 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity Outperforms Low-Rank Projections in Few-Shot Adaptation
Apr 16, 2025Adapting Vision-Language Models (VLMs) to new domains with few labeled samples remains a significant challenge due to severe overfitting and computational constraints. State-of-the-art solutions, such as low-rank reparameterization, mitigate these issues but often struggle with generalization and require extensive hyperparameter tuning. In this paper, a novel Sparse Optimization (SO) framework is proposed. Unlike low-rank approaches that typically constrain updates to a fixed subspace, our SO method leverages high sparsity to dynamically adjust very few parameters. We introduce two key paradigms. First, we advocate for \textit{local sparsity and global density}, which updates a minimal subset of parameters per iteration while maintaining overall model expressiveness. As a second paradigm, we advocate for \textit{local randomness and global importance}, which sparsifies the gradient using random selection while pruning the first moment based on importance. This combination significantly mitigates overfitting and ensures stable adaptation in low-data regimes. Extensive experiments on 11 diverse datasets show that SO achieves state-of-the-art few-shot adaptation performance while reducing memory overhead.
Text- and Feature-based Models for Compound Multimodal Emotion Recognition in the Wild
Jul 17, 2024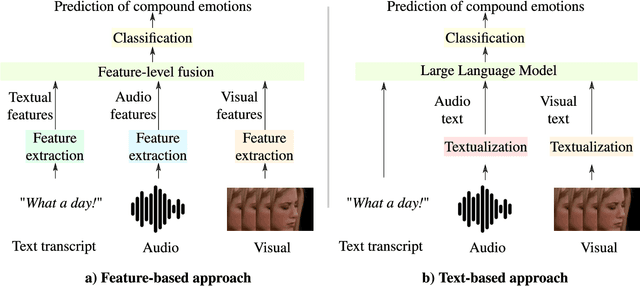
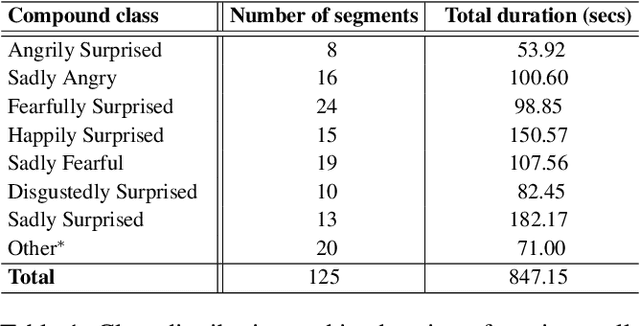


Systems for multimodal Emotion Recognition (ER) commonly rely on features extracted from different modalities (e.g., visual, audio, and textual) to predict the seven basic emotions. However, compound emotions often occur in real-world scenarios and are more difficult to predict. Compound multimodal ER becomes more challenging in videos due to the added uncertainty of diverse modalities. In addition, standard features-based models may not fully capture the complex and subtle cues needed to understand compound emotions. %%%% Since relevant cues can be extracted in the form of text, we advocate for textualizing all modalities, such as visual and audio, to harness the capacity of large language models (LLMs). These models may understand the complex interaction between modalities and the subtleties of complex emotions. Although training an LLM requires large-scale datasets, a recent surge of pre-trained LLMs, such as BERT and LLaMA, can be easily fine-tuned for downstream tasks like compound ER. This paper compares two multimodal modeling approaches for compound ER in videos -- standard feature-based vs. text-based. Experiments were conducted on the challenging C-EXPR-DB dataset for compound ER, and contrasted with results on the MELD dataset for basic ER. Our code is available