 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenMedReason: Scientific Reasoning Supervision for Medical Vision-Language Models
Jun 10, 2026High-stakes clinical use of large vision-language models (LVLMs) requires reasoning that is grounded in visual evidence and clinical knowledge, not just correct final answers. We introduce OpenMedReason, a large-scale, open multimodal medical reasoning corpus comprising approximately 450K image-question-answer instances whose reasoning traces are primarily derived from curated biomedical, human-authored scientific articles. OpenMedReason provides high-fidelity supervision beyond synthetic chains of thought, covering diverse medical domain vision modalities such as radiological scans, microscopic images, visible light photographs, charts, and others. We complement it with OpenMedReason-Bench, a held-out benchmark that allows fine-grained evaluation of LVLMs along three complementary axes of capability, including perception, medical knowledge, and rationale, enabling diagnostic evaluation beyond final-answer accuracy. OpenMedReason is a rich training resource that exhibits its effectiveness in both supervised fine-tuning (SFT) and reinforcement-based alignment. Training with OpenMedReason yields a 20% average improvement in VQA accuracy over the base model and achieves performance within 4.2% of the strongest comparable-scale medical LVLMs. Fine-grained performance analysis confirms that the gains are not concentrated in any single axis: OpenMedReason improves perception, medical knowledge, and rationale jointly, and its reasoning traces are preferred over those of the base model in 86.1% of pairwise comparisons. We release the code and dataset at huggingface.co/datasets/neginb/OpenMedReason.
Analyzing and Improving Fine-grained Preference Optimization in Medical LVLMs
Jun 10, 2026Large Vision-Language Models (LVLMs) have achieved strong performance across medical imaging tasks, yet they remain prone to factual inconsistencies, poor visual grounding, and misalignment with clinically meaningful feedback. Existing post-training alignment approaches, including Direct Preference Optimization (DPO) and its variants, face three critical limitations in the medical domain: (1) sequence-level reward signals treat clinically critical tokens identically to generic filler text; (2) reliance on static supervised fine-tuning references as preferred responses introduces an off-policy distribution shift, steering optimization toward stylistic artifacts over clinical correctness; and (3) alignment objectives lack explicit visual grounding constraints, leaving models insensitive to subtle yet diagnostically decisive pathological features. Our method leverages a bidirectional token-wise KL regularizer alongside a visual-contrastive grounding objective that pairs clean and lesion-corrupted images to penalize responses generated without adequate visual evidence. Together, these components form a fine-grained, on-policy alignment framework that constructs preference pairs by minimally editing model-generated outputs, correcting only clinically erroneous spans while preserving the original linguistic style. Extensive experiments across medical imaging tasks and clinical text generation benchmarks validate the effectiveness of our approach.
ADAPTOOD: Uncertainty-Aware Fine-Tuning for Out-of-Distribution ECG Time Series Models
Jun 02, 2026Data samples used for training often differ from those encountered during fine-tuning and deployment, and while ML models show promise, their performance remains limited when only small annotated datasets are available. Performance often degrades under distribution shifts caused by diverse sensors, populations, and application settings. Although pre-training helps, models frequently encounter out-of-distribution (OOD) data in real-world settings, leading to reduced robustness. Existing adaptation methods usually assume fixed distribution shifts and struggle when multiple types or severities occur. In particular, they overlook shift severity, for example treating adaptation to a large familiar dataset the same as adaptation to a small dataset with a new task, which limits generalisation. To address this, we propose ADAPTOOD, a novel framework that leverages data uncertainty to quantify distribution shift severity and guide fine-tuning for time series. This uncertainty measures how strongly samples from the target deployment distribution deviate from the pre-training distribution, providing a direct signal of OOD severity. Our framework combines this uncertainty with low-rank model updates and adaptive hyperparameter optimisation to improve adaptation. We show that ADAPTOOD achieves up to 7% higher accuracy and 12.9% higher precision than existing methods in OOD tasks, maintaining strong performance as distribution shift severity increases.
Evaluating Test-Time Adaptation For Facial Expression Recognition Under Natural Cross-Dataset Distribution Shifts
Mar 20, 2026Deep learning models often struggle under natural distribution shifts, a common challenge in real-world deployments. Test-Time Adaptation (TTA) addresses this by adapting models during inference without labeled source data. We present the first evaluation of TTA methods for FER under natural domain shifts, performing cross-dataset experiments with widely used FER datasets. This moves beyond synthetic corruptions to examine real-world shifts caused by differing collection protocols, annotation standards, and demographics. Results show TTA can boost FER performance under natural shifts by up to 11.34\%. Entropy minimization methods such as TENT and SAR perform best when the target distribution is clean. In contrast, prototype adjustment methods like T3A excel under larger distributional distance scenarios. Finally, feature alignment methods such as SHOT deliver the largest gains when the target distribution is noisier than our source. Our cross-dataset analysis shows that TTA effectiveness is governed by the distributional distance and the severity of the natural shift across domains.
Investigating ECG Diagnosis with Ambiguous Labels using Partial Label Learning
Dec 11, 2025Label ambiguity is an inherent problem in real-world electrocardiogram (ECG) diagnosis, arising from overlapping conditions and diagnostic disagreement. However, current ECG models are trained under the assumption of clean and non-ambiguous annotations, which limits both the development and the meaningful evaluation of models under real-world conditions. Although Partial Label Learning (PLL) frameworks are designed to learn from ambiguous labels, their effectiveness in medical time-series domains, ECG in particular, remains largely unexplored. In this work, we present the first systematic study of PLL methods for ECG diagnosis. We adapt nine PLL algorithms to multi-label ECG diagnosis and evaluate them using a diverse set of clinically motivated ambiguity generation strategies, capturing both unstructured (e.g., random) and structured ambiguities (e.g., cardiologist-derived similarities, treatment relationships, and diagnostic taxonomies). Our experiments on the PTB-XL and Chapman datasets demonstrate that PLL methods vary substantially in their robustness to different types and degrees of ambiguity. Through extensive analysis, we identify key limitations of current PLL approaches in clinical settings and outline future directions for developing robust and clinically aligned ambiguity-aware learning frameworks for ECG diagnosis.
Understanding Mental States in Active and Autonomous Driving with EEG
Dec 09, 2025Understanding how driver mental states differ between active and autonomous driving is critical for designing safe human-vehicle interfaces. This paper presents the first EEG-based comparison of cognitive load, fatigue, valence, and arousal across the two driving modes. Using data from 31 participants performing identical tasks in both scenarios of three different complexity levels, we analyze temporal patterns, task-complexity effects, and channel-wise activation differences. Our findings show that although both modes evoke similar trends across complexity levels, the intensity of mental states and the underlying neural activation differ substantially, indicating a clear distribution shift between active and autonomous driving. Transfer-learning experiments confirm that models trained on active driving data generalize poorly to autonomous driving and vice versa. We attribute this distribution shift primarily to differences in motor engagement and attentional demands between the two driving modes, which lead to distinct spatial and temporal EEG activation patterns. Although autonomous driving results in lower overall cortical activation, participants continue to exhibit measurable fluctuations in cognitive load, fatigue, valence, and arousal associated with readiness to intervene, task-evoked emotional responses, and monotony-related passive fatigue. These results emphasize the need for scenario-specific data and models when developing next-generation driver monitoring systems for autonomous vehicles.
Graph-Based Learning of Spectro-Topographical EEG Representations with Gradient Alignment for Brain-Computer Interfaces
Dec 08, 2025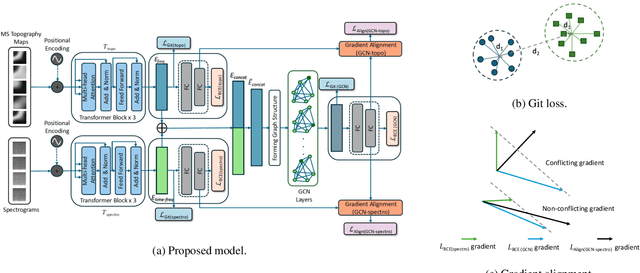
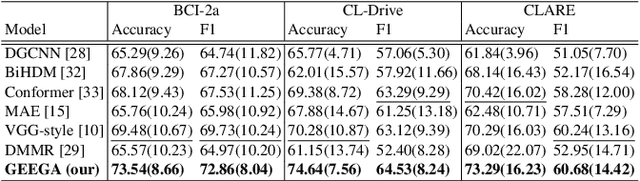
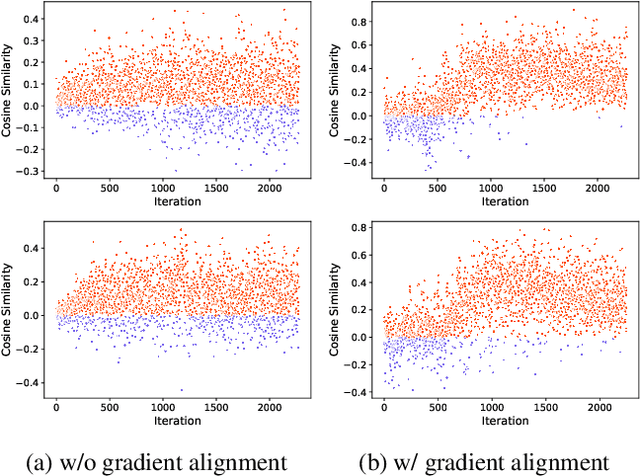
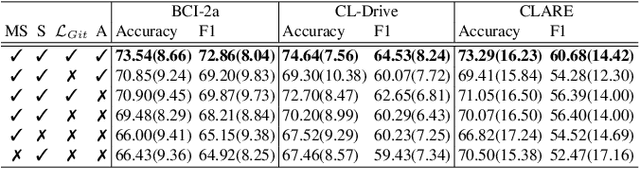
We present a novel graph-based learning of EEG representations with gradient alignment (GEEGA) that leverages multi-domain information to learn EEG representations for brain-computer interfaces. Our model leverages graph convolutional networks to fuse embeddings from frequency-based topographical maps and time-frequency spectrograms, capturing inter-domain relationships. GEEGA addresses the challenge of achieving high inter-class separability, which arises from the temporally dynamic and subject-sensitive nature of EEG signals by incorporating the center loss and pairwise difference loss. Additionally, GEEGA incorporates a gradient alignment strategy to resolve conflicts between gradients from different domains and the fused embeddings, ensuring that discrepancies, where gradients point in conflicting directions, are aligned toward a unified optimization direction. We validate the efficacy of our method through extensive experiments on three publicly available EEG datasets: BCI-2a, CL-Drive and CLARE. Comprehensive ablation studies further highlight the impact of various components of our model.
Multi-Domain EEG Representation Learning with Orthogonal Mapping and Attention-based Fusion for Cognitive Load Classification
Nov 16, 2025We propose a new representation learning solution for the classification of cognitive load based on Electroencephalogram (EEG). Our method integrates both time and frequency domains by first passing the raw EEG signals through the convolutional encoder to obtain the time domain representations. Next, we measure the Power Spectral Density (PSD) for all five EEG frequency bands and generate the channel power values as 2D images referred to as multi-spectral topography maps. These multi-spectral topography maps are then fed to a separate encoder to obtain the representations in frequency domain. Our solution employs a multi-domain attention module that maps these domain-specific embeddings onto a shared embedding space to emphasize more on important inter-domain relationships to enhance the representations for cognitive load classification. Additionally, we incorporate an orthogonal projection constraint during the training of our method to effectively increase the inter-class distances while improving intra-class clustering. This enhancement allows efficient discrimination between different cognitive states and aids in better grouping of similar states within the feature space. We validate the effectiveness of our model through extensive experiments on two public EEG datasets, CL-Drive and CLARE for cognitive load classification. Our results demonstrate the superiority of our multi-domain approach over the traditional single-domain techniques. Moreover, we conduct ablation and sensitivity analyses to assess the impact of various components of our method. Finally, robustness experiments on different amounts of added noise demonstrate the stability of our method compared to other state-of-the-art solutions.
Learning Time-Series Representations by Hierarchical Uniformity-Tolerance Latent Balancing
Oct 02, 2025We propose TimeHUT, a novel method for learning time-series representations by hierarchical uniformity-tolerance balancing of contrastive representations. Our method uses two distinct losses to learn strong representations with the aim of striking an effective balance between uniformity and tolerance in the embedding space. First, TimeHUT uses a hierarchical setup to learn both instance-wise and temporal information from input time-series. Next, we integrate a temperature scheduler within the vanilla contrastive loss to balance the uniformity and tolerance characteristics of the embeddings. Additionally, a hierarchical angular margin loss enforces instance-wise and temporal contrast losses, creating geometric margins between positive and negative pairs of temporal sequences. This approach improves the coherence of positive pairs and their separation from the negatives, enhancing the capture of temporal dependencies within a time-series sample. We evaluate our approach on a wide range of tasks, namely 128 UCR and 30 UAE datasets for univariate and multivariate classification, as well as Yahoo and KPI datasets for anomaly detection. The results demonstrate that TimeHUT outperforms prior methods by considerable margins on classification, while obtaining competitive results for anomaly detection. Finally, detailed sensitivity and ablation studies are performed to evaluate different components and hyperparameters of our method.
VCRBench: Exploring Long-form Causal Reasoning Capabilities of Large Video Language Models
May 13, 2025
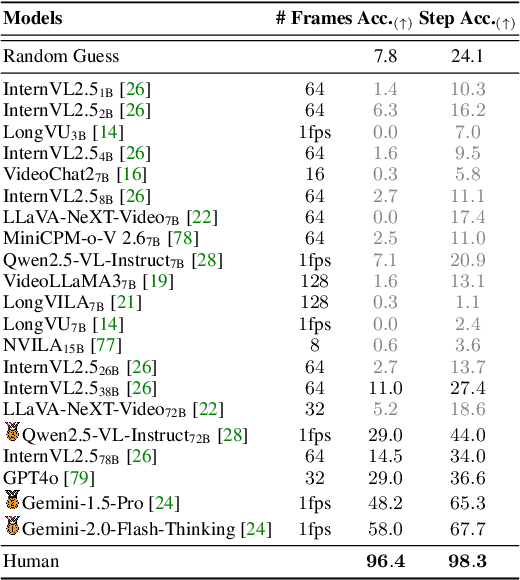
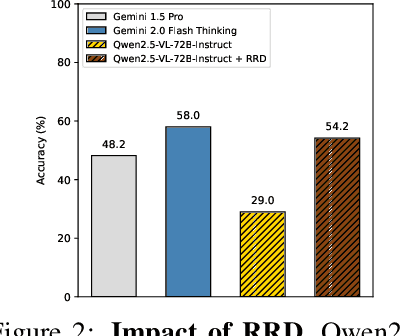
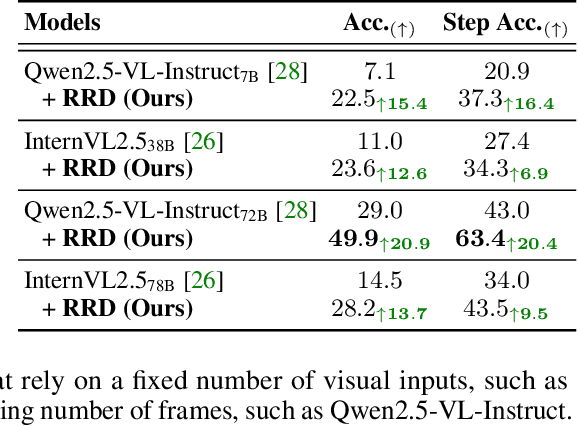
Despite recent advances in video understanding, the capabilities of Large Video Language Models (LVLMs) to perform video-based causal reasoning remains underexplored, largely due to the absence of relevant and dedicated benchmarks for evaluating causal reasoning in visually grounded and goal-driven settings. To fill this gap, we introduce a novel benchmark named Video-based long-form Causal Reasoning (VCRBench). We create VCRBench using procedural videos of simple everyday activities, where the steps are deliberately shuffled with each clip capturing a key causal event, to test whether LVLMs can identify, reason about, and correctly sequence the events needed to accomplish a specific goal. Moreover, the benchmark is carefully designed to prevent LVLMs from exploiting linguistic shortcuts, as seen in multiple-choice or binary QA formats, while also avoiding the challenges associated with evaluating open-ended QA. Our evaluation of state-of-the-art LVLMs on VCRBench suggests that these models struggle with video-based long-form causal reasoning, primarily due to their difficulty in modeling long-range causal dependencies directly from visual observations. As a simple step toward enabling such capabilities, we propose Recognition-Reasoning Decomposition (RRD), a modular approach that breaks video-based causal reasoning into two sub-tasks of video recognition and causal reasoning. Our experiments on VCRBench show that RRD significantly boosts accuracy on VCRBench, with gains of up to 25.2%. Finally, our thorough analysis reveals interesting insights, for instance, that LVLMs primarily rely on language knowledge for complex video-based long-form causal reasoning tasks.