 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAH Dataset for Ambivalence/Hesitancy Recognition in Videos for Behavioural Change
May 25, 2025



Recognizing complex emotions linked to ambivalence and hesitancy (A/H) can play a critical role in the personalization and effectiveness of digital behaviour change interventions. These subtle and conflicting emotions are manifested by a discord between multiple modalities, such as facial and vocal expressions, and body language. Although experts can be trained to identify A/H, integrating them into digital interventions is costly and less effective. Automatic learning systems provide a cost-effective alternative that can adapt to individual users, and operate seamlessly within real-time, and resource-limited environments. However, there are currently no datasets available for the design of ML models to recognize A/H. This paper introduces a first Behavioural Ambivalence/Hesitancy (BAH) dataset collected for subject-based multimodal recognition of A/H in videos. It contains videos from 224 participants captured across 9 provinces in Canada, with different age, and ethnicity. Through our web platform, we recruited participants to answer 7 questions, some of which were designed to elicit A/H while recording themselves via webcam with microphone. BAH amounts to 1,118 videos for a total duration of 8.26 hours with 1.5 hours of A/H. Our behavioural team annotated timestamp segments to indicate where A/H occurs, and provide frame- and video-level annotations with the A/H cues. Video transcripts and their timestamps are also included, along with cropped and aligned faces in each frame, and a variety of participants meta-data. We include results baselines for BAH at frame- and video-level recognition in multi-modal setups, in addition to zero-shot prediction, and for personalization using unsupervised domain adaptation. The limited performance of baseline models highlights the challenges of recognizing A/H in real-world videos. The data, code, and pretrained weights are available.
Learning from Stochastic Teacher Representations Using Student-Guided Knowledge Distillation
Apr 19, 2025Advances in self-distillation have shown that when knowledge is distilled from a teacher to a student using the same deep learning (DL) architecture, the student performance can surpass the teacher particularly when the network is overparameterized and the teacher is trained with early stopping. Alternatively, ensemble learning also improves performance, although training, storing, and deploying multiple models becomes impractical as the number of models grows. Even distilling an ensemble to a single student model or weight averaging methods first requires training of multiple teacher models and does not fully leverage the inherent stochasticity for generating and distilling diversity in DL models. These constraints are particularly prohibitive in resource-constrained or latency-sensitive applications such as wearable devices. This paper proposes to train only one model and generate multiple diverse teacher representations using distillation-time dropout. However, generating these representations stochastically leads to noisy representations that are misaligned with the learned task. To overcome this problem, a novel stochastic self-distillation (SSD) training strategy is introduced for filtering and weighting teacher representation to distill from task-relevant representations only, using student-guided knowledge distillation (SGKD). The student representation at each distillation step is used as authority to guide the distillation process. Experimental results on real-world affective computing, wearable/biosignal datasets from the UCR Archive, the HAR dataset, and image classification datasets show that the proposed SSD method can outperform state-of-the-art methods without increasing the model size at both training and testing time, and incurs negligible computational complexity compared to state-of-the-art ensemble learning and weight averaging methods.
Multi Teacher Privileged Knowledge Distillation for Multimodal Expression Recognition
Aug 16, 2024



Human emotion is a complex phenomenon conveyed and perceived through facial expressions, vocal tones, body language, and physiological signals. Multimodal emotion recognition systems can perform well because they can learn complementary and redundant semantic information from diverse sensors. In real-world scenarios, only a subset of the modalities employed for training may be available at test time. Learning privileged information allows a model to exploit data from additional modalities that are only available during training. SOTA methods for PKD have been proposed to distill information from a teacher model (with privileged modalities) to a student model (without privileged modalities). However, such PKD methods utilize point-to-point matching and do not explicitly capture the relational information. Recently, methods have been proposed to distill the structural information. However, PKD methods based on structural similarity are primarily confined to learning from a single joint teacher representation, which limits their robustness, accuracy, and ability to learn from diverse multimodal sources. In this paper, a multi-teacher PKD (MT-PKDOT) method with self-distillation is introduced to align diverse teacher representations before distilling them to the student. MT-PKDOT employs a structural similarity KD mechanism based on a regularized optimal transport (OT) for distillation. The proposed MT-PKDOT method was validated on the Affwild2 and Biovid datasets. Results indicate that our proposed method can outperform SOTA PKD methods. It improves the visual-only baseline on Biovid data by 5.5%. On the Affwild2 dataset, the proposed method improves 3% and 5% over the visual-only baseline for valence and arousal respectively. Allowing the student to learn from multiple diverse sources is shown to increase the accuracy and implicitly avoids negative transfer to the student model.
Distilling Privileged Multimodal Information for Expression Recognition using Optimal Transport
Jan 27, 2024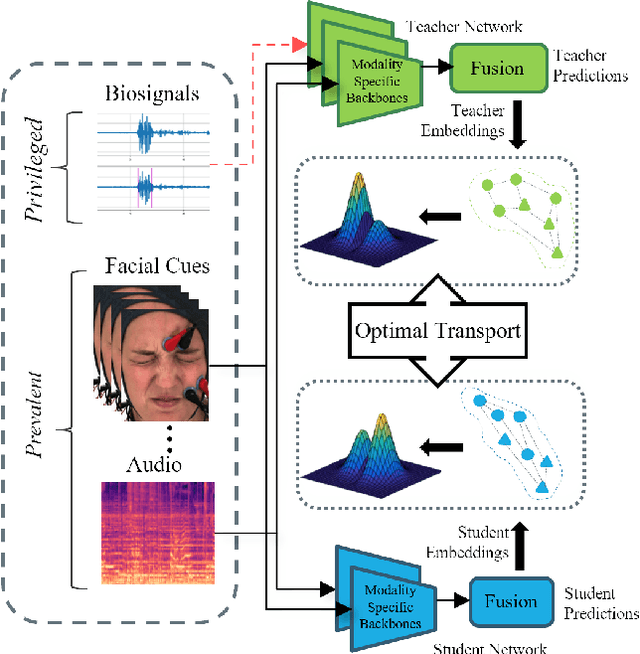
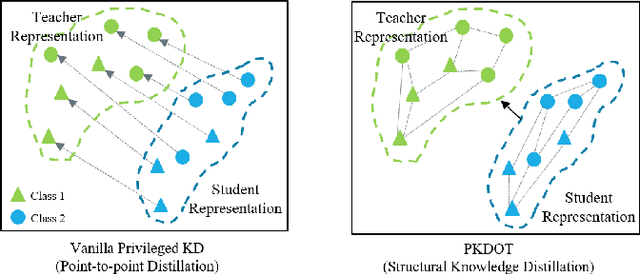
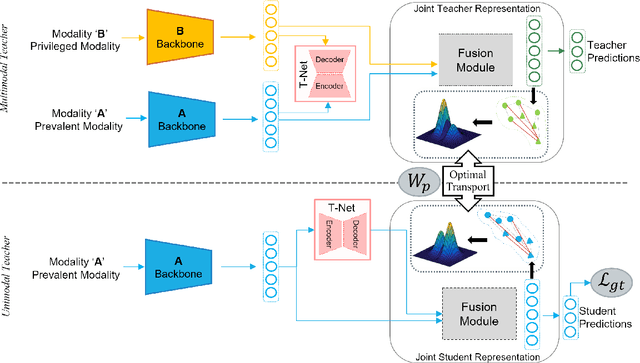
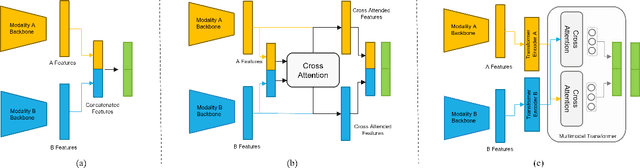
Multimodal affect recognition models have reached remarkable performance in the lab environment due to their ability to model complementary and redundant semantic information. However, these models struggle in the wild, mainly because of the unavailability or quality of modalities used for training. In practice, only a subset of the training-time modalities may be available at test time. Learning with privileged information (PI) enables deep learning models (DL) to exploit data from additional modalities only available during training. State-of-the-art knowledge distillation (KD) methods have been proposed to distill multiple teacher models (each trained on a modality) to a common student model. These privileged KD methods typically utilize point-to-point matching and have no explicit mechanism to capture the structural information in the teacher representation space formed by introducing the privileged modality. We argue that encoding this same structure in the student space may lead to enhanced student performance. This paper introduces a new structural KD mechanism based on optimal transport (OT), where entropy-regularized OT distills the structural dark knowledge. Privileged KD with OT (PKDOT) method captures the local structures in the multimodal teacher representation by calculating a cosine similarity matrix and selects the top-k anchors to allow for sparse OT solutions, resulting in a more stable distillation process. Experiments were performed on two different problems: pain estimation on the Biovid dataset (ordinal classification) and arousal-valance prediction on the Affwild2 dataset (regression). Results show that the proposed method can outperform state-of-the-art privileged KD methods on these problems. The diversity of different modalities and fusion architectures indicates that the proposed PKDOT method is modality and model-agnostic.
Subject-Based Domain Adaptation for Facial Expression Recognition
Dec 09, 2023



Adapting a deep learning (DL) model to a specific target individual is a challenging task in facial expression recognition (FER) that may be achieved using unsupervised domain adaptation (UDA) methods. Although several UDA methods have been proposed to adapt deep FER models across source and target data sets, multiple subject-specific source domains are needed to accurately represent the intra- and inter-person variability in subject-based adaption. In this paper, we consider the setting where domains correspond to individuals, not entire datasets. Unlike UDA, multi-source domain adaptation (MSDA) methods can leverage multiple source datasets to improve the accuracy and robustness of the target model. However, previous methods for MSDA adapt image classification models across datasets and do not scale well to a larger number of source domains. In this paper, a new MSDA method is introduced for subject-based domain adaptation in FER. It efficiently leverages information from multiple source subjects (labeled source domain data) to adapt a deep FER model to a single target individual (unlabeled target domain data). During adaptation, our Subject-based MSDA first computes a between-source discrepancy loss to mitigate the domain shift among data from several source subjects. Then, a new strategy is employed to generate augmented confident pseudo-labels for the target subject, allowing a reduction in the domain shift between source and target subjects. Experiments\footnote{\textcolor{red}{\textbf{Supplementary material} contains our code, which will be made public, and additional experimental results.}} on the challenging BioVid heat and pain dataset (PartA) with 87 subjects shows that our Subject-based MSDA can outperform state-of-the-art methods yet scale well to multiple subject-based source domains.