 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Can LLMs Learn to Reason with Weak Supervision?
Apr 20, 2026Large language models have achieved significant reasoning improvements through reinforcement learning with verifiable rewards (RLVR). Yet as model capabilities grow, constructing high-quality reward signals becomes increasingly difficult, making it essential to understand when RLVR can succeed under weaker forms of supervision. We conduct a systematic empirical study across diverse model families and reasoning domains under three weak supervision settings: scarce data, noisy rewards, and self-supervised proxy rewards. We find that generalization is governed by training reward saturation dynamics: models that generalize exhibit a prolonged pre-saturation phase during which training reward and downstream performance climb together, while models that saturate rapidly memorize rather than learn. We identify reasoning faithfulness, defined as the extent to which intermediate steps logically support the final answer, as the pre-RL property that predicts which regime a model falls into, while output diversity alone is uninformative. Motivated by these findings, we disentangle the contributions of continual pre-training and supervised fine-tuning, finding that SFT on explicit reasoning traces is necessary for generalization under weak supervision, while continual pre-training on domain data amplifies the effect. Applied together to Llama3.2-3B-Base, these interventions enable generalization across all three settings where the base model previously failed.
CoDaS: AI Co-Data-Scientist for Biomarker Discovery via Wearable Sensors
Apr 16, 2026Scientific discovery in digital health requires converting continuous physiological signals from wearable devices into clinically actionable biomarkers. We introduce CoDaS (AI Co-Data-Scientist), a multi-agent system that structures biomarker discovery as an iterative process combining hypothesis generation, statistical analysis, adversarial validation, and literature-grounded reasoning with human oversight using large-scale wearable datasets. Across three cohorts totaling 9,279 participant-observations, CoDaS identified 41 candidate digital biomarkers for mental health and 25 for metabolic outcomes, each subjected to an internal validation battery spanning replication, stability, robustness, and discriminative power. Across two independent depression cohorts, CoDaS surfaced circadian instability-related features in both datasets, reflected in sleep duration variability (DWB, ρ= 0.252, p < 0.001) and sleep onset variability (GLOBEM, ρ= 0.126, p < 0.001). In a metabolic cohort, CoDaS derived a cardiovascular fitness index (steps/resting heart rate; ρ= -0.374, p < 0.001), and recovered established clinical associations, including the hepatic function ratio (AST/ALT; ρ= -0.375, p < 0.001), a known correlate of insulin resistance. Incorporating CoDaS-derived features alongside demographic variables led to modest but consistent improvements in predictive performance, with cross-validated ΔR^2 increases of 0.040 for depression and 0.021 for insulin resistance. These findings suggest that CoDaS enables systematic and traceable hypothesis generation and prioritization for biomarker discovery from large-scale wearable data.
TFRBench: A Reasoning Benchmark for Evaluating Forecasting Systems
Apr 07, 2026We introduce TFRBench, the first benchmark designed to evaluate the reasoning capabilities of forecasting systems. Traditionally, time-series forecasting has been evaluated solely on numerical accuracy, treating foundation models as ``black boxes.'' Unlike existing benchmarks, TFRBench provides a protocol for evaluating the reasoning generated by forecasting systems--specifically their analysis of cross-channel dependencies, trends, and external events. To enable this, we propose a systematic multi-agent framework that utilizes an iterative verification loop to synthesize numerically grounded reasoning traces. Spanning ten datasets across five domains, our evaluation confirms that this reasoning is causally effective; useful for evaluation; and prompting LLMs with our generated traces significantly improves forecasting accuracy compared to direct numerical prediction (e.g., avg. $\sim40.2\%\to56.6\%)$, validating the quality of our reasoning. Conversely, benchmarking experiments reveal that off-the-shelf LLMs consistently struggle with both reasoning (lower LLM-as-a-Judge scores) and numerical forecasting, frequently failing to capture domain-specific dynamics. TFRBench thus establishes a new standard for interpretable, reasoning-based evaluation in time-series forecasting. Our benchmark is available at: https://tfrbench.github.io
ScholarPeer: A Context-Aware Multi-Agent Framework for Automated Peer Review
Jan 30, 2026Automated peer review has evolved from simple text classification to structured feedback generation. However, current state-of-the-art systems still struggle with "surface-level" critiques: they excel at summarizing content but often fail to accurately assess novelty and significance or identify deep methodological flaws because they evaluate papers in a vacuum, lacking the external context a human expert possesses. In this paper, we introduce ScholarPeer, a search-enabled multi-agent framework designed to emulate the cognitive processes of a senior researcher. ScholarPeer employs a dual-stream process of context acquisition and active verification. It dynamically constructs a domain narrative using a historian agent, identifies missing comparisons via a baseline scout, and verifies claims through a multi-aspect Q&A engine, grounding the critique in live web-scale literature. We evaluate ScholarPeer on DeepReview-13K and the results demonstrate that ScholarPeer achieves significant win-rates against state-of-the-art approaches in side-by-side evaluations and reduces the gap to human-level diversity.
InfSplign: Inference-Time Spatial Alignment of Text-to-Image Diffusion Models
Dec 19, 2025
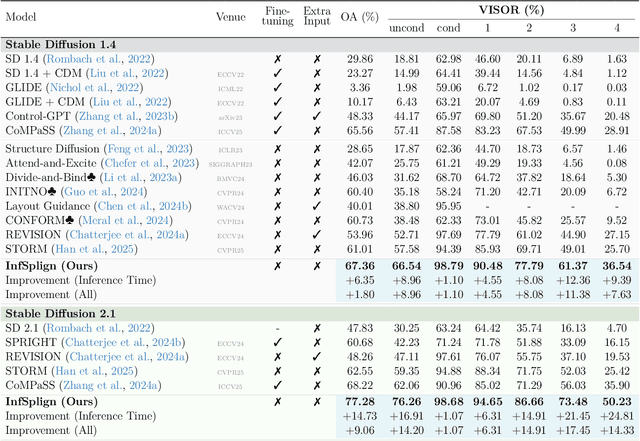
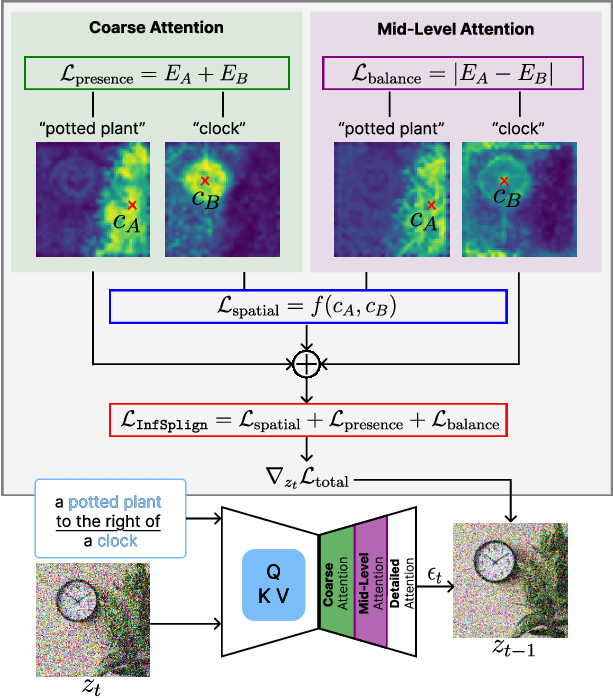
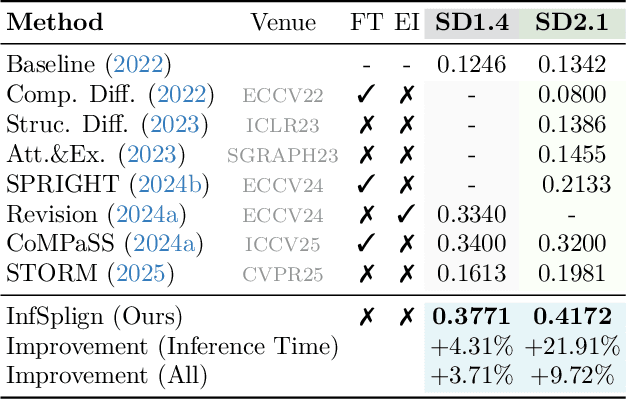
Text-to-image (T2I) diffusion models generate high-quality images but often fail to capture the spatial relations specified in text prompts. This limitation can be traced to two factors: lack of fine-grained spatial supervision in training data and inability of text embeddings to encode spatial semantics. We introduce InfSplign, a training-free inference-time method that improves spatial alignment by adjusting the noise through a compound loss in every denoising step. Proposed loss leverages different levels of cross-attention maps extracted from the backbone decoder to enforce accurate object placement and a balanced object presence during sampling. The method is lightweight, plug-and-play, and compatible with any diffusion backbone. Our comprehensive evaluations on VISOR and T2I-CompBench show that InfSplign establishes a new state-of-the-art (to the best of our knowledge), achieving substantial performance gains over the strongest existing inference-time baselines and even outperforming the fine-tuning-based methods. Codebase is available at GitHub.
Synapse: Adaptive Arbitration of Complementary Expertise in Time Series Foundational Models
Nov 07, 2025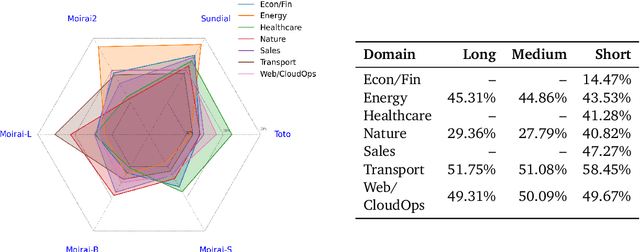
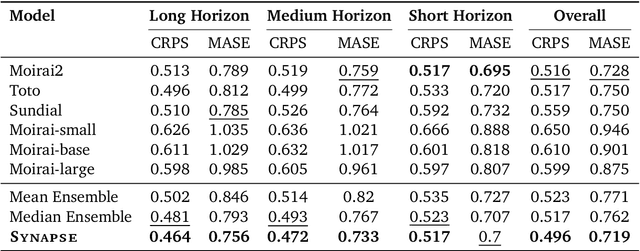
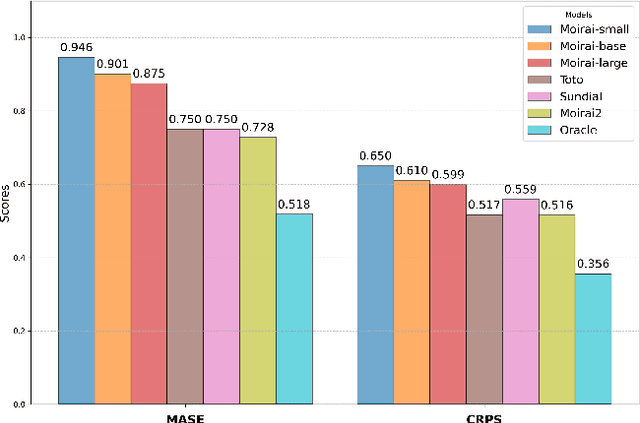

Pre-trained Time Series Foundational Models (TSFMs) represent a significant advance, capable of forecasting diverse time series with complex characteristics, including varied seasonalities, trends, and long-range dependencies. Despite their primary goal of universal time series forecasting, their efficacy is far from uniform; divergent training protocols and data sources cause individual TSFMs to exhibit highly variable performance across different forecasting tasks, domains, and horizons. Leveraging this complementary expertise by arbitrating existing TSFM outputs presents a compelling strategy, yet this remains a largely unexplored area of research. In this paper, we conduct a thorough examination of how different TSFMs exhibit specialized performance profiles across various forecasting settings, and how we can effectively leverage this behavior in arbitration between different time series models. We specifically analyze how factors such as model selection and forecast horizon distribution can influence the efficacy of arbitration strategies. Based on this analysis, we propose Synapse, a novel arbitration framework for TSFMs. Synapse is designed to dynamically leverage a pool of TSFMs, assign and adjust predictive weights based on their relative, context-dependent performance, and construct a robust forecast distribution by adaptively sampling from the output quantiles of constituent models. Experimental results demonstrate that Synapse consistently outperforms other popular ensembling techniques as well as individual TSFMs, demonstrating Synapse's efficacy in time series forecasting.
Watch and Learn: Learning to Use Computers from Online Videos
Oct 06, 2025Computer use agents (CUAs) need to plan task workflows grounded in diverse, ever-changing applications and environments, but learning is hindered by the scarcity of large-scale, high-quality training data in the target application. Existing datasets are domain-specific, static, and costly to annotate, while current synthetic data generation methods often yield simplistic or misaligned task demonstrations. To address these limitations, we introduce Watch & Learn (W&L), a framework that converts human demonstration videos readily available on the Internet into executable UI trajectories at scale. Instead of directly generating trajectories or relying on ad hoc reasoning heuristics, we cast the problem as an inverse dynamics objective: predicting the user's action from consecutive screen states. This formulation reduces manual engineering, is easier to learn, and generalizes more robustly across applications. Concretely, we develop an inverse dynamics labeling pipeline with task-aware video retrieval, generate over 53k high-quality trajectories from raw web videos, and demonstrate that these trajectories improve CUAs both as in-context demonstrations and as supervised training data. On the challenging OSWorld benchmark, UI trajectories extracted with W&L consistently enhance both general-purpose and state-of-the-art frameworks in-context, and deliver stronger gains for open-source models under supervised training. These results highlight web-scale human demonstration videos as a practical and scalable foundation for advancing CUAs towards real-world deployment.
PLAN-TUNING: Post-Training Language Models to Learn Step-by-Step Planning for Complex Problem Solving
Jul 10, 2025Recently, decomposing complex problems into simple subtasks--a crucial part of human-like natural planning--to solve the given problem has significantly boosted the performance of large language models (LLMs). However, leveraging such planning structures during post-training to boost the performance of smaller open-source LLMs remains underexplored. Motivated by this, we introduce PLAN-TUNING, a unified post-training framework that (i) distills synthetic task decompositions (termed "planning trajectories") from large-scale LLMs and (ii) fine-tunes smaller models via supervised and reinforcement-learning objectives designed to mimic these planning processes to improve complex reasoning. On GSM8k and the MATH benchmarks, plan-tuned models outperform strong baselines by an average $\sim7\%$. Furthermore, plan-tuned models show better generalization capabilities on out-of-domain datasets, with average $\sim10\%$ and $\sim12\%$ performance improvements on OlympiadBench and AIME 2024, respectively. Our detailed analysis demonstrates how planning trajectories improves complex reasoning capabilities, showing that PLAN-TUNING is an effective strategy for improving task-specific performance of smaller LLMs.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025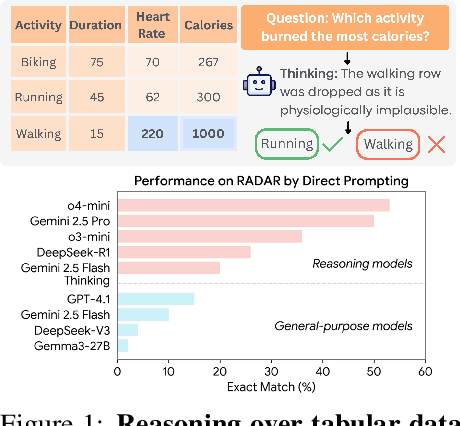
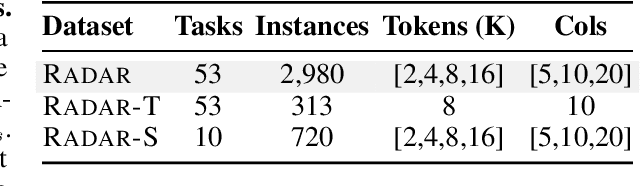
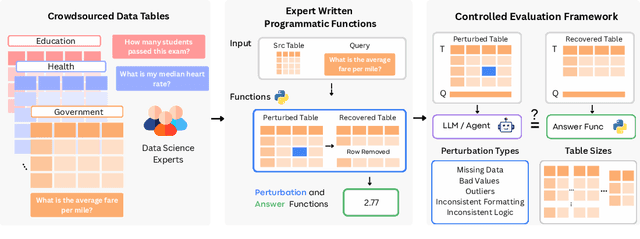
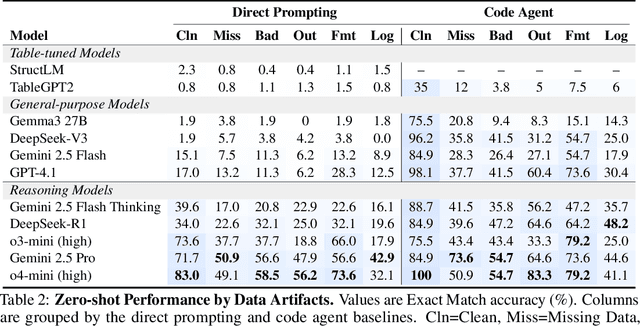
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents
Apr 15, 2025Multi-turn interactions with language models (LMs) pose critical safety risks, as harmful intent can be strategically spread across exchanges. Yet, the vast majority of prior work has focused on single-turn safety, while adaptability and diversity remain among the key challenges of multi-turn red-teaming. To address these challenges, we present X-Teaming, a scalable framework that systematically explores how seemingly harmless interactions escalate into harmful outcomes and generates corresponding attack scenarios. X-Teaming employs collaborative agents for planning, attack optimization, and verification, achieving state-of-the-art multi-turn jailbreak effectiveness and diversity with success rates up to 98.1% across representative leading open-weight and closed-source models. In particular, X-Teaming achieves a 96.2% attack success rate against the latest Claude 3.7 Sonnet model, which has been considered nearly immune to single-turn attacks. Building on X-Teaming, we introduce XGuard-Train, an open-source multi-turn safety training dataset that is 20x larger than the previous best resource, comprising 30K interactive jailbreaks, designed to enable robust multi-turn safety alignment for LMs. Our work offers essential tools and insights for mitigating sophisticated conversational attacks, advancing the multi-turn safety of LMs.