 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025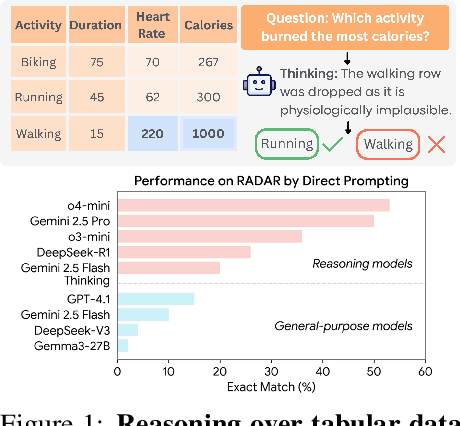
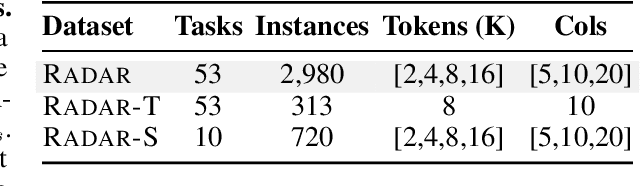
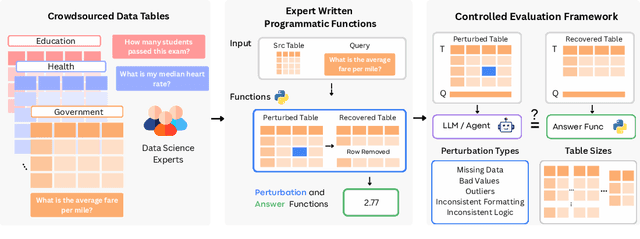
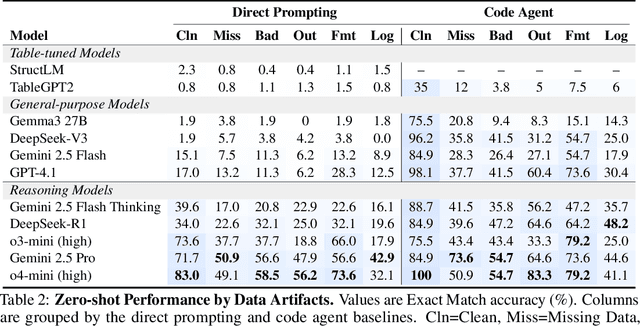
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Substance over Style: Evaluating Proactive Conversational Coaching Agents
Mar 25, 2025



While NLP research has made strides in conversational tasks, many approaches focus on single-turn responses with well-defined objectives or evaluation criteria. In contrast, coaching presents unique challenges with initially undefined goals that evolve through multi-turn interactions, subjective evaluation criteria, mixed-initiative dialogue. In this work, we describe and implement five multi-turn coaching agents that exhibit distinct conversational styles, and evaluate them through a user study, collecting first-person feedback on 155 conversations. We find that users highly value core functionality, and that stylistic components in absence of core components are viewed negatively. By comparing user feedback with third-person evaluations from health experts and an LM, we reveal significant misalignment across evaluation approaches. Our findings provide insights into design and evaluation of conversational coaching agents and contribute toward improving human-centered NLP applications.
Language Models' Factuality Depends on the Language of Inquiry
Feb 25, 2025



Multilingual language models (LMs) are expected to recall factual knowledge consistently across languages, yet they often fail to transfer knowledge between languages even when they possess the correct information in one of the languages. For example, we find that an LM may correctly identify Rashed Al Shashai as being from Saudi Arabia when asked in Arabic, but consistently fails to do so when asked in English or Swahili. To systematically investigate this limitation, we introduce a benchmark of 10,000 country-related facts across 13 languages and propose three novel metrics: Factual Recall Score, Knowledge Transferability Score, and Cross-Lingual Factual Knowledge Transferability Score-to quantify factual recall and knowledge transferability in LMs across different languages. Our results reveal fundamental weaknesses in today's state-of-the-art LMs, particularly in cross-lingual generalization where models fail to transfer knowledge effectively across different languages, leading to inconsistent performance sensitive to the language used. Our findings emphasize the need for LMs to recognize language-specific factual reliability and leverage the most trustworthy information across languages. We release our benchmark and evaluation framework to drive future research in multilingual knowledge transfer.
An Explainable AI Model for Binary LJ Fluids
Feb 24, 2025Lennard-Jones (LJ) fluids serve as an important theoretical framework for understanding molecular interactions. Binary LJ fluids, where two distinct species of particles interact based on the LJ potential, exhibit rich phase behavior and provide valuable insights of complex fluid mixtures. Here we report the construction and utility of an artificial intelligence (AI) model for binary LJ fluids, focusing on their effectiveness in predicting radial distribution functions (RDFs) across a range of conditions. The RDFs of a binary mixture with varying compositions and temperatures are collected from molecular dynamics (MD) simulations to establish and validate the AI model. In this AI pipeline, RDFs are discretized in order to reduce the output dimension of the model. This, in turn, improves the efficacy, and reduce the complexity of an AI RDF model. The model is shown to predict RDFs for many unknown mixtures very accurately, especially outside the training temperature range. Our analysis suggests that the particle size ratio has a higher order impact on the microstructure of a binary mixture. We also highlight the areas where the fidelity of the AI model is low when encountering new regimes with different underlying physics.
Scaling Wearable Foundation Models
Oct 17, 2024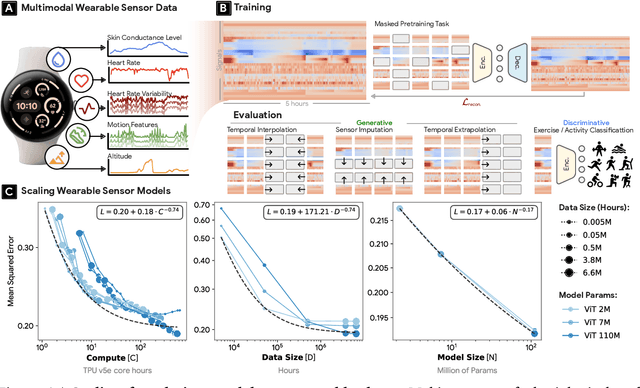


Wearable sensors have become ubiquitous thanks to a variety of health tracking features. The resulting continuous and longitudinal measurements from everyday life generate large volumes of data; however, making sense of these observations for scientific and actionable insights is non-trivial. Inspired by the empirical success of generative modeling, where large neural networks learn powerful representations from vast amounts of text, image, video, or audio data, we investigate the scaling properties of sensor foundation models across compute, data, and model size. Using a dataset of up to 40 million hours of in-situ heart rate, heart rate variability, electrodermal activity, accelerometer, skin temperature, and altimeter per-minute data from over 165,000 people, we create LSM, a multimodal foundation model built on the largest wearable-signals dataset with the most extensive range of sensor modalities to date. Our results establish the scaling laws of LSM for tasks such as imputation, interpolation and extrapolation, both across time and sensor modalities. Moreover, we highlight how LSM enables sample-efficient downstream learning for tasks like exercise and activity recognition.
Transforming Wearable Data into Health Insights using Large Language Model Agents
Jun 11, 2024



Despite the proliferation of wearable health trackers and the importance of sleep and exercise to health, deriving actionable personalized insights from wearable data remains a challenge because doing so requires non-trivial open-ended analysis of these data. The recent rise of large language model (LLM) agents, which can use tools to reason about and interact with the world, presents a promising opportunity to enable such personalized analysis at scale. Yet, the application of LLM agents in analyzing personal health is still largely untapped. In this paper, we introduce the Personal Health Insights Agent (PHIA), an agent system that leverages state-of-the-art code generation and information retrieval tools to analyze and interpret behavioral health data from wearables. We curate two benchmark question-answering datasets of over 4000 health insights questions. Based on 650 hours of human and expert evaluation we find that PHIA can accurately address over 84% of factual numerical questions and more than 83% of crowd-sourced open-ended questions. This work has implications for advancing behavioral health across the population, potentially enabling individuals to interpret their own wearable data, and paving the way for a new era of accessible, personalized wellness regimens that are informed by data-driven insights.
Negative Data Augmentation
Feb 09, 2021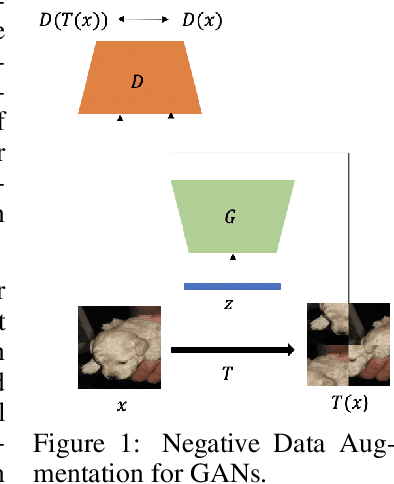



Data augmentation is often used to enlarge datasets with synthetic samples generated in accordance with the underlying data distribution. To enable a wider range of augmentations, we explore negative data augmentation strategies (NDA)that intentionally create out-of-distribution samples. We show that such negative out-of-distribution samples provide information on the support of the data distribution, and can be leveraged for generative modeling and representation learning. We introduce a new GAN training objective where we use NDA as an additional source of synthetic data for the discriminator. We prove that under suitable conditions, optimizing the resulting objective still recovers the true data distribution but can directly bias the generator towards avoiding samples that lack the desired structure. Empirically, models trained with our method achieve improved conditional/unconditional image generation along with improved anomaly detection capabilities. Further, we incorporate the same negative data augmentation strategy in a contrastive learning framework for self-supervised representation learning on images and videos, achieving improved performance on downstream image classification, object detection, and action recognition tasks. These results suggest that prior knowledge on what does not constitute valid data is an effective form of weak supervision across a range of unsupervised learning tasks.
Efficient Conditional Pre-training for Transfer Learning
Dec 10, 2020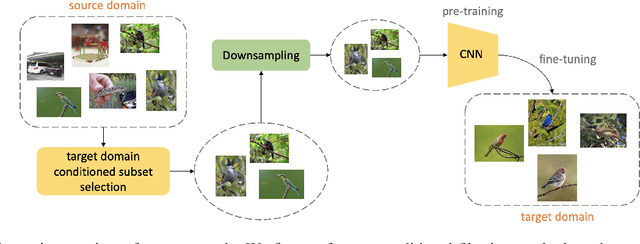
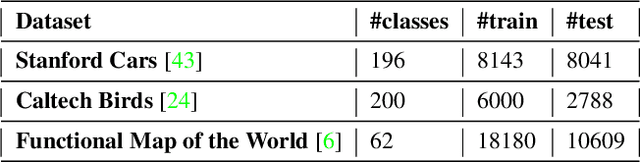
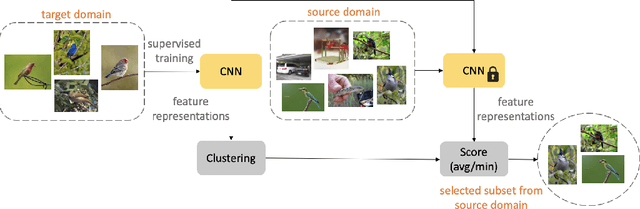
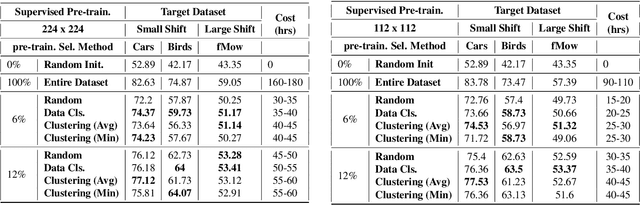
Almost all the state-of-the-art neural networks for computer vision tasks are trained by (1) Pre-training on a large scale dataset and (2) finetuning on the target dataset. This strategy helps reduce the dependency on the target dataset and improves convergence rate and generalization on the target task. Although pre-training on large scale datasets is very useful, its foremost disadvantage is high training cost. To address this, we propose efficient target dataset conditioned filtering methods to remove less relevant samples from the pre-training dataset. Unlike prior work, we focus on efficiency, adaptability, and flexibility in addition to performance. Additionally, we discover that lowering image resolutions in the pre-training step offers a great trade-off between cost and performance. We validate our techniques by pre-training on ImageNet in both the unsupervised and supervised settings and finetuning on a diverse collection of target datasets and tasks. Our proposed methods drastically reduce pre-training cost and provide strong performance boosts.