 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Affect to Complex Behavior: Advancing Multimodal Human-Centered AI at the 10th ABAW Workshop & Competition
May 24, 2026The 10th Affective & Behavior Analysis in-the-Wild (ABAW) Workshop and Competition, held at CVPR 2026, continues to advance research on modelling, analysis, understanding of human affect and behavior in real-world, unconstrained environments. The workshop maintains its dual structure, comprising both a competition and a paper track. The ABAW Competition introduces a diverse set of challenges targeting key aspects of affective and behavioral understanding, including continuous affect (valence-arousal) estimation, discrete affect (expression and action unit) recognition, as well as more complex behavior analysis tasks, such as emotional mimicry intensity estimation, ambivalence/hesitancy recognition and fine-grained violence detection. These challenges are built upon large-scale in-the-wild datasets, providing comprehensive benchmarks for state-of-the-art approaches. In parallel, the paper track presents a wide range of contributions spanning pose, motion & behavior estimation, affect modelling & multimodal learning, benchmarks, datasets & evaluation protocols, fairness, robustness & deployment. Overall, the 10th ABAW Workshop and Competition continues to serve as a key platform for benchmarking, collaboration and innovation, shaping the development of next-generation multimodal, human-centered AI systems.
Ambivalence/Hesitancy Recognition in Videos for Personalized Digital Health Interventions
Apr 14, 2026Using behavioural science, health interventions focus on behaviour change by providing a framework to help patients acquire and maintain healthy habits that improve medical outcomes. In-person interventions are costly and difficult to scale, especially in resource-limited regions. Digital health interventions offer a cost-effective approach, potentially supporting independent living and self-management. Automating such interventions, especially through machine learning, has gained considerable attention recently. Ambivalence and hesitancy (A/H) play a primary role for individuals to delay, avoid, or abandon health interventions. A/H are subtle and conflicting emotions that place a person in a state between positive and negative evaluations of a behaviour, or between acceptance and refusal to engage in it. They manifest as affective inconsistency across modalities or within a modality, such as language, facial, vocal expressions, and body language. While experts can be trained to recognize A/H, integrating them into digital health interventions is costly and less effective. Automatic A/H recognition is therefore critical for the personalization and cost-effectiveness of digital health interventions. Here, we explore the application of deep learning models for A/H recognition in videos, a multi-modal task by nature. In particular, this paper covers three learning setups: supervised learning, unsupervised domain adaptation for personalization, and zero-shot inference via large language models (LLMs). Our experiments are conducted on the unique and recently published BAH video dataset for A/H recognition. Our results show limited performance, suggesting that more adapted multi-modal models are required for accurate A/H recognition. Better methods for modeling spatio-temporal and multimodal fusion are necessary to leverage conflicts within/across modalities.
Test-Time Adaptation via Cache Personalization for Facial Expression Recognition in Videos
Mar 22, 2026Facial expression recognition (FER) in videos requires model personalization to capture the considerable variations across subjects. Vision-language models (VLMs) offer strong transfer to downstream tasks through image-text alignment, but their performance can still degrade under inter-subject distribution shifts. Personalizing models using test-time adaptation (TTA) methods can mitigate this challenge. However, most state-of-the-art TTA methods rely on unsupervised parameter optimization, introducing computational overhead that is impractical in many real-world applications. This paper introduces TTA through Cache Personalization (TTA-CaP), a cache-based TTA method that enables cost-effective (gradient-free) personalization of VLMs for video FER. Prior cache-based TTA methods rely solely on dynamic memories that store test samples, which can accumulate errors and drift due to noisy pseudo-labels. TTA-CaP leverages three coordinated caches: a personalized source cache that stores source-domain prototypes, a positive target cache that accumulates reliable subject-specific samples, and a negative target cache that stores low-confidence cases as negative samples to reduce the impact of noisy pseudo-labels. Cache updates and replacement are controlled by a tri-gate mechanism based on temporal stability, confidence, and consistency with the personalized cache. Finally, TTA-CaP refines predictions through fusion of embeddings, yielding refined representations that support temporally stable video-level predictions. Our experiments on three challenging video FER datasets, BioVid, StressID, and BAH, indicate that TTA-CaP can outperform state-of-the-art TTA methods under subject-specific and environmental shifts, while maintaining low computational and memory overhead for real-world deployment.
Longitudinal Risk Prediction in Mammography with Privileged History Distillation
Mar 16, 2026Breast cancer remains a leading cause of cancer-related mortality worldwide. Longitudinal mammography risk prediction models improve multi-year breast cancer risk prediction based on prior screening exams. However, in real-world clinical practice, longitudinal histories are often incomplete, irregular, or unavailable due to missed screenings, first-time examinations, heterogeneous acquisition schedules, or archival constraints. The absence of prior exams degrades the performance of longitudinal risk models and limits their practical applicability. While substantial longitudinal history is available during training, prior exams are commonly absent at test time. In this paper, we address missing history at inference time and propose a longitudinal risk prediction method that uses mammography history as privileged information during training and distills its prognostic value into a student model that only requires the current exam at inference time. The key idea is a privileged multi-teacher distillation scheme with horizon-specific teachers: each teacher is trained on the full longitudinal history to specialize in one prediction horizon, while the student receives only a reconstructed history derived from the current exam. This allows the student to inherit horizon-dependent longitudinal risk cues without requiring prior screening exams at deployment. Our new Privileged History Distillation (PHD) method is validated on a large longitudinal mammography dataset with multi-year cancer outcomes, CSAW-CC, comparing full-history and no-history baselines to their distilled counterparts. Using time-dependent AUC across horizons, our privileged history distillation method markedly improves the performance of long-horizon prediction over no-history models and is comparable to that of full-history models, while using only the current exam at inference time.
Adaptation of Weakly Supervised Localization in Histopathology by Debiasing Predictions
Mar 12, 2026Weakly Supervised Object Localization (WSOL) models enable joint classification and region-of-interest localization in histology images using only image-class supervision. When deployed in a target domain, distributions shift remains a major cause of performance degradation, especially when applied on new organs or institutions with different staining protocols and scanner characteristics. Under stronger cross-domain shifts, WSOL predictions can become biased toward dominant classes, producing highly skewed pseudo-label distributions in the target domain. Source-Free (Unsupervised) Domain Adaptation (SFDA) methods are commonly employed to address domain shift. However, because they rely on self-training, the initial bias is reinforced over training iterations, degrading both classification and localization tasks. We identify this amplification of prediction bias as a primary obstacle to the SFDA of WSOL models in histopathology. This paper introduces \sfdadep, a method inspired by machine unlearning that formulates SFDA as an iterative process of identifying and correcting prediction bias. It periodically identifies target images from over-predicted classes and selectively reduces the predictive confidence for uncertain (high entropy) images, while preserving confident predictions. This process reduces the drift of decision boundaries and bias toward dominant classes. A jointly optimized pixel-level classifier further restores discriminative localization features under distribution shift. Extensive experiments on cross-organ and -center histopathology benchmarks (glas, CAMELYON-16, CAMELYON-17) with several WSOL models show that SFDA-DeP consistently improves classification and localization over state-of-the-art SFDA baselines. {\small Code: \href{https://anonymous.4open.science/r/SFDA-DeP-1797/}{anonymous.4open.science/r/SFDA-DeP-1797/}}
BAH Dataset for Ambivalence/Hesitancy Recognition in Videos for Behavioural Change
May 25, 2025



Recognizing complex emotions linked to ambivalence and hesitancy (A/H) can play a critical role in the personalization and effectiveness of digital behaviour change interventions. These subtle and conflicting emotions are manifested by a discord between multiple modalities, such as facial and vocal expressions, and body language. Although experts can be trained to identify A/H, integrating them into digital interventions is costly and less effective. Automatic learning systems provide a cost-effective alternative that can adapt to individual users, and operate seamlessly within real-time, and resource-limited environments. However, there are currently no datasets available for the design of ML models to recognize A/H. This paper introduces a first Behavioural Ambivalence/Hesitancy (BAH) dataset collected for subject-based multimodal recognition of A/H in videos. It contains videos from 224 participants captured across 9 provinces in Canada, with different age, and ethnicity. Through our web platform, we recruited participants to answer 7 questions, some of which were designed to elicit A/H while recording themselves via webcam with microphone. BAH amounts to 1,118 videos for a total duration of 8.26 hours with 1.5 hours of A/H. Our behavioural team annotated timestamp segments to indicate where A/H occurs, and provide frame- and video-level annotations with the A/H cues. Video transcripts and their timestamps are also included, along with cropped and aligned faces in each frame, and a variety of participants meta-data. We include results baselines for BAH at frame- and video-level recognition in multi-modal setups, in addition to zero-shot prediction, and for personalization using unsupervised domain adaptation. The limited performance of baseline models highlights the challenges of recognizing A/H in real-world videos. The data, code, and pretrained weights are available.
PixelCAM: Pixel Class Activation Mapping for Histology Image Classification and ROI Localization
Mar 31, 2025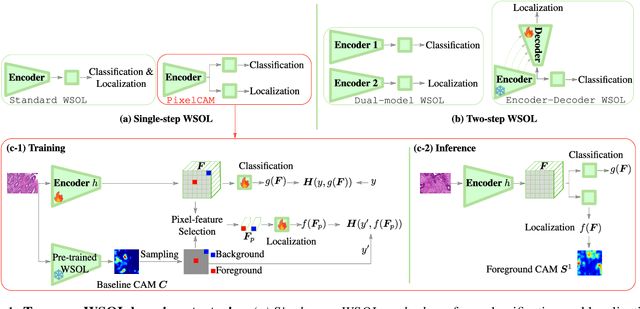



Weakly supervised object localization (WSOL) methods allow training models to classify images and localize ROIs. WSOL only requires low-cost image-class annotations yet provides a visually interpretable classifier, which is important in histology image analysis. Standard WSOL methods rely on class activation mapping (CAM) methods to produce spatial localization maps according to a single- or two-step strategy. While both strategies have made significant progress, they still face several limitations with histology images. Single-step methods can easily result in under- or over-activation due to the limited visual ROI saliency in histology images and the limited localization cues. They also face the well-known issue of asynchronous convergence between classification and localization tasks. The two-step approach is sub-optimal because it is tied to a frozen classifier, limiting the capacity for localization. Moreover, these methods also struggle when applied to out-of-distribution (OOD) datasets. In this paper, a multi-task approach for WSOL is introduced for simultaneous training of both tasks to address the asynchronous convergence problem. In particular, localization is performed in the pixel-feature space of an image encoder that is shared with classification. This allows learning discriminant features and accurate delineation of foreground/background regions to support ROI localization and image classification. We propose PixelCAM, a cost-effective foreground/background pixel-wise classifier in the pixel-feature space that allows for spatial object localization. PixelCAM is trained using pixel pseudo-labels collected from a pretrained WSOL model. Both image and pixel-wise classifiers are trained simultaneously using standard gradient descent. In addition, our pixel classifier can easily be integrated into CNN- and transformer-based architectures without any modifications.
Disentangled Source-Free Personalization for Facial Expression Recognition with Neutral Target Data
Mar 26, 2025



Facial Expression Recognition (FER) from videos is a crucial task in various application areas, such as human-computer interaction and health monitoring (e.g., pain, depression, fatigue, and stress). Beyond the challenges of recognizing subtle emotional or health states, the effectiveness of deep FER models is often hindered by the considerable variability of expressions among subjects. Source-free domain adaptation (SFDA) methods are employed to adapt a pre-trained source model using only unlabeled target domain data, thereby avoiding data privacy and storage issues. Typically, SFDA methods adapt to a target domain dataset corresponding to an entire population and assume it includes data from all recognition classes. However, collecting such comprehensive target data can be difficult or even impossible for FER in healthcare applications. In many real-world scenarios, it may be feasible to collect a short neutral control video (displaying only neutral expressions) for target subjects before deployment. These videos can be used to adapt a model to better handle the variability of expressions among subjects. This paper introduces the Disentangled Source-Free Domain Adaptation (DSFDA) method to address the SFDA challenge posed by missing target expression data. DSFDA leverages data from a neutral target control video for end-to-end generation and adaptation of target data with missing non-neutral data. Our method learns to disentangle features related to expressions and identity while generating the missing non-neutral target data, thereby enhancing model accuracy. Additionally, our self-supervision strategy improves model adaptation by reconstructing target images that maintain the same identity and source expression.
Text- and Feature-based Models for Compound Multimodal Emotion Recognition in the Wild
Jul 17, 2024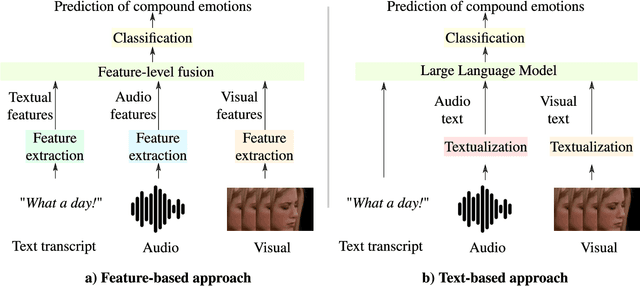
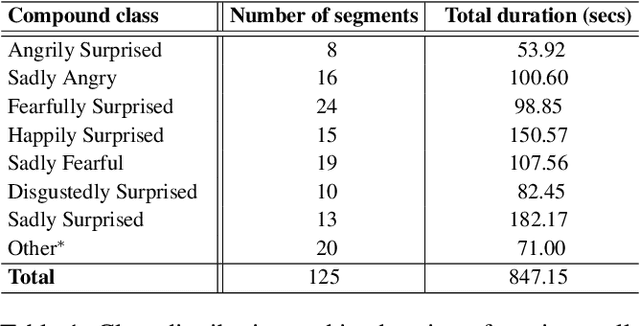


Systems for multimodal Emotion Recognition (ER) commonly rely on features extracted from different modalities (e.g., visual, audio, and textual) to predict the seven basic emotions. However, compound emotions often occur in real-world scenarios and are more difficult to predict. Compound multimodal ER becomes more challenging in videos due to the added uncertainty of diverse modalities. In addition, standard features-based models may not fully capture the complex and subtle cues needed to understand compound emotions. %%%% Since relevant cues can be extracted in the form of text, we advocate for textualizing all modalities, such as visual and audio, to harness the capacity of large language models (LLMs). These models may understand the complex interaction between modalities and the subtleties of complex emotions. Although training an LLM requires large-scale datasets, a recent surge of pre-trained LLMs, such as BERT and LLaMA, can be easily fine-tuned for downstream tasks like compound ER. This paper compares two multimodal modeling approaches for compound ER in videos -- standard feature-based vs. text-based. Experiments were conducted on the challenging C-EXPR-DB dataset for compound ER, and contrasted with results on the MELD dataset for basic ER. Our code is available
SR-CACO-2: A Dataset for Confocal Fluorescence Microscopy Image Super-Resolution
Jun 13, 2024



Confocal fluorescence microscopy is one of the most accessible and widely used imaging techniques for the study of biological processes. Scanning confocal microscopy allows the capture of high-quality images from 3D samples, yet suffers from well-known limitations such as photobleaching and phototoxicity of specimens caused by intense light exposure, which limits its use in some applications, especially for living cells. Cellular damage can be alleviated by changing imaging parameters to reduce light exposure, often at the expense of image quality. Machine/deep learning methods for single-image super-resolution (SISR) can be applied to restore image quality by upscaling lower-resolution (LR) images to produce high-resolution images (HR). These SISR methods have been successfully applied to photo-realistic images due partly to the abundance of publicly available data. In contrast, the lack of publicly available data partly limits their application and success in scanning confocal microscopy. In this paper, we introduce a large scanning confocal microscopy dataset named SR-CACO-2 that is comprised of low- and high-resolution image pairs marked for three different fluorescent markers. It allows the evaluation of performance of SISR methods on three different upscaling levels (X2, X4, X8). SR-CACO-2 contains the human epithelial cell line Caco-2 (ATCC HTB-37), and it is composed of 22 tiles that have been translated in the form of 9,937 image patches for experiments with SISR methods. Given the new SR-CACO-2 dataset, we also provide benchmarking results for 15 state-of-the-art methods that are representative of the main SISR families. Results show that these methods have limited success in producing high-resolution textures, indicating that SR-CACO-2 represents a challenging problem. Our dataset, code and pretrained weights are available: https://github.com/sbelharbi/sr-caco-2.