 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECG-Reasoning-Benchmark: A Benchmark for Evaluating Clinical Reasoning Capabilities in ECG Interpretation
Mar 15, 2026While Multimodal Large Language Models (MLLMs) show promising performance in automated electrocardiogram interpretation, it remains unclear whether they genuinely perform actual step-by-step reasoning or just rely on superficial visual cues. To investigate this, we introduce \textbf{ECG-Reasoning-Benchmark}, a novel multi-turn evaluation framework comprising over 6,400 samples to systematically assess step-by-step reasoning across 17 core ECG diagnoses. Our comprehensive evaluation of state-of-the-art models reveals a critical failure in executing multi-step logical deduction. Although models possess the medical knowledge to retrieve clinical criteria for a diagnosis, they exhibit near-zero success rates (6% Completion) in maintaining a complete reasoning chain, primarily failing to ground the corresponding ECG findings to the actual visual evidence in the ECG signal. These results demonstrate that current MLLMs bypass actual visual interpretation, exposing a critical flaw in existing training paradigms and underscoring the necessity for robust, reasoning-centric medical AI. The code and data are available at https://github.com/Jwoo5/ecg-reasoning-benchmark.
ECG-Agent: On-Device Tool-Calling Agent for ECG Multi-Turn Dialogue
Jan 28, 2026Recent advances in Multimodal Large Language Models have rapidly expanded to electrocardiograms, focusing on classification, report generation, and single-turn QA tasks. However, these models fall short in real-world scenarios, lacking multi-turn conversational ability, on-device efficiency, and precise understanding of ECG measurements such as the PQRST intervals. To address these limitations, we introduce ECG-Agent, the first LLM-based tool-calling agent for multi-turn ECG dialogue. To facilitate its development and evaluation, we also present ECG-Multi-Turn-Dialogue (ECG-MTD) dataset, a collection of realistic user-assistant multi-turn dialogues for diverse ECG lead configurations. We develop ECG-Agents in various sizes, from on-device capable to larger agents. Experimental results show that ECG-Agents outperform baseline ECG-LLMs in response accuracy. Furthermore, on-device agents achieve comparable performance to larger agents in various evaluations that assess response accuracy, tool-calling ability, and hallucinations, demonstrating their viability for real-world applications.
LabTOP: A Unified Model for Lab Test Outcome Prediction on Electronic Health Records
Feb 20, 2025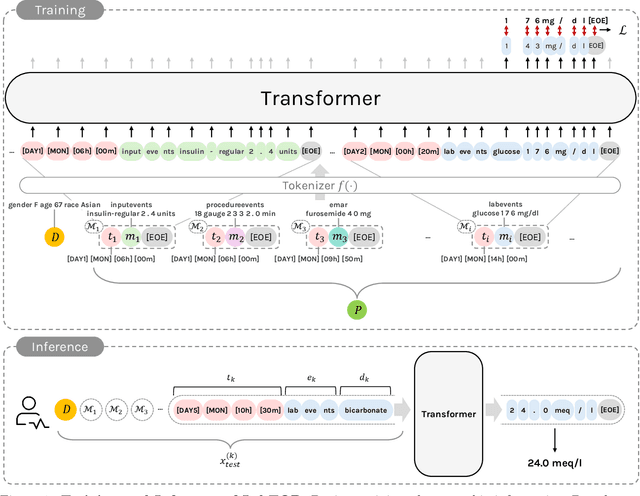
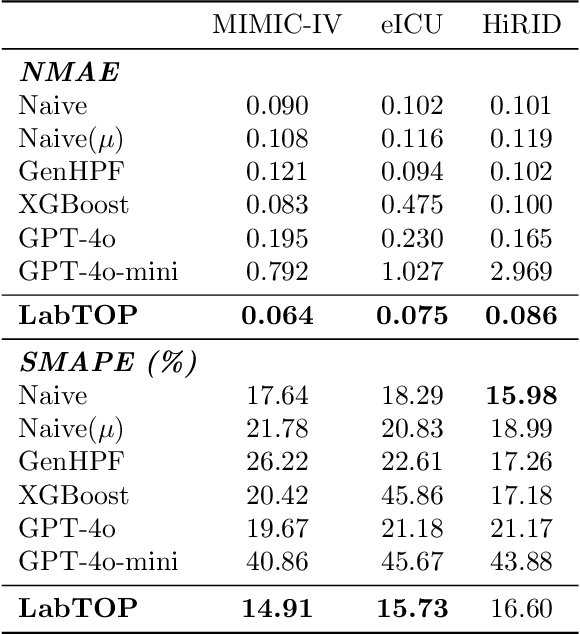
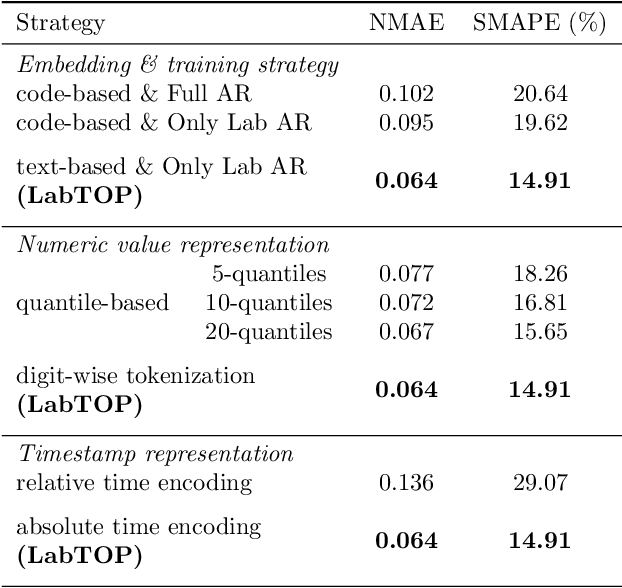
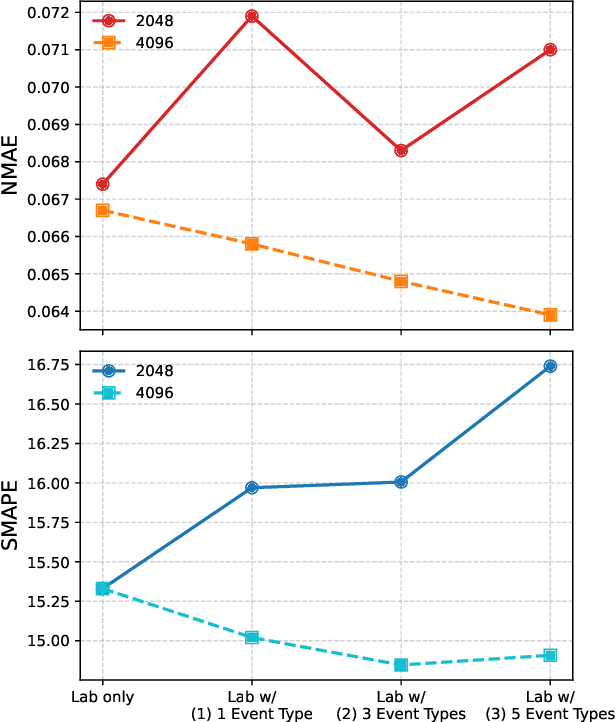
Lab tests are fundamental for diagnosing diseases and monitoring patient conditions. However, frequent testing can be burdensome for patients, and test results may not always be immediately available. To address these challenges, we propose LabTOP, a unified model that predicts lab test outcomes by leveraging a language modeling approach on EHR data. Unlike conventional methods that estimate only a subset of lab tests or classify discrete value ranges, LabTOP performs continuous numerical predictions for a diverse range of lab items. We evaluate LabTOP on three publicly available EHR datasets and demonstrate that it outperforms existing methods, including traditional machine learning models and state-of-the-art large language models. We also conduct extensive ablation studies to confirm the effectiveness of our design choices. We believe that LabTOP will serve as an accurate and generalizable framework for lab test outcome prediction, with potential applications in clinical decision support and early detection of critical conditions.
Learning under Label Noise through Few-Shot Human-in-the-Loop Refinement
Jan 25, 2024



Wearable technologies enable continuous monitoring of various health metrics, such as physical activity, heart rate, sleep, and stress levels. A key challenge with wearable data is obtaining quality labels. Unlike modalities like video where the videos themselves can be effectively used to label objects or events, wearable data do not contain obvious cues about the physical manifestation of the users and usually require rich metadata. As a result, label noise can become an increasingly thorny issue when labeling such data. In this paper, we propose a novel solution to address noisy label learning, entitled Few-Shot Human-in-the-Loop Refinement (FHLR). Our method initially learns a seed model using weak labels. Next, it fine-tunes the seed model using a handful of expert corrections. Finally, it achieves better generalizability and robustness by merging the seed and fine-tuned models via weighted parameter averaging. We evaluate our approach on four challenging tasks and datasets, and compare it against eight competitive baselines designed to deal with noisy labels. We show that FHLR achieves significantly better performance when learning from noisy labels and achieves state-of-the-art by a large margin, with up to 19% accuracy improvement under symmetric and asymmetric noise. Notably, we find that FHLR is particularly robust to increased label noise, unlike prior works that suffer from severe performance degradation. Our work not only achieves better generalization in high-stakes health sensing benchmarks but also sheds light on how noise affects commonly-used models.
EHRXQA: A Multi-Modal Question Answering Dataset for Electronic Health Records with Chest X-ray Images
Oct 28, 2023



Electronic Health Records (EHRs), which contain patients' medical histories in various multi-modal formats, often overlook the potential for joint reasoning across imaging and table modalities underexplored in current EHR Question Answering (QA) systems. In this paper, we introduce EHRXQA, a novel multi-modal question answering dataset combining structured EHRs and chest X-ray images. To develop our dataset, we first construct two uni-modal resources: 1) The MIMIC- CXR-VQA dataset, our newly created medical visual question answering (VQA) benchmark, specifically designed to augment the imaging modality in EHR QA, and 2) EHRSQL (MIMIC-IV), a refashioned version of a previously established table-based EHR QA dataset. By integrating these two uni-modal resources, we successfully construct a multi-modal EHR QA dataset that necessitates both uni-modal and cross-modal reasoning. To address the unique challenges of multi-modal questions within EHRs, we propose a NeuralSQL-based strategy equipped with an external VQA API. This pioneering endeavor enhances engagement with multi-modal EHR sources and we believe that our dataset can catalyze advances in real-world medical scenarios such as clinical decision-making and research. EHRXQA is available at https://github.com/baeseongsu/ehrxqa.
Publicly Shareable Clinical Large Language Model Built on Synthetic Clinical Notes
Sep 06, 2023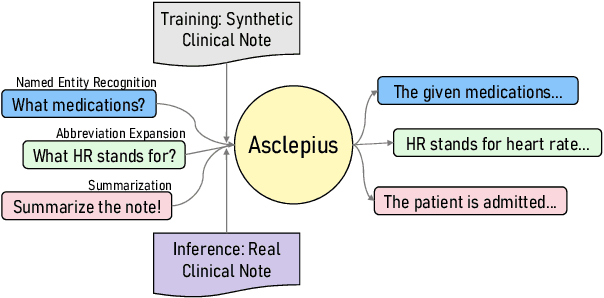
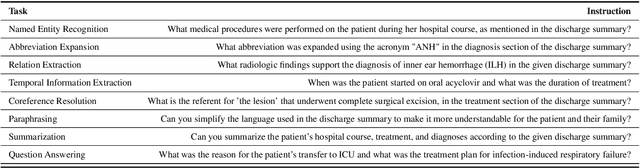
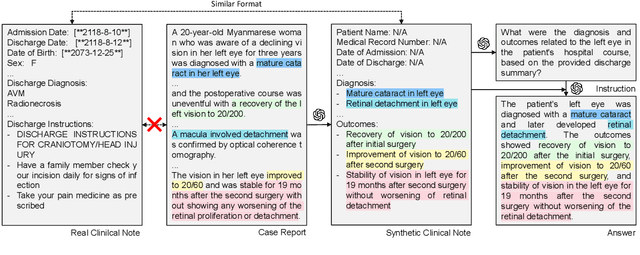
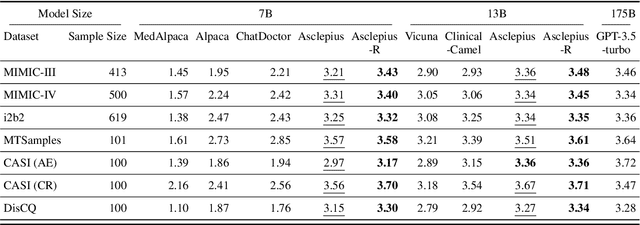
The development of large language models tailored for handling patients' clinical notes is often hindered by the limited accessibility and usability of these notes due to strict privacy regulations. To address these challenges, we first create synthetic large-scale clinical notes using publicly available case reports extracted from biomedical literature. We then use these synthetic notes to train our specialized clinical large language model, Asclepius. While Asclepius is trained on synthetic data, we assess its potential performance in real-world applications by evaluating it using real clinical notes. We benchmark Asclepius against several other large language models, including GPT-3.5-turbo and other open-source alternatives. To further validate our approach using synthetic notes, we also compare Asclepius with its variants trained on real clinical notes. Our findings convincingly demonstrate that synthetic clinical notes can serve as viable substitutes for real ones when constructing high-performing clinical language models. This conclusion is supported by detailed evaluations conducted by both GPT-4 and medical professionals. All resources including weights, codes, and data used in the development of Asclepius are made publicly accessible for future research.
ECG-QA: A Comprehensive Question Answering Dataset Combined With Electrocardiogram
Jun 21, 2023



Question answering (QA) in the field of healthcare has received much attention due to significant advancements in natural language processing. However, existing healthcare QA datasets primarily focus on medical images, clinical notes, or structured electronic health record tables. This leaves the vast potential of combining electrocardiogram (ECG) data with these systems largely untapped. To address this gap, we present ECG-QA, the first QA dataset specifically designed for ECG analysis. The dataset comprises a total of 70 question templates that cover a wide range of clinically relevant ECG topics, each validated by an ECG expert to ensure their clinical utility. As a result, our dataset includes diverse ECG interpretation questions, including those that require a comparative analysis of two different ECGs. In addition, we have conducted numerous experiments to provide valuable insights for future research directions. We believe that ECG-QA will serve as a valuable resource for the development of intelligent QA systems capable of assisting clinicians in ECG interpretations.
UniHPF : Universal Healthcare Predictive Framework with Zero Domain Knowledge
Nov 15, 2022


Despite the abundance of Electronic Healthcare Records (EHR), its heterogeneity restricts the utilization of medical data in building predictive models. To address this challenge, we propose Universal Healthcare Predictive Framework (UniHPF), which requires no medical domain knowledge and minimal pre-processing for multiple prediction tasks. Experimental results demonstrate that UniHPF is capable of building large-scale EHR models that can process any form of medical data from distinct EHR systems. We believe that our findings can provide helpful insights for further research on the multi-source learning of EHRs.
Lead-agnostic Self-supervised Learning for Local and Global Representations of Electrocardiogram
Mar 18, 2022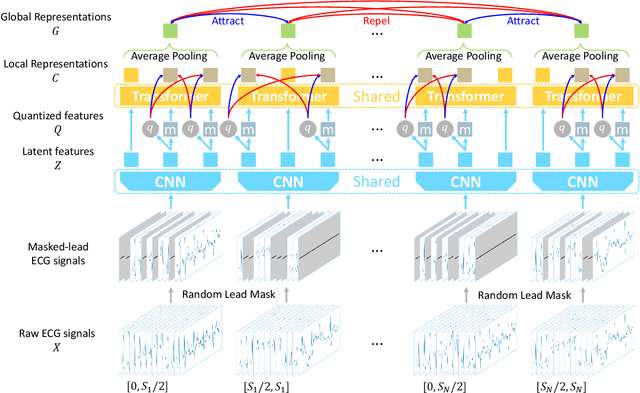
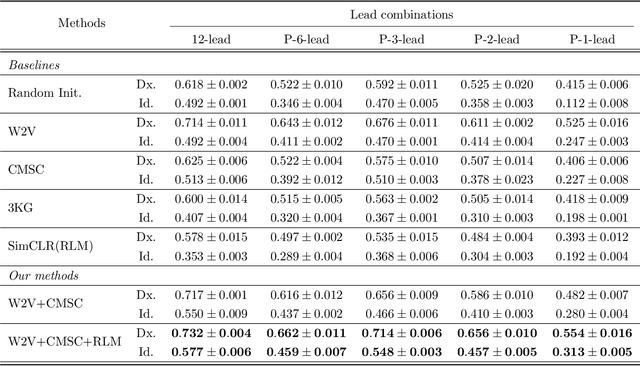
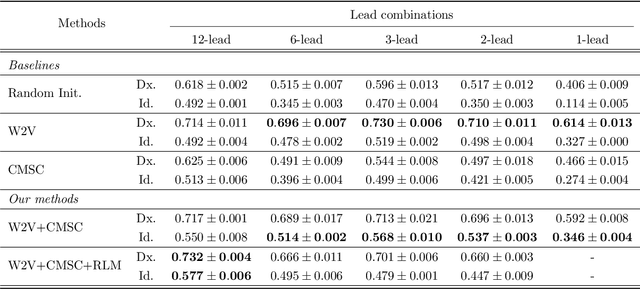
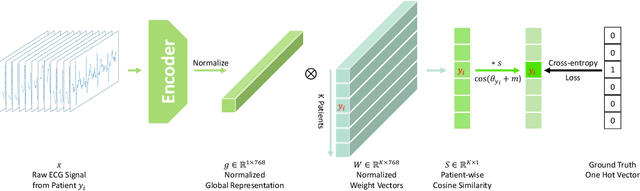
In recent years, self-supervised learning methods have shown significant improvement for pre-training with unlabeled data and have proven helpful for electrocardiogram signals. However, most previous pre-training methods for electrocardiogram focused on capturing only global contextual representations. This inhibits the models from learning fruitful representation of electrocardiogram, which results in poor performance on downstream tasks. Additionally, they cannot fine-tune the model with an arbitrary set of electrocardiogram leads unless the models were pre-trained on the same set of leads. In this work, we propose an ECG pre-training method that learns both local and global contextual representations for better generalizability and performance on downstream tasks. In addition, we propose random lead masking as an ECG-specific augmentation method to make our proposed model robust to an arbitrary set of leads. Experimental results on two downstream tasks, cardiac arrhythmia classification and patient identification, show that our proposed approach outperforms other state-of-the-art methods.
Unifying Heterogenous Electronic Health Records Systems via Text-Based Code Embedding
Nov 19, 2021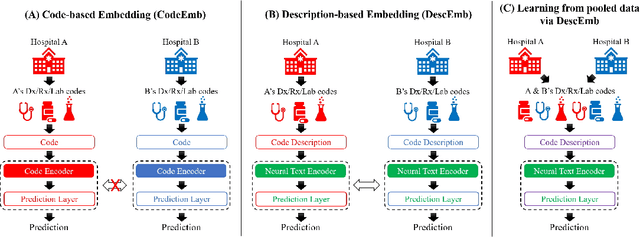
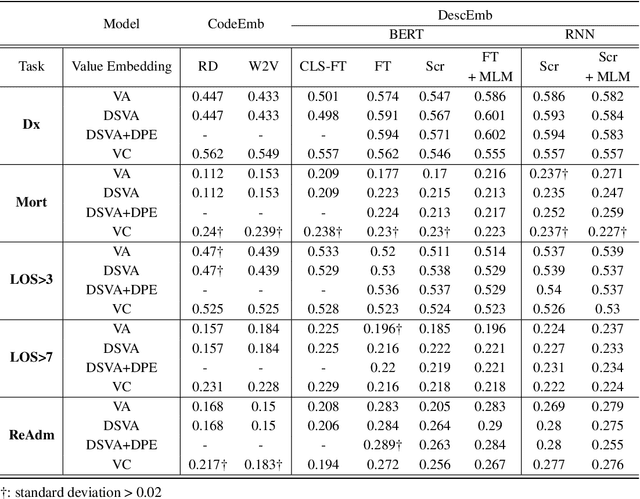
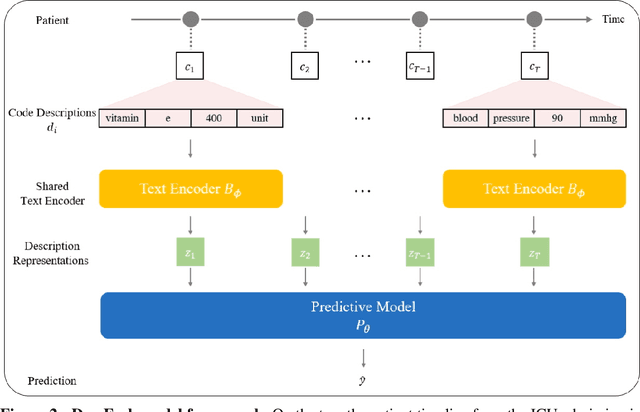
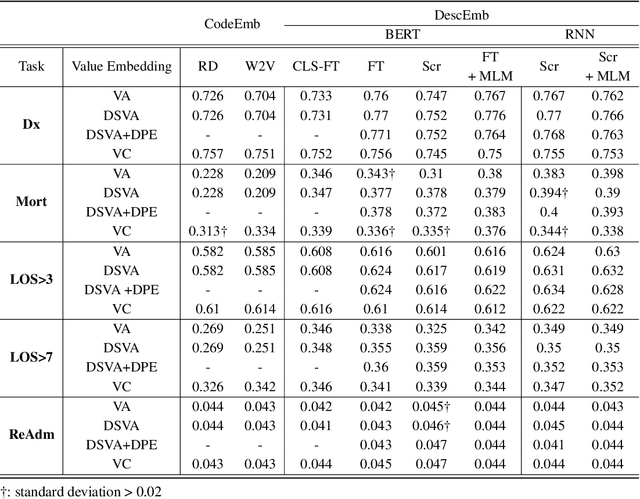
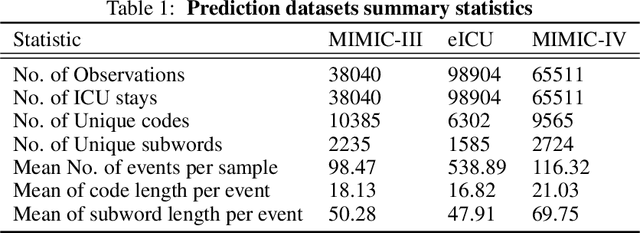
EHR systems lack a unified code system forrepresenting medical concepts, which acts asa barrier for the deployment of deep learningmodels in large scale to multiple clinics and hos-pitals. To overcome this problem, we introduceDescription-based Embedding,DescEmb, a code-agnostic representation learning framework forEHR. DescEmb takes advantage of the flexibil-ity of neural language understanding models toembed clinical events using their textual descrip-tions rather than directly mapping each event toa dedicated embedding. DescEmb outperformedtraditional code-based embedding in extensiveexperiments, especially in a zero-shot transfertask (one hospital to another), and was able totrain a single unified model for heterogeneousEHR datasets.