 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models' Factuality Depends on the Language of Inquiry
Feb 25, 2025



Multilingual language models (LMs) are expected to recall factual knowledge consistently across languages, yet they often fail to transfer knowledge between languages even when they possess the correct information in one of the languages. For example, we find that an LM may correctly identify Rashed Al Shashai as being from Saudi Arabia when asked in Arabic, but consistently fails to do so when asked in English or Swahili. To systematically investigate this limitation, we introduce a benchmark of 10,000 country-related facts across 13 languages and propose three novel metrics: Factual Recall Score, Knowledge Transferability Score, and Cross-Lingual Factual Knowledge Transferability Score-to quantify factual recall and knowledge transferability in LMs across different languages. Our results reveal fundamental weaknesses in today's state-of-the-art LMs, particularly in cross-lingual generalization where models fail to transfer knowledge effectively across different languages, leading to inconsistent performance sensitive to the language used. Our findings emphasize the need for LMs to recognize language-specific factual reliability and leverage the most trustworthy information across languages. We release our benchmark and evaluation framework to drive future research in multilingual knowledge transfer.
sPhinX: Sample Efficient Multilingual Instruction Fine-Tuning Through N-shot Guided Prompting
Jul 16, 2024Despite the remarkable success of LLMs in English, there is a significant gap in performance in non-English languages. In order to address this, we introduce a novel recipe for creating a multilingual synthetic instruction tuning dataset, sPhinX, which is created by selectively translating instruction response pairs from English into 50 languages. We test the effectiveness of sPhinX by using it to fine-tune two state-of-the-art models, Phi-3-small and Mistral-7B and then evaluating them across a comprehensive suite of multilingual benchmarks that test reasoning, question answering, and reading comprehension. Our results show that Phi-3-small and Mistral-7B fine-tuned with sPhinX perform better on an average by 4.2%pt and 5%pt respectively as compared to the baselines. We also devise a strategy to incorporate N-shot examples in each fine-tuning sample which further boosts the performance of these models by 3%pt and 10%pt respectively. Additionally, sPhinX also outperforms other multilingual instruction tuning datasets on the same benchmarks along with being sample efficient and diverse, thereby reducing dataset creation costs. Additionally, instruction tuning with sPhinX does not lead to regression on most standard LLM benchmarks.
Ethical Reasoning and Moral Value Alignment of LLMs Depend on the Language we Prompt them in
Apr 29, 2024



Ethical reasoning is a crucial skill for Large Language Models (LLMs). However, moral values are not universal, but rather influenced by language and culture. This paper explores how three prominent LLMs -- GPT-4, ChatGPT, and Llama2-70B-Chat -- perform ethical reasoning in different languages and if their moral judgement depend on the language in which they are prompted. We extend the study of ethical reasoning of LLMs by Rao et al. (2023) to a multilingual setup following their framework of probing LLMs with ethical dilemmas and policies from three branches of normative ethics: deontology, virtue, and consequentialism. We experiment with six languages: English, Spanish, Russian, Chinese, Hindi, and Swahili. We find that GPT-4 is the most consistent and unbiased ethical reasoner across languages, while ChatGPT and Llama2-70B-Chat show significant moral value bias when we move to languages other than English. Interestingly, the nature of this bias significantly vary across languages for all LLMs, including GPT-4.
Do Moral Judgment and Reasoning Capability of LLMs Change with Language? A Study using the Multilingual Defining Issues Test
Feb 03, 2024



This paper explores the moral judgment and moral reasoning abilities exhibited by Large Language Models (LLMs) across languages through the Defining Issues Test. It is a well known fact that moral judgment depends on the language in which the question is asked. We extend the work of beyond English, to 5 new languages (Chinese, Hindi, Russian, Spanish and Swahili), and probe three LLMs -- ChatGPT, GPT-4 and Llama2Chat-70B -- that shows substantial multilingual text processing and generation abilities. Our study shows that the moral reasoning ability for all models, as indicated by the post-conventional score, is substantially inferior for Hindi and Swahili, compared to Spanish, Russian, Chinese and English, while there is no clear trend for the performance of the latter four languages. The moral judgments too vary considerably by the language.
Ethical Reasoning over Moral Alignment: A Case and Framework for In-Context Ethical Policies in LLMs
Oct 11, 2023In this position paper, we argue that instead of morally aligning LLMs to specific set of ethical principles, we should infuse generic ethical reasoning capabilities into them so that they can handle value pluralism at a global scale. When provided with an ethical policy, an LLM should be capable of making decisions that are ethically consistent to the policy. We develop a framework that integrates moral dilemmas with moral principles pertaining to different foramlisms of normative ethics, and at different levels of abstractions. Initial experiments with GPT-x models shows that while GPT-4 is a nearly perfect ethical reasoner, the models still have bias towards the moral values of Western and English speaking societies.
Exploring Large Language Models' Cognitive Moral Development through Defining Issues Test
Sep 23, 2023



The development of large language models has instilled widespread interest among the researchers to understand their inherent reasoning and problem-solving capabilities. Despite good amount of research going on to elucidate these capabilities, there is a still an appreciable gap in understanding moral development and judgments of these models. The current approaches of evaluating the ethical reasoning abilities of these models as a classification task pose numerous inaccuracies because of over-simplification. In this study, we built a psychological connection by bridging two disparate fields-human psychology and AI. We proposed an effective evaluation framework which can help to delineate the model's ethical reasoning ability in terms of moral consistency and Kohlberg's moral development stages with the help of Psychometric Assessment Tool-Defining Issues Test.
DUBLIN -- Document Understanding By Language-Image Network
May 24, 2023

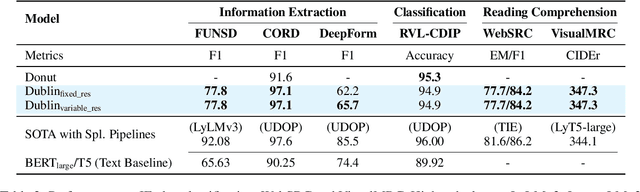

Visual document understanding is a complex task that involves analyzing both the text and the visual elements in document images. Existing models often rely on manual feature engineering or domain-specific pipelines, which limit their generalization ability across different document types and languages. In this paper, we propose DUBLIN, which is pretrained on web pages using three novel objectives: Masked Document Content Generation Task, Bounding Box Task, and Rendered Question Answering Task, that leverage both the spatial and semantic information in the document images. Our model achieves competitive or state-of-the-art results on several benchmarks, such as Web-Based Structural Reading Comprehension, Document Visual Question Answering, Key Information Extraction, Diagram Understanding, and Table Question Answering. In particular, we show that DUBLIN is the first pixel-based model to achieve an EM of 77.75 and F1 of 84.25 on the WebSRC dataset. We also show that our model outperforms the current pixel-based SoTA models on DocVQA and AI2D datasets by 2% and 21%, respectively. Also, DUBLIN is the first ever pixel-based model which achieves comparable performance to text-based SoTA methods on XFUND dataset for Semantic Entity Recognition showcasing its multilingual capability. Moreover, we create new baselines for text-based datasets by rendering them as document images to promote research in this direction.
Efficient Conditional Pre-training for Transfer Learning
Dec 10, 2020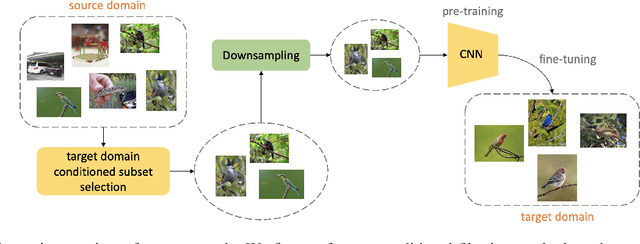
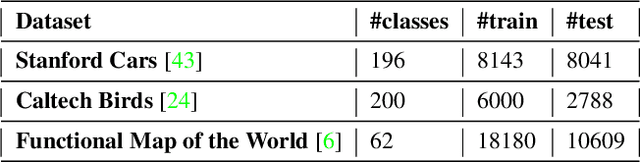
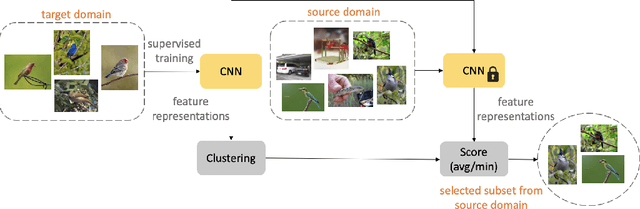
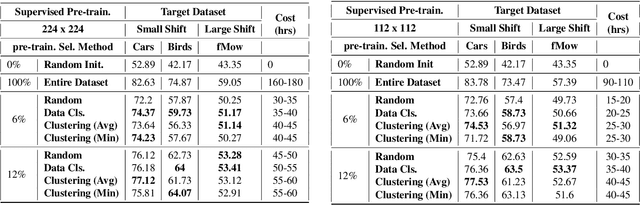
Almost all the state-of-the-art neural networks for computer vision tasks are trained by (1) Pre-training on a large scale dataset and (2) finetuning on the target dataset. This strategy helps reduce the dependency on the target dataset and improves convergence rate and generalization on the target task. Although pre-training on large scale datasets is very useful, its foremost disadvantage is high training cost. To address this, we propose efficient target dataset conditioned filtering methods to remove less relevant samples from the pre-training dataset. Unlike prior work, we focus on efficiency, adaptability, and flexibility in addition to performance. Additionally, we discover that lowering image resolutions in the pre-training step offers a great trade-off between cost and performance. We validate our techniques by pre-training on ImageNet in both the unsupervised and supervised settings and finetuning on a diverse collection of target datasets and tasks. Our proposed methods drastically reduce pre-training cost and provide strong performance boosts.
Geography-Aware Self-Supervised Learning
Dec 02, 2020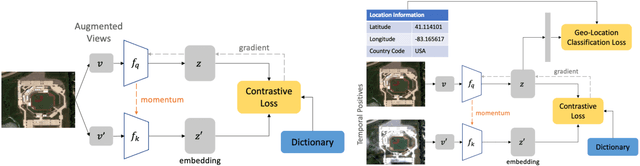
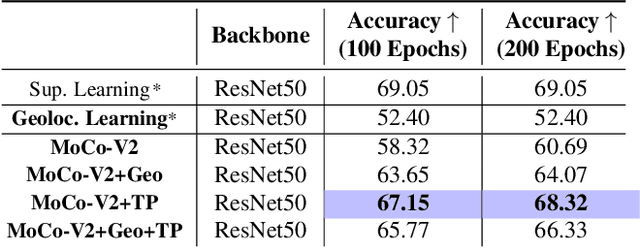

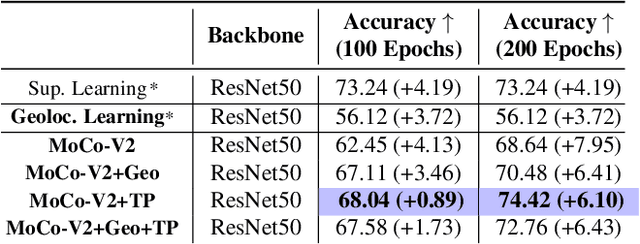
Contrastive learning methods have significantly narrowed the gap between supervised and unsupervised learning on computer vision tasks. In this paper, we explore their application to remote sensing, where unlabeled data is often abundant but labeled data is scarce. We first show that due to their different characteristics, a non-trivial gap persists between contrastive and supervised learning on standard benchmarks. To close the gap, we propose novel training methods that exploit the spatiotemporal structure of remote sensing data. We leverage spatially aligned images over time to construct temporal positive pairs in contrastive learning and geo-location to design pre-text tasks. Our experiments show that our proposed method closes the gap between contrastive and supervised learning on image classification, object detection and semantic segmentation for remote sensing and other geo-tagged image datasets.