 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Pushing the Limit of PPG Sensing in Sedentary Conditions by Addressing Poor Skin-sensor Contact
Apr 03, 2025Photoplethysmography (PPG) is a widely used non-invasive technique for monitoring cardiovascular health and various physiological parameters on consumer and medical devices. While motion artifacts are well-known challenges in dynamic settings, suboptimal skin-sensor contact in sedentary conditions - a critical issue often overlooked in existing literature - can distort PPG signal morphology, leading to the loss or shift of essential waveform features and therefore degrading sensing performance. In this work, we propose CP-PPG, a novel approach that transforms Contact Pressure-distorted PPG signals into ones with the ideal morphology. CP-PPG incorporates a novel data collection approach, a well-crafted signal processing pipeline, and an advanced deep adversarial model trained with a custom PPG-aware loss function. We validated CP-PPG through comprehensive evaluations, including 1) morphology transformation performance on our self-collected dataset, 2) downstream physiological monitoring performance on public datasets, and 3) in-the-wild performance. Extensive experiments demonstrate substantial and consistent improvements in signal fidelity (Mean Absolute Error: 0.09, 40% improvement over the original signal) as well as downstream performance across all evaluations in Heart Rate (HR), Heart Rate Variability (HRV), Respiration Rate (RR), and Blood Pressure (BP) estimation (on average, 21% improvement in HR; 41-46% in HRV; 6% in RR; and 4-5% in BP). These findings highlight the critical importance of addressing skin-sensor contact issues for accurate and dependable PPG-based physiological monitoring. Furthermore, CP-PPG can serve as a generic, plug-in API to enhance PPG signal quality.
Beyond Prompting: Time2Lang -- Bridging Time-Series Foundation Models and Large Language Models for Health Sensing
Feb 12, 2025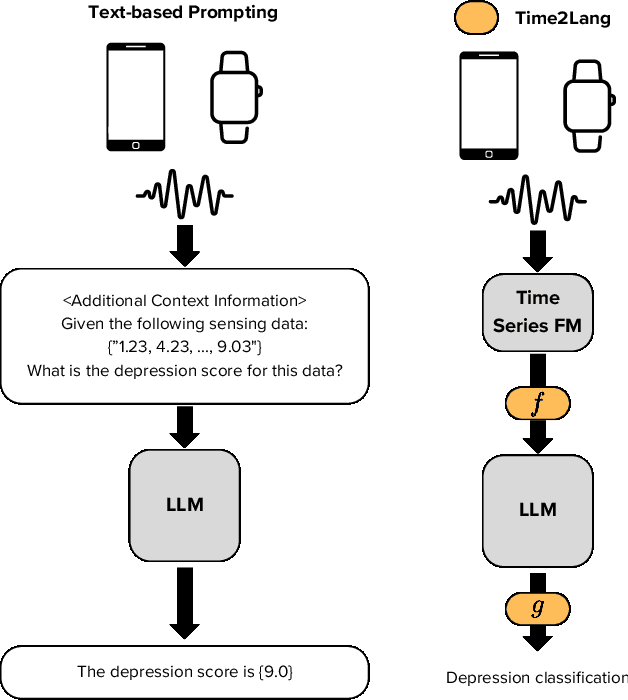
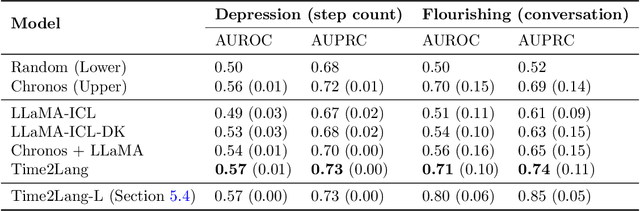
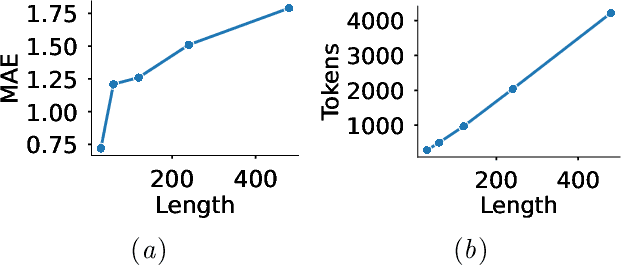

Large language models (LLMs) show promise for health applications when combined with behavioral sensing data. Traditional approaches convert sensor data into text prompts, but this process is prone to errors, computationally expensive, and requires domain expertise. These challenges are particularly acute when processing extended time series data. While time series foundation models (TFMs) have recently emerged as powerful tools for learning representations from temporal data, bridging TFMs and LLMs remains challenging. Here, we present Time2Lang, a framework that directly maps TFM outputs to LLM representations without intermediate text conversion. Our approach first trains on synthetic data using periodicity prediction as a pretext task, followed by evaluation on mental health classification tasks. We validate Time2Lang on two longitudinal wearable and mobile sensing datasets: daily depression prediction using step count data (17,251 days from 256 participants) and flourishing classification based on conversation duration (46 participants over 10 weeks). Time2Lang maintains near constant inference times regardless of input length, unlike traditional prompting methods. The generated embeddings preserve essential time-series characteristics such as auto-correlation. Our results demonstrate that TFMs and LLMs can be effectively integrated while minimizing information loss and enabling performance transfer across these distinct modeling paradigms. To our knowledge, we are the first to integrate a TFM and an LLM for health, thus establishing a foundation for future research combining general-purpose large models for complex healthcare tasks.
SoundCollage: Automated Discovery of New Classes in Audio Datasets
Oct 30, 2024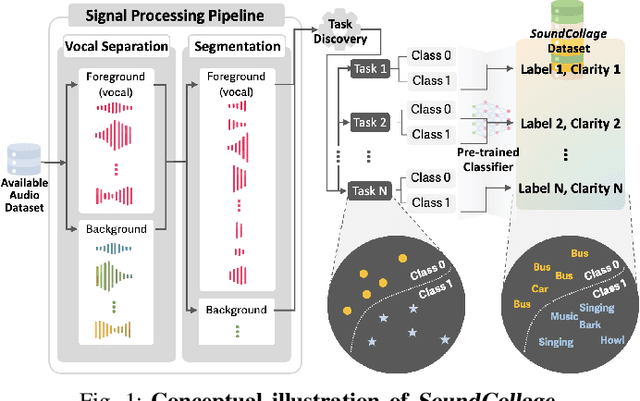



Developing new machine learning applications often requires the collection of new datasets. However, existing datasets may already contain relevant information to train models for new purposes. We propose SoundCollage: a framework to discover new classes within audio datasets by incorporating (1) an audio pre-processing pipeline to decompose different sounds in audio samples and (2) an automated model-based annotation mechanism to identify the discovered classes. Furthermore, we introduce clarity measure to assess the coherence of the discovered classes for better training new downstream applications. Our evaluations show that the accuracy of downstream audio classifiers within discovered class samples and held-out datasets improves over the baseline by up to 34.7% and 4.5%, respectively, highlighting the potential of SoundCollage in making datasets reusable by labeling with newly discovered classes. To encourage further research in this area, we open-source our code at https://github.com/nokia-bell-labs/audio-class-discovery.
PaPaGei: Open Foundation Models for Optical Physiological Signals
Oct 27, 2024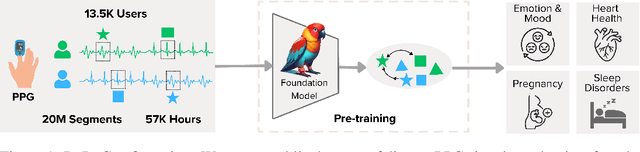
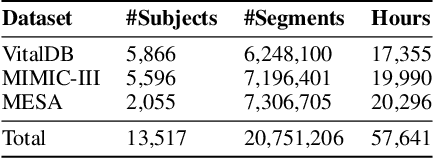
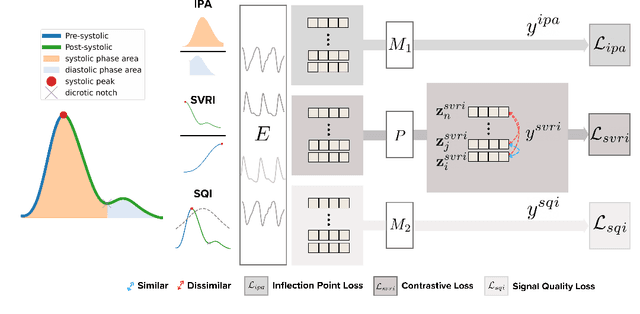
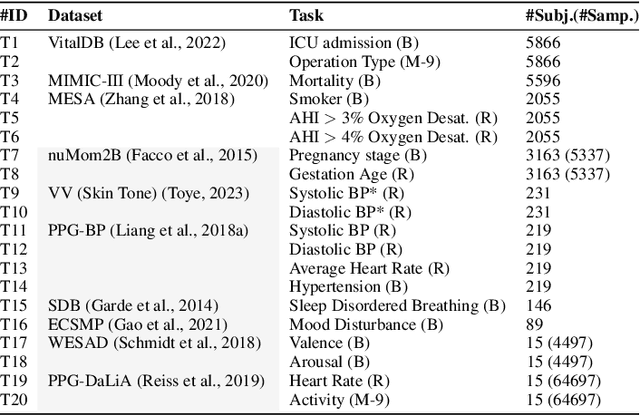
Photoplethysmography (PPG) is the most widely used non-invasive technique for monitoring biosignals and cardiovascular health, with applications in both clinical settings and consumer health through wearable devices. Current machine learning models trained on PPG signals are mostly task-specific and lack generalizability. Previous works often used single-device datasets, did not explore out-of-domain generalization, or did not release their models, hindering reproducibility and further research. We introduce PaPaGei, the first open foundation model for PPG signals. PaPaGei is pre-trained on more than 57,000 hours of 20 million unlabeled segments of PPG signals using publicly available datasets exclusively. We evaluate against popular time-series foundation models and other benchmarks on 20 tasks of 10 diverse datasets spanning cardiovascular health, sleep disorders, pregnancy monitoring, and wellbeing assessment. Our architecture incorporates novel representation learning approaches that leverage differences in PPG signal morphology across individuals, enabling it to capture richer representations than traditional contrastive learning methods. Across 20 tasks, PaPaGei improves classification and regression performance by an average of 6.3% and 2.9%, respectively, compared to other competitive time-series foundation models in at least 14 tasks. PaPaGei is more data- and parameter-efficient than other foundation models or methods, as it outperforms 70x larger models. Beyond accuracy, we also investigate robustness against different skin tones, establishing a benchmark for bias evaluations of future models. Notably, PaPaGei can be used out of the box as both a feature extractor and an encoder for other multimodal models, opening up new opportunities for multimodal health monitoring
StatioCL: Contrastive Learning for Time Series via Non-Stationary and Temporal Contrast
Oct 14, 2024Contrastive learning (CL) has emerged as a promising approach for representation learning in time series data by embedding similar pairs closely while distancing dissimilar ones. However, existing CL methods often introduce false negative pairs (FNPs) by neglecting inherent characteristics and then randomly selecting distinct segments as dissimilar pairs, leading to erroneous representation learning, reduced model performance, and overall inefficiency. To address these issues, we systematically define and categorize FNPs in time series into semantic false negative pairs and temporal false negative pairs for the first time: the former arising from overlooking similarities in label categories, which correlates with similarities in non-stationarity and the latter from neglecting temporal proximity. Moreover, we introduce StatioCL, a novel CL framework that captures non-stationarity and temporal dependency to mitigate both FNPs and rectify the inaccuracies in learned representations. By interpreting and differentiating non-stationary states, which reflect the correlation between trends or temporal dynamics with underlying data patterns, StatioCL effectively captures the semantic characteristics and eliminates semantic FNPs. Simultaneously, StatioCL establishes fine-grained similarity levels based on temporal dependencies to capture varying temporal proximity between segments and to mitigate temporal FNPs. Evaluated on real-world benchmark time series classification datasets, StatioCL demonstrates a substantial improvement over state-of-the-art CL methods, achieving a 2.9% increase in Recall and a 19.2% reduction in FNPs. Most importantly, StatioCL also shows enhanced data efficiency and robustness against label scarcity.
A collection of the accepted papers for the Human-Centric Representation Learning workshop at AAAI 2024
Mar 14, 2024This non-archival index is not complete, as some accepted papers chose to opt-out of inclusion. The list of all accepted papers is available on the workshop website.
Learning under Label Noise through Few-Shot Human-in-the-Loop Refinement
Jan 25, 2024



Wearable technologies enable continuous monitoring of various health metrics, such as physical activity, heart rate, sleep, and stress levels. A key challenge with wearable data is obtaining quality labels. Unlike modalities like video where the videos themselves can be effectively used to label objects or events, wearable data do not contain obvious cues about the physical manifestation of the users and usually require rich metadata. As a result, label noise can become an increasingly thorny issue when labeling such data. In this paper, we propose a novel solution to address noisy label learning, entitled Few-Shot Human-in-the-Loop Refinement (FHLR). Our method initially learns a seed model using weak labels. Next, it fine-tunes the seed model using a handful of expert corrections. Finally, it achieves better generalizability and robustness by merging the seed and fine-tuned models via weighted parameter averaging. We evaluate our approach on four challenging tasks and datasets, and compare it against eight competitive baselines designed to deal with noisy labels. We show that FHLR achieves significantly better performance when learning from noisy labels and achieves state-of-the-art by a large margin, with up to 19% accuracy improvement under symmetric and asymmetric noise. Notably, we find that FHLR is particularly robust to increased label noise, unlike prior works that suffer from severe performance degradation. Our work not only achieves better generalization in high-stakes health sensing benchmarks but also sheds light on how noise affects commonly-used models.
Balancing Continual Learning and Fine-tuning for Human Activity Recognition
Jan 04, 2024Wearable-based Human Activity Recognition (HAR) is a key task in human-centric machine learning due to its fundamental understanding of human behaviours. Due to the dynamic nature of human behaviours, continual learning promises HAR systems that are tailored to users' needs. However, because of the difficulty in collecting labelled data with wearable sensors, existing approaches that focus on supervised continual learning have limited applicability, while unsupervised continual learning methods only handle representation learning while delaying classifier training to a later stage. This work explores the adoption and adaptation of CaSSLe, a continual self-supervised learning model, and Kaizen, a semi-supervised continual learning model that balances representation learning and down-stream classification, for the task of wearable-based HAR. These schemes re-purpose contrastive learning for knowledge retention and, Kaizen combines that with self-training in a unified scheme that can leverage unlabelled and labelled data for continual learning. In addition to comparing state-of-the-art self-supervised continual learning schemes, we further investigated the importance of different loss terms and explored the trade-off between knowledge retention and learning from new tasks. In particular, our extensive evaluation demonstrated that the use of a weighting factor that reflects the ratio between learned and new classes achieves the best overall trade-off in continual learning.
Evaluating Fairness in Self-supervised and Supervised Models for Sequential Data
Jan 03, 2024Self-supervised learning (SSL) has become the de facto training paradigm of large models where pre-training is followed by supervised fine-tuning using domain-specific data and labels. Hypothesizing that SSL models would learn more generic, hence less biased, representations, this study explores the impact of pre-training and fine-tuning strategies on fairness (i.e., performing equally on different demographic breakdowns). Motivated by human-centric applications on real-world timeseries data, we interpret inductive biases on the model, layer, and metric levels by systematically comparing SSL models to their supervised counterparts. Our findings demonstrate that SSL has the capacity to achieve performance on par with supervised methods while significantly enhancing fairness--exhibiting up to a 27% increase in fairness with a mere 1% loss in performance through self-supervision. Ultimately, this work underscores SSL's potential in human-centric computing, particularly high-stakes, data-scarce application domains like healthcare.