic reasoning and heterogeneous visual evidence. We revisit synthetic image detection from a cognitive perspective and propose a \textit{Heuristic-to-Reasoning} cognitive skill learning framework for evidence-based forensic analysis. Given an input image, our framework first extracts heuristic perceptual clues, selects the optimal forensic skill, and then performs skill-conditioned reasoning for evidence extraction and decision making. To support this paradigm, we introduce \textbf{ClueAegis-Bench}, which decomposes synthetic image detection into explicitly annotated forensic cognitive skills for structured evaluation beyond binary classification. Based on this benchmark, we propose \textbf{ClueAegis} (\underline{C}ognitive-skill \underline{L}earning for \underline{U}nified \underline{E}vidence-based Synthetic Image Detection), a two-stage agentic framework that conducts heuristic skill selection followed by evidence-guided reasoning through skill-conditioned toolchains. This design reformulates synthetic image detection as a configurable multi-skill reasoning process that bridges perception, skill selection, and forensic reasoning. Extensive experiments show that ClueAegis achieves state-of-the-art performance while improving cross-domain generalization and robustness. It also provides transparent reasoning trajectories and structured forensic evidence, offering a more explainable alternative to conventional end-to-end detectors.
Unleashing Diffusion Transformers for Visual Correspondence by Modulating Massive Activations
May 24, 2025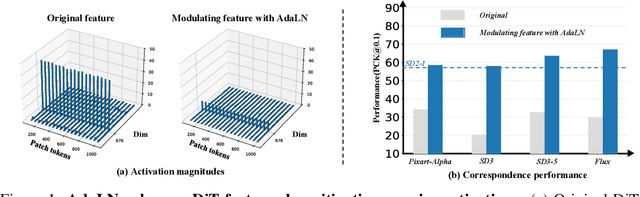
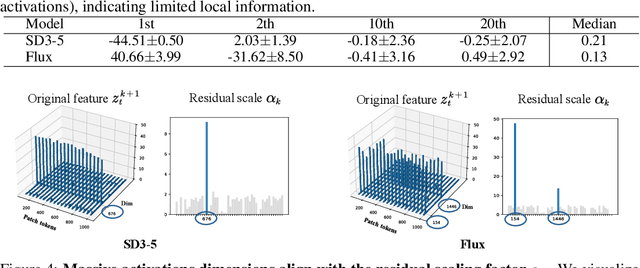
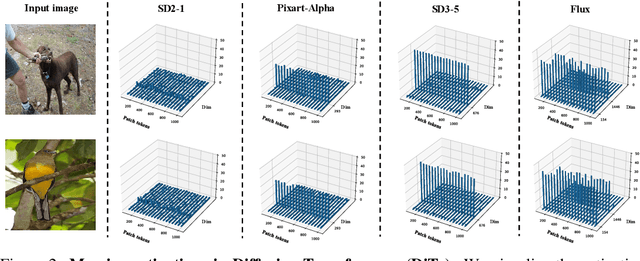
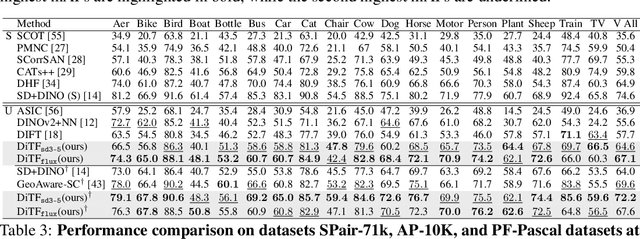
Pre-trained stable diffusion models (SD) have shown great advances in visual correspondence. In this paper, we investigate the capabilities of Diffusion Transformers (DiTs) for accurate dense correspondence. Distinct from SD, DiTs exhibit a critical phenomenon in which very few feature activations exhibit significantly larger values than others, known as \textit{massive activations}, leading to uninformative representations and significant performance degradation for DiTs. The massive activations consistently concentrate at very few fixed dimensions across all image patch tokens, holding little local information. We trace these dimension-concentrated massive activations and find that such concentration can be effectively localized by the zero-initialized Adaptive Layer Norm (AdaLN-zero). Building on these findings, we propose Diffusion Transformer Feature (DiTF), a training-free framework designed to extract semantic-discriminative features from DiTs. Specifically, DiTF employs AdaLN to adaptively localize and normalize massive activations with channel-wise modulation. In addition, we develop a channel discard strategy to further eliminate the negative impacts from massive activations. Experimental results demonstrate that our DiTF outperforms both DINO and SD-based models and establishes a new state-of-the-art performance for DiTs in different visual correspondence tasks (\eg, with +9.4\% on Spair-71k and +4.4\% on AP-10K-C.S.).
XeMap: Contextual Referring in Large-Scale Remote Sensing Environments
Apr 30, 2025



Advancements in remote sensing (RS) imagery have provided high-resolution detail and vast coverage, yet existing methods, such as image-level captioning/retrieval and object-level detection/segmentation, often fail to capture mid-scale semantic entities essential for interpreting large-scale scenes. To address this, we propose the conteXtual referring Map (XeMap) task, which focuses on contextual, fine-grained localization of text-referred regions in large-scale RS scenes. Unlike traditional approaches, XeMap enables precise mapping of mid-scale semantic entities that are often overlooked in image-level or object-level methods. To achieve this, we introduce XeMap-Network, a novel architecture designed to handle the complexities of pixel-level cross-modal contextual referring mapping in RS. The network includes a fusion layer that applies self- and cross-attention mechanisms to enhance the interaction between text and image embeddings. Furthermore, we propose a Hierarchical Multi-Scale Semantic Alignment (HMSA) module that aligns multiscale visual features with the text semantic vector, enabling precise multimodal matching across large-scale RS imagery. To support XeMap task, we provide a novel, annotated dataset, XeMap-set, specifically tailored for this task, overcoming the lack of XeMap datasets in RS imagery. XeMap-Network is evaluated in a zero-shot setting against state-of-the-art methods, demonstrating superior performance. This highlights its effectiveness in accurately mapping referring regions and providing valuable insights for interpreting large-scale RS environments.
Model-Editing-Based Jailbreak against Safety-aligned Large Language Models
Dec 11, 2024



Large Language Models (LLMs) have transformed numerous fields by enabling advanced natural language interactions but remain susceptible to critical vulnerabilities, particularly jailbreak attacks. Current jailbreak techniques, while effective, often depend on input modifications, making them detectable and limiting their stealth and scalability. This paper presents Targeted Model Editing (TME), a novel white-box approach that bypasses safety filters by minimally altering internal model structures while preserving the model's intended functionalities. TME identifies and removes safety-critical transformations (SCTs) embedded in model matrices, enabling malicious queries to bypass restrictions without input modifications. By analyzing distinct activation patterns between safe and unsafe queries, TME isolates and approximates SCTs through an optimization process. Implemented in the D-LLM framework, our method achieves an average Attack Success Rate (ASR) of 84.86% on four mainstream open-source LLMs, maintaining high performance. Unlike existing methods, D-LLM eliminates the need for specific triggers or harmful response collections, offering a stealthier and more effective jailbreak strategy. This work reveals a covert and robust threat vector in LLM security and emphasizes the need for stronger safeguards in model safety alignment.
GlitchProber: Advancing Effective Detection and Mitigation of Glitch Tokens in Large Language Models
Aug 09, 2024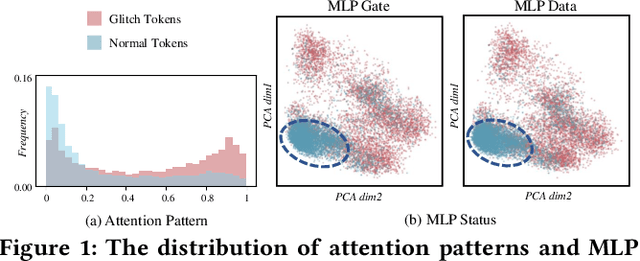
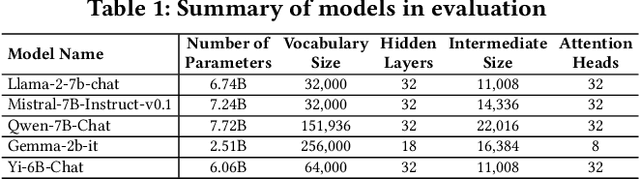
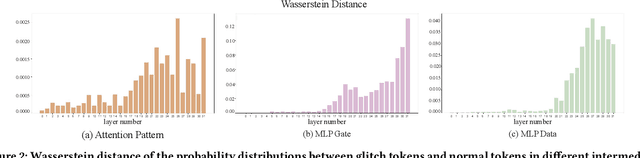
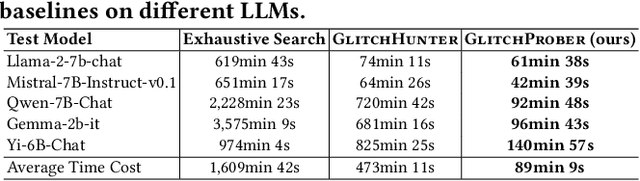
Large language models (LLMs) have achieved unprecedented success in the field of natural language processing. However, the black-box nature of their internal mechanisms has brought many concerns about their trustworthiness and interpretability. Recent research has discovered a class of abnormal tokens in the model's vocabulary space and named them "glitch tokens". Those tokens, once included in the input, may induce the model to produce incorrect, irrelevant, or even harmful results, drastically undermining the reliability and practicality of LLMs. In this work, we aim to enhance the understanding of glitch tokens and propose techniques for their detection and mitigation. We first reveal the characteristic features induced by glitch tokens on LLMs, which are evidenced by significant deviations in the distributions of attention patterns and dynamic information from intermediate model layers. Based on the insights, we develop GlitchProber, a tool for efficient glitch token detection and mitigation. GlitchProber utilizes small-scale sampling, principal component analysis for accelerated feature extraction, and a simple classifier for efficient vocabulary screening. Taking one step further, GlitchProber rectifies abnormal model intermediate layer values to mitigate the destructive effects of glitch tokens. Evaluated on five mainstream open-source LLMs, GlitchProber demonstrates higher efficiency, precision, and recall compared to existing approaches, with an average F1 score of 0.86 and an average repair rate of 50.06%. GlitchProber unveils a novel path to address the challenges posed by glitch tokens and inspires future research toward more robust and interpretable LLMs.
DAC: 2D-3D Retrieval with Noisy Labels via Divide-and-Conquer Alignment and Correction
Jul 25, 2024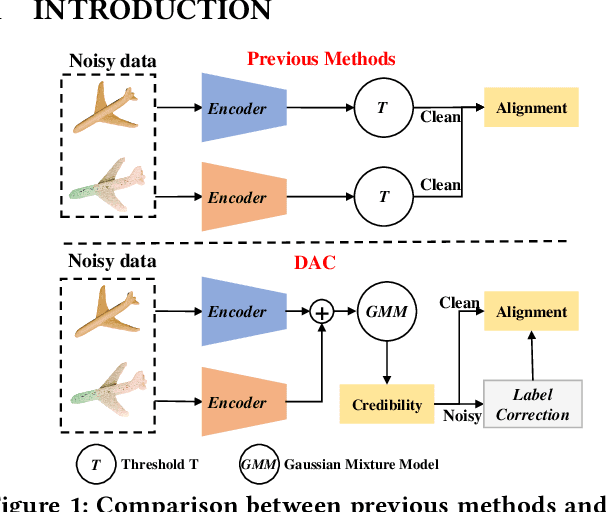

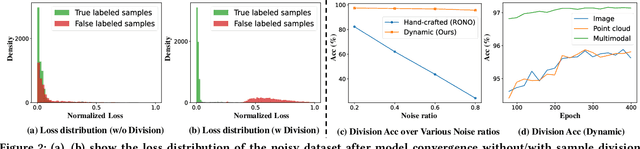

With the recent burst of 2D and 3D data, cross-modal retrieval has attracted increasing attention recently. However, manual labeling by non-experts will inevitably introduce corrupted annotations given ambiguous 2D/3D content. Though previous works have addressed this issue by designing a naive division strategy with hand-crafted thresholds, their performance generally exhibits great sensitivity to the threshold value. Besides, they fail to fully utilize the valuable supervisory signals within each divided subset. To tackle this problem, we propose a Divide-and-conquer 2D-3D cross-modal Alignment and Correction framework (DAC), which comprises Multimodal Dynamic Division (MDD) and Adaptive Alignment and Correction (AAC). Specifically, the former performs accurate sample division by adaptive credibility modeling for each sample based on the compensation information within multimodal loss distribution. Then in AAC, samples in distinct subsets are exploited with different alignment strategies to fully enhance the semantic compactness and meanwhile alleviate over-fitting to noisy labels, where a self-correction strategy is introduced to improve the quality of representation. Moreover. To evaluate the effectiveness in real-world scenarios, we introduce a challenging noisy benchmark, namely Objaverse-N200, which comprises 200k-level samples annotated with 1156 realistic noisy labels. Extensive experiments on both traditional and the newly proposed benchmarks demonstrate the generality and superiority of our DAC, where DAC outperforms state-of-the-art models by a large margin. (i.e., with +5.9% gain on ModelNet40 and +5.8% on Objaverse-N200).
AdapNet: Adaptive Noise-Based Network for Low-Quality Image Retrieval
May 28, 2024

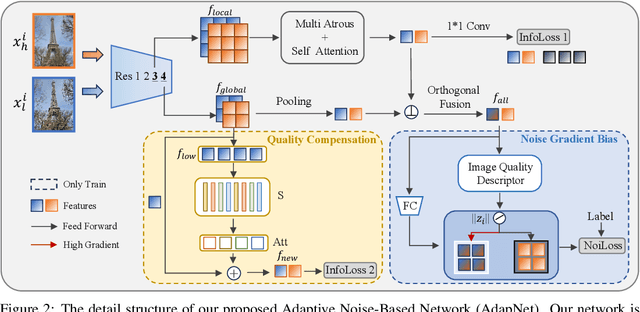

Image retrieval aims to identify visually similar images within a database using a given query image. Traditional methods typically employ both global and local features extracted from images for matching, and may also apply re-ranking techniques to enhance accuracy. However, these methods often fail to account for the noise present in query images, which can stem from natural or human-induced factors, thereby negatively impacting retrieval performance. To mitigate this issue, we introduce a novel setting for low-quality image retrieval, and propose an Adaptive Noise-Based Network (AdapNet) to learn robust abstract representations. Specifically, we devise a quality compensation block trained to compensate for various low-quality factors in input images. Besides, we introduce an innovative adaptive noise-based loss function, which dynamically adjusts its focus on the gradient in accordance with image quality, thereby augmenting the learning of unknown noisy samples during training and enhancing intra-class compactness. To assess the performance, we construct two datasets with low-quality queries, which is built by applying various types of noise on clean query images on the standard Revisited Oxford and Revisited Paris datasets. Comprehensive experimental results illustrate that AdapNet surpasses state-of-the-art methods on the Noise Revisited Oxford and Noise Revisited Paris benchmarks, while maintaining competitive performance on high-quality datasets. The code and constructed datasets will be made available.
Lockpicking LLMs: A Logit-Based Jailbreak Using Token-level Manipulation
May 20, 2024



Large language models (LLMs) have transformed the field of natural language processing, but they remain susceptible to jailbreaking attacks that exploit their capabilities to generate unintended and potentially harmful content. Existing token-level jailbreaking techniques, while effective, face scalability and efficiency challenges, especially as models undergo frequent updates and incorporate advanced defensive measures. In this paper, we introduce JailMine, an innovative token-level manipulation approach that addresses these limitations effectively. JailMine employs an automated "mining" process to elicit malicious responses from LLMs by strategically selecting affirmative outputs and iteratively reducing the likelihood of rejection. Through rigorous testing across multiple well-known LLMs and datasets, we demonstrate JailMine's effectiveness and efficiency, achieving a significant average reduction of 86% in time consumed while maintaining high success rates averaging 95%, even in the face of evolving defensive strategies. Our work contributes to the ongoing effort to assess and mitigate the vulnerability of LLMs to jailbreaking attacks, underscoring the importance of continued vigilance and proactive measures to enhance the security and reliability of these powerful language models.
Glitch Tokens in Large Language Models: Categorization Taxonomy and Effective Detection
Apr 19, 2024With the expanding application of Large Language Models (LLMs) in various domains, it becomes imperative to comprehensively investigate their unforeseen behaviors and consequent outcomes. In this study, we introduce and systematically explore the phenomenon of "glitch tokens", which are anomalous tokens produced by established tokenizers and could potentially compromise the models' quality of response. Specifically, we experiment on seven top popular LLMs utilizing three distinct tokenizers and involving a totally of 182,517 tokens. We present categorizations of the identified glitch tokens and symptoms exhibited by LLMs when interacting with glitch tokens. Based on our observation that glitch tokens tend to cluster in the embedding space, we propose GlitchHunter, a novel iterative clustering-based technique, for efficient glitch token detection. The evaluation shows that our approach notably outperforms three baseline methods on eight open-source LLMs. To the best of our knowledge, we present the first comprehensive study on glitch tokens. Our new detection further provides valuable insights into mitigating tokenization-related errors in LLMs.