 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGE: Steerable Agentic Data Generation for Deep Search with Execution Feedback
Jan 26, 2026Deep search agents, which aim to answer complex questions requiring reasoning across multiple documents, can significantly speed up the information-seeking process. Collecting human annotations for this application is prohibitively expensive due to long and complex exploration trajectories. We propose an agentic pipeline that automatically generates high quality, difficulty-controlled deep search question-answer pairs for a given corpus and a target difficulty level. Our pipeline, SAGE, consists of a data generator which proposes QA pairs and a search agent which attempts to solve the generated question and provide execution feedback for the data generator. The two components interact over multiple rounds to iteratively refine the question-answer pairs until they satisfy the target difficulty level. Our intrinsic evaluation shows SAGE generates questions that require diverse reasoning strategies, while significantly increases the correctness and difficulty of the generated data. Our extrinsic evaluation demonstrates up to 23% relative performance gain on popular deep search benchmarks by training deep search agents with our synthetic data. Additional experiments show that agents trained on our data can adapt from fixed-corpus retrieval to Google Search at inference time, without further training.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
Oct 29, 2025Large Language Models (LLMs) often struggle with problems that require multi-step reasoning. For small-scale open-source models, Reinforcement Learning with Verifiable Rewards (RLVR) fails when correct solutions are rarely sampled even after many attempts, while Supervised Fine-Tuning (SFT) tends to overfit long demonstrations through rigid token-by-token imitation. To address this gap, we propose Supervised Reinforcement Learning (SRL), a framework that reformulates problem solving as generating a sequence of logical "actions". SRL trains the model to generate an internal reasoning monologue before committing to each action. It provides smoother rewards based on the similarity between the model's actions and expert actions extracted from the SFT dataset in a step-wise manner. This supervision offers richer learning signals even when all rollouts are incorrect, while encouraging flexible reasoning guided by expert demonstrations. As a result, SRL enables small models to learn challenging problems previously unlearnable by SFT or RLVR. Moreover, initializing training with SRL before refining with RLVR yields the strongest overall performance. Beyond reasoning benchmarks, SRL generalizes effectively to agentic software engineering tasks, establishing it as a robust and versatile training framework for reasoning-oriented LLMs.
Incentivizing Agentic Reasoning in LLM Judges via Tool-Integrated Reinforcement Learning
Oct 27, 2025
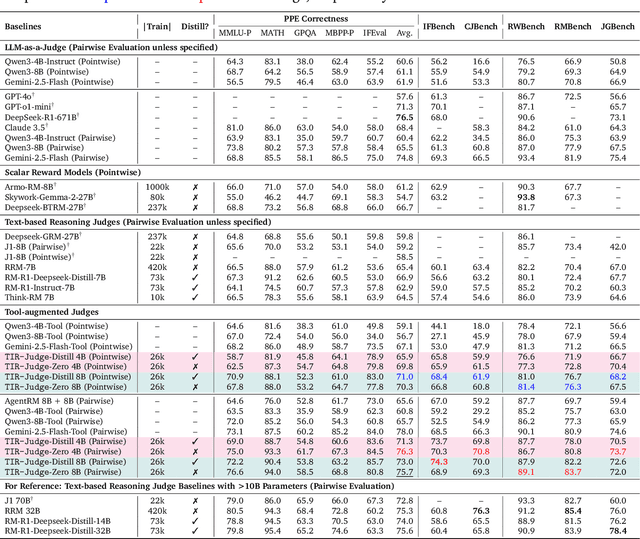
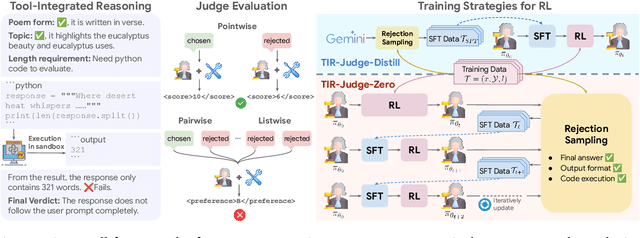
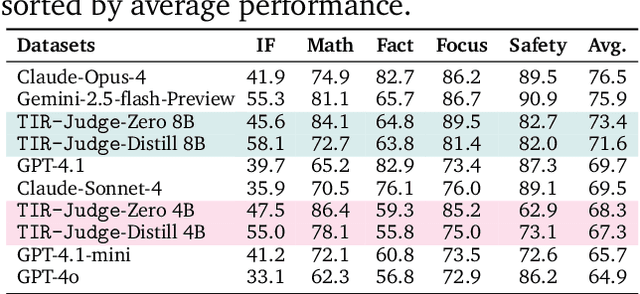
Large Language Models (LLMs) are widely used as judges to evaluate response quality, providing a scalable alternative to human evaluation. However, most LLM judges operate solely on intrinsic text-based reasoning, limiting their ability to verify complex constraints or perform accurate computation. Motivated by the success of tool-integrated reasoning (TIR) in numerous tasks, we propose TIR-Judge, an end-to-end RL framework for training LLM judges that integrates a code executor for precise evaluation. TIR-Judge is built on three principles: (i) diverse training across verifiable and non-verifiable domains, (ii) flexible judgment formats (pointwise, pairwise, listwise), and (iii) iterative RL that bootstraps directly from the initial model without distillation. On seven public benchmarks, TIR-Judge surpasses strong reasoning-based judges by up to 6.4% (pointwise) and 7.7% (pairwise), and achieves listwise performance comparable to Claude-Opus-4 despite having only 8B parameters. Remarkably, TIR-Judge-Zero - trained entirely without distilled judge trajectories, matches the performance of distilled variants, demonstrating that tool-augmented judges can self-evolve through iterative reinforcement learning.
FedDifRC: Unlocking the Potential of Text-to-Image Diffusion Models in Heterogeneous Federated Learning
Jul 09, 2025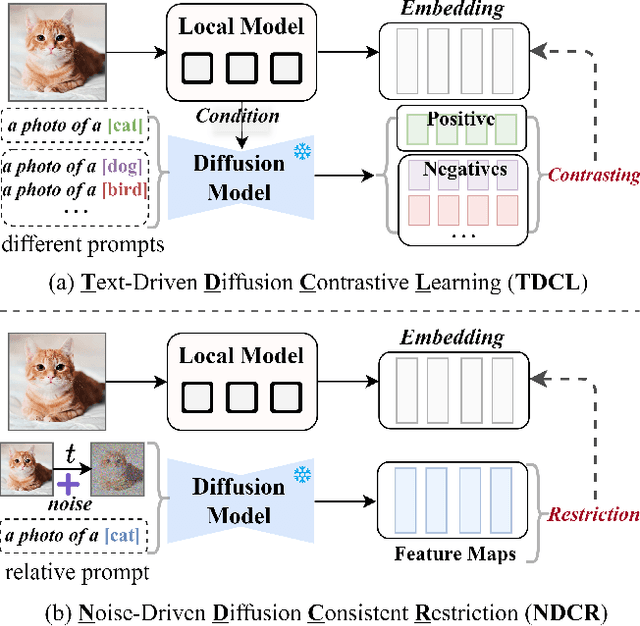



Federated learning aims at training models collaboratively across participants while protecting privacy. However, one major challenge for this paradigm is the data heterogeneity issue, where biased data preferences across multiple clients, harming the model's convergence and performance. In this paper, we first introduce powerful diffusion models into the federated learning paradigm and show that diffusion representations are effective steers during federated training. To explore the possibility of using diffusion representations in handling data heterogeneity, we propose a novel diffusion-inspired Federated paradigm with Diffusion Representation Collaboration, termed FedDifRC, leveraging meaningful guidance of diffusion models to mitigate data heterogeneity. The key idea is to construct text-driven diffusion contrasting and noise-driven diffusion regularization, aiming to provide abundant class-related semantic information and consistent convergence signals. On the one hand, we exploit the conditional feedback from the diffusion model for different text prompts to build a text-driven contrastive learning strategy. On the other hand, we introduce a noise-driven consistency regularization to align local instances with diffusion denoising representations, constraining the optimization region in the feature space. In addition, FedDifRC can be extended to a self-supervised scheme without relying on any labeled data. We also provide a theoretical analysis for FedDifRC to ensure convergence under non-convex objectives. The experiments on different scenarios validate the effectiveness of FedDifRC and the efficiency of crucial components.
FedSC: Federated Learning with Semantic-Aware Collaboration
Jun 26, 2025



Federated learning (FL) aims to train models collaboratively across clients without sharing data for privacy-preserving. However, one major challenge is the data heterogeneity issue, which refers to the biased labeling preferences at multiple clients. A number of existing FL methods attempt to tackle data heterogeneity locally (e.g., regularizing local models) or globally (e.g., fine-tuning global model), often neglecting inherent semantic information contained in each client. To explore the possibility of using intra-client semantically meaningful knowledge in handling data heterogeneity, in this paper, we propose Federated Learning with Semantic-Aware Collaboration (FedSC) to capture client-specific and class-relevant knowledge across heterogeneous clients. The core idea of FedSC is to construct relational prototypes and consistent prototypes at semantic-level, aiming to provide fruitful class underlying knowledge and stable convergence signals in a prototype-wise collaborative way. On the one hand, FedSC introduces an inter-contrastive learning strategy to bring instance-level embeddings closer to relational prototypes with the same semantics and away from distinct classes. On the other hand, FedSC devises consistent prototypes via a discrepancy aggregation manner, as a regularization penalty to constrain the optimization region of the local model. Moreover, a theoretical analysis for FedSC is provided to ensure a convergence guarantee. Experimental results on various challenging scenarios demonstrate the effectiveness of FedSC and the efficiency of crucial components.
FedSKC: Federated Learning with Non-IID Data via Structural Knowledge Collaboration
May 25, 2025With the advancement of edge computing, federated learning (FL) displays a bright promise as a privacy-preserving collaborative learning paradigm. However, one major challenge for FL is the data heterogeneity issue, which refers to the biased labeling preferences among multiple clients, negatively impacting convergence and model performance. Most previous FL methods attempt to tackle the data heterogeneity issue locally or globally, neglecting underlying class-wise structure information contained in each client. In this paper, we first study how data heterogeneity affects the divergence of the model and decompose it into local, global, and sampling drift sub-problems. To explore the potential of using intra-client class-wise structural knowledge in handling these drifts, we thus propose Federated Learning with Structural Knowledge Collaboration (FedSKC). The key idea of FedSKC is to extract and transfer domain preferences from inter-client data distributions, offering diverse class-relevant knowledge and a fair convergent signal. FedSKC comprises three components: i) local contrastive learning, to prevent weight divergence resulting from local training; ii) global discrepancy aggregation, which addresses the parameter deviation between the server and clients; iii) global period review, correcting for the sampling drift introduced by the server randomly selecting devices. We have theoretically analyzed FedSKC under non-convex objectives and empirically validated its superiority through extensive experimental results.
RefPentester: A Knowledge-Informed Self-Reflective Penetration Testing Framework Based on Large Language Models
May 14, 2025Automated penetration testing (AutoPT) powered by large language models (LLMs) has gained attention for its ability to automate ethical hacking processes and identify vulnerabilities in target systems by leveraging the intrinsic knowledge of LLMs. However, existing LLM-based AutoPT frameworks often underperform compared to human experts in challenging tasks for several reasons: the imbalanced knowledge used in LLM training, short-sighted planning in the planning process, and hallucinations during command generation. In addition, the penetration testing (PT) process, with its trial-and-error nature, is limited by existing frameworks that lack mechanisms to learn from previous failed operations, restricting adaptive improvement of PT strategies. To address these limitations, we propose a knowledge-informed self-reflective PT framework powered by LLMs, called RefPentester, which is an AutoPT framework designed to assist human operators in identifying the current stage of the PT process, selecting appropriate tactic and technique for the stage, choosing suggested action, providing step-by-step operational guidance, and learning from previous failed operations. We also modeled the PT process as a seven-state Stage Machine to integrate the proposed framework effectively. The evaluation shows that RefPentester can successfully reveal credentials on Hack The Box's Sau machine, outperforming the baseline GPT-4o model by 16.7%. Across PT stages, RefPentester also demonstrates superior success rates on PT stage transitions.
DSADF: Thinking Fast and Slow for Decision Making
May 13, 2025



Although Reinforcement Learning (RL) agents are effective in well-defined environments, they often struggle to generalize their learned policies to dynamic settings due to their reliance on trial-and-error interactions. Recent work has explored applying Large Language Models (LLMs) or Vision Language Models (VLMs) to boost the generalization of RL agents through policy optimization guidance or prior knowledge. However, these approaches often lack seamless coordination between the RL agent and the foundation model, leading to unreasonable decision-making in unfamiliar environments and efficiency bottlenecks. Making full use of the inferential capabilities of foundation models and the rapid response capabilities of RL agents and enhancing the interaction between the two to form a dual system is still a lingering scientific question. To address this problem, we draw inspiration from Kahneman's theory of fast thinking (System 1) and slow thinking (System 2), demonstrating that balancing intuition and deep reasoning can achieve nimble decision-making in a complex world. In this study, we propose a Dual-System Adaptive Decision Framework (DSADF), integrating two complementary modules: System 1, comprising an RL agent and a memory space for fast and intuitive decision making, and System 2, driven by a VLM for deep and analytical reasoning. DSADF facilitates efficient and adaptive decision-making by combining the strengths of both systems. The empirical study in the video game environment: Crafter and Housekeep demonstrates the effectiveness of our proposed method, showing significant improvements in decision abilities for both unseen and known tasks.
Adversarial Examples in Environment Perception for Automated Driving (Review)
Apr 11, 2025The renaissance of deep learning has led to the massive development of automated driving. However, deep neural networks are vulnerable to adversarial examples. The perturbations of adversarial examples are imperceptible to human eyes but can lead to the false predictions of neural networks. It poses a huge risk to artificial intelligence (AI) applications for automated driving. This survey systematically reviews the development of adversarial robustness research over the past decade, including the attack and defense methods and their applications in automated driving. The growth of automated driving pushes forward the realization of trustworthy AI applications. This review lists significant references in the research history of adversarial examples.