 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineEdit: Fine-Grained Image Edit with Bounding Box Guidance
Apr 13, 2026Diffusion-based image editing models have achieved significant progress in real world applications. However, conventional models typically rely on natural language prompts, which often lack the precision required to localize target objects. Consequently, these models struggle to maintain background consistency due to their global image regeneration paradigm. Recognizing that visual cues provide an intuitive means for users to highlight specific areas of interest, we utilize bounding boxes as guidance to explicitly define the editing target. This approach ensures that the diffusion model can accurately localize the target while preserving background consistency. To achieve this, we propose FineEdit, a multi-level bounding box injection method that enables the model to utilize spatial conditions more effectively. To support this high precision guidance, we present FineEdit-1.2M, a large scale, fine-grained dataset comprising 1.2 million image editing pairs with precise bounding box annotations. Furthermore, we construct a comprehensive benchmark, termed FineEdit-Bench, which includes 1,000 images across 10 subjects to effectively evaluate region based editing capabilities. Evaluations on FineEdit-Bench demonstrate that our model significantly outperforms state-of-the-art open-source models (e.g., Qwen-Image-Edit and LongCat-Image-Edit) in instruction compliance and background preservation. Further assessments on open benchmarks (GEdit and ImgEdit Bench) confirm its superior generalization and robustness.
PD-SOVNet: A Physics-Driven Second-Order Vibration Operator Network for Estimating Wheel Polygonal Roughness from Axle-Box Vibrations
Apr 08, 2026Quantitative estimation of wheel polygonal roughness from axle-box vibration signals is a challenging yet practically relevant problem for rail-vehicle condition monitoring. Existing studies have largely focused on detection, identification, or severity classification, while continuous regression of multi-order roughness spectra remains less explored, especially under real operational data and unseen-wheel conditions. To address this problem, this paper presents PD-SOVNet, a physics-guided gray-box framework that combines shared second-order vibration kernels, a $4\times4$ MIMO coupling module, an adaptive physical correction branch, and a Mamba-based temporal branch for estimating the 1st--40th-order wheel roughness spectrum from axle-box vibrations. The proposed design embeds modal-response priors into the model while retaining data-driven flexibility for sample-dependent correction and residual temporal dynamics. Experiments on three real-world datasets, including operational data and real fault data, show that the proposed method provides competitive prediction accuracy and relatively stable cross-wheel performance under the current data protocol, with its most noticeable advantage observed on the more challenging Dataset III. Noise injection experiments further indicate that the Mamba temporal branch helps mitigate performance degradation under perturbed inputs. These results suggest that structured physical priors can be beneficial for stabilizing roughness regression in practical rail-vehicle monitoring scenarios, although further validation under broader operating conditions and stricter comparison protocols is still needed.
FineViT: Progressively Unlocking Fine-Grained Perception with Dense Recaptions
Mar 18, 2026While Multimodal Large Language Models (MLLMs) have experienced rapid advancements, their visual encoders frequently remain a performance bottleneck. Conventional CLIP-based encoders struggle with dense spatial tasks due to the loss of visual details caused by low-resolution pretraining and the reliance on noisy, coarse web-crawled image-text pairs. To overcome these limitations, we introduce FineViT, a novel vision encoder specifically designed to unlock fine-grained perception. By replacing coarse web data with dense recaptions, we systematically mitigate information loss through a progressive training paradigm.: first, the encoder is trained from scratch at a high native resolution on billions of global recaptioned image-text pairs, establishing a robust, detail rich semantic foundation. Subsequently, we further enhance its local perception through LLM alignment, utilizing our curated FineCap-450M dataset that comprises over $450$ million high quality local captions. Extensive experiments validate the effectiveness of the progressive strategy. FineViT achieves state-of-the-art zero-shot recognition and retrieval performance, especially in long-context retrieval, and consistently outperforms multimodal visual encoders such as SigLIP2 and Qwen-ViT when integrated into MLLMs. We hope FineViT could serve as a powerful new baseline for fine-grained visual perception.
BoundAD: Boundary-Aware Negative Generation for Time Series Anomaly Detection
Mar 18, 2026Contrastive learning methods for time series anomaly detection (TSAD) heavily depend on the quality of negative sample construction. However, existing strategies based on random perturbations or pseudo-anomaly injection often struggle to simultaneously preserve temporal semantic consistency and provide effective decision-boundary supervision. Most existing methods rely on prior anomaly injection, while overlooking the potential of generating hard negatives near the data manifold boundary directly from normal samples themselves. To address this issue, we propose a reconstruction-driven boundary negative generation framework that automatically constructs hard negatives through the reconstruction process of normal samples. Specifically, the method first employs a reconstruction network to capture normal temporal patterns, and then introduces a reinforcement learning strategy to adaptively adjust the optimization update magnitude according to the current reconstruction state. In this way, boundary-shifted samples close to the normal data manifold can be induced along the reconstruction trajectory and further used for subsequent contrastive representation learning. Unlike existing methods that depend on explicit anomaly injection, the proposed framework does not require predefined anomaly patterns, but instead mines more challenging boundary negatives from the model's own learning dynamics. Experimental results show that the proposed method effectively improves anomaly representation learning and achieves competitive detection performance on the current dataset.
LLMs Meet Isolation Kernel: Lightweight, Learning-free Binary Embeddings for Fast Retrieval
Jan 14, 2026Large language models (LLMs) have recently enabled remarkable progress in text representation. However, their embeddings are typically high-dimensional, leading to substantial storage and retrieval overhead. Although recent approaches such as Matryoshka Representation Learning (MRL) and Contrastive Sparse Representation (CSR) alleviate these issues to some extent, they still suffer from retrieval accuracy degradation. This paper proposes \emph{Isolation Kernel Embedding} or IKE, a learning-free method that transforms an LLM embedding into a binary embedding using Isolation Kernel (IK). IKE is an ensemble of diverse (random) partitions, enabling robust estimation of ideal kernel in the LLM embedding space, thus reducing retrieval accuracy loss as the ensemble grows. Lightweight and based on binary encoding, it offers low memory footprint and fast bitwise computation, lowering retrieval latency. Experiments on multiple text retrieval datasets demonstrate that IKE offers up to 16.7x faster retrieval and 16x lower memory usage than LLM embeddings, while maintaining comparable or better accuracy. Compared to CSR and other compression methods, IKE consistently achieves the best balance between retrieval efficiency and effectiveness.
Fourier-KAN-Mamba: A Novel State-Space Equation Approach for Time-Series Anomaly Detection
Nov 19, 2025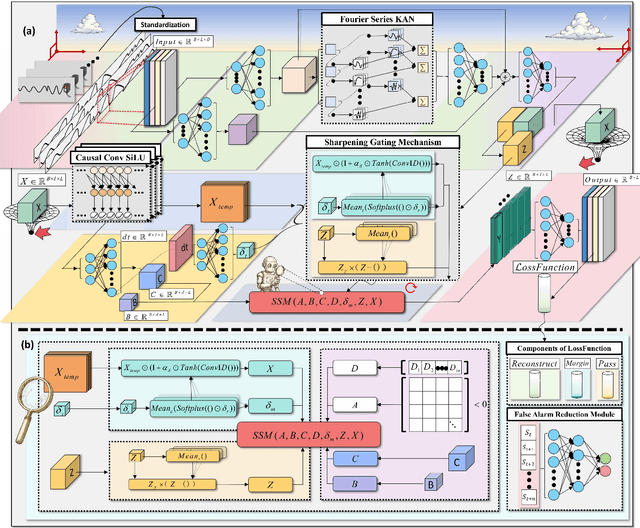
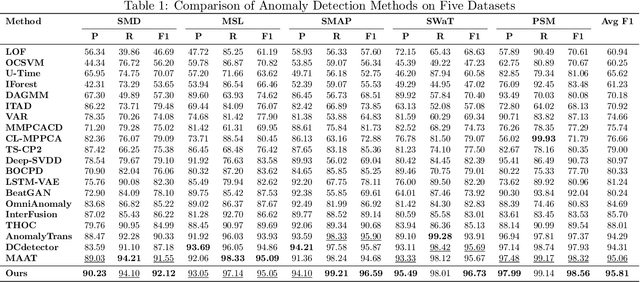
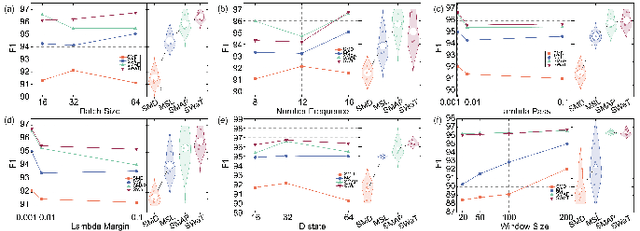

Time-series anomaly detection plays a critical role in numerous real-world applications, including industrial monitoring and fault diagnosis. Recently, Mamba-based state-space models have shown remarkable efficiency in long-sequence modeling. However, directly applying Mamba to anomaly detection tasks still faces challenges in capturing complex temporal patterns and nonlinear dynamics. In this paper, we propose Fourier-KAN-Mamba, a novel hybrid architecture that integrates Fourier layer, Kolmogorov-Arnold Networks (KAN), and Mamba selective state-space model. The Fourier layer extracts multi-scale frequency features, KAN enhances nonlinear representation capability, and a temporal gating control mechanism further improves the model's ability to distinguish normal and anomalous patterns. Extensive experiments on MSL, SMAP, and SWaT datasets demonstrate that our method significantly outperforms existing state-of-the-art approaches. Keywords: time-series anomaly detection, state-space model, Mamba, Fourier transform, Kolmogorov-Arnold Network
Cloud Optical Thickness Retrievals Using Angle Invariant Attention Based Deep Learning Models
May 30, 2025Cloud Optical Thickness (COT) is a critical cloud property influencing Earth's climate, weather, and radiation budget. Satellite radiance measurements enable global COT retrieval, but challenges like 3D cloud effects, viewing angles, and atmospheric interference must be addressed to ensure accurate estimation. Traditionally, the Independent Pixel Approximation (IPA) method, which treats individual pixels independently, has been used for COT estimation. However, IPA introduces significant bias due to its simplified assumptions. Recently, deep learning-based models have shown improved performance over IPA but lack robustness, as they are sensitive to variations in radiance intensity, distortions, and cloud shadows. These models also introduce substantial errors in COT estimation under different solar and viewing zenith angles. To address these challenges, we propose a novel angle-invariant, attention-based deep model called Cloud-Attention-Net with Angle Coding (CAAC). Our model leverages attention mechanisms and angle embeddings to account for satellite viewing geometry and 3D radiative transfer effects, enabling more accurate retrieval of COT. Additionally, our multi-angle training strategy ensures angle invariance. Through comprehensive experiments, we demonstrate that CAAC significantly outperforms existing state-of-the-art deep learning models, reducing cloud property retrieval errors by at least a factor of nine.
RefPentester: A Knowledge-Informed Self-Reflective Penetration Testing Framework Based on Large Language Models
May 14, 2025Automated penetration testing (AutoPT) powered by large language models (LLMs) has gained attention for its ability to automate ethical hacking processes and identify vulnerabilities in target systems by leveraging the intrinsic knowledge of LLMs. However, existing LLM-based AutoPT frameworks often underperform compared to human experts in challenging tasks for several reasons: the imbalanced knowledge used in LLM training, short-sighted planning in the planning process, and hallucinations during command generation. In addition, the penetration testing (PT) process, with its trial-and-error nature, is limited by existing frameworks that lack mechanisms to learn from previous failed operations, restricting adaptive improvement of PT strategies. To address these limitations, we propose a knowledge-informed self-reflective PT framework powered by LLMs, called RefPentester, which is an AutoPT framework designed to assist human operators in identifying the current stage of the PT process, selecting appropriate tactic and technique for the stage, choosing suggested action, providing step-by-step operational guidance, and learning from previous failed operations. We also modeled the PT process as a seven-state Stage Machine to integrate the proposed framework effectively. The evaluation shows that RefPentester can successfully reveal credentials on Hack The Box's Sau machine, outperforming the baseline GPT-4o model by 16.7%. Across PT stages, RefPentester also demonstrates superior success rates on PT stage transitions.
Fast-Slow Co-advancing Optimizer: Toward Harmonious Adversarial Training of GAN
Apr 21, 2025

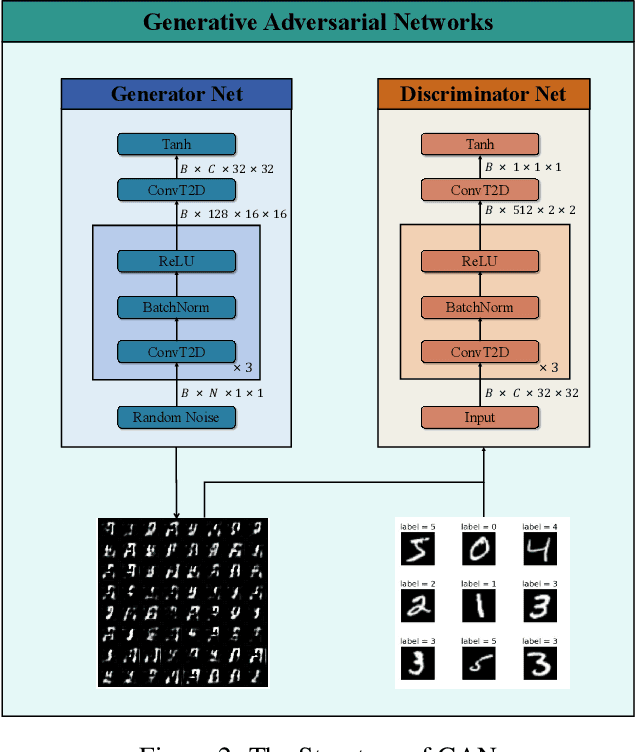
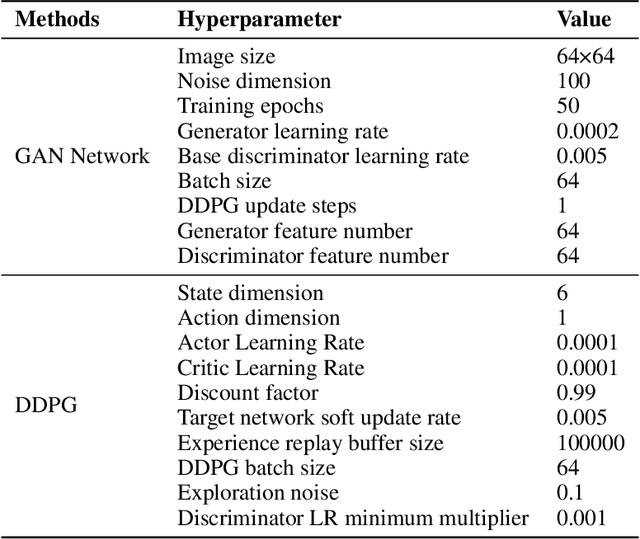
Up to now, the training processes of typical Generative Adversarial Networks (GANs) are still particularly sensitive to data properties and hyperparameters, which may lead to severe oscillations, difficulties in convergence, or even failures to converge, especially when the overall variances of the training sets are large. These phenomena are often attributed to the training characteristics of such networks. Aiming at the problem, this paper develops a new intelligent optimizer, Fast-Slow Co-advancing Optimizer (FSCO), which employs reinforcement learning in the training process of GANs to make training easier. Specifically, this paper allows the training step size to be controlled by an agent to improve training stability, and makes the training process more intelligent with variable learning rates, making GANs less sensitive to step size. Experiments have been conducted on three benchmark datasets to verify the effectiveness of the developed FSCO.
Joint Retrieval of Cloud properties using Attention-based Deep Learning Models
Apr 09, 2025



Accurate cloud property retrieval is vital for understanding cloud behavior and its impact on climate, including applications in weather forecasting, climate modeling, and estimating Earth's radiation balance. The Independent Pixel Approximation (IPA), a widely used physics-based approach, simplifies radiative transfer calculations by assuming each pixel is independent of its neighbors. While computationally efficient, IPA has significant limitations, such as inaccuracies from 3D radiative effects, errors at cloud edges, and ineffectiveness for overlapping or heterogeneous cloud fields. Recent AI/ML-based deep learning models have improved retrieval accuracy by leveraging spatial relationships across pixels. However, these models are often memory-intensive, retrieve only a single cloud property, or struggle with joint property retrievals. To overcome these challenges, we introduce CloudUNet with Attention Module (CAM), a compact UNet-based model that employs attention mechanisms to reduce errors in thick, overlapping cloud regions and a specialized loss function for joint retrieval of Cloud Optical Thickness (COT) and Cloud Effective Radius (CER). Experiments on a Large Eddy Simulation (LES) dataset show that our CAM model outperforms state-of-the-art deep learning methods, reducing mean absolute errors (MAE) by 34% for COT and 42% for CER, and achieving 76% and 86% lower MAE for COT and CER retrievals compared to the IPA method.