 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Deep Subspace Clustering Network
Dec 24, 2025Subspace clustering methods face inherent scalability limits due to the $O(n^3)$ cost (with $n$ denoting the number of data samples) of constructing full $n\times n$ affinities and performing spectral decomposition. While deep learning-based approaches improve feature extraction, they maintain this computational bottleneck through exhaustive pairwise similarity computations. We propose SDSNet (Scalable Deep Subspace Network), a deep subspace clustering framework that achieves $\mathcal{O}(n)$ complexity through (1) landmark-based approximation, avoiding full affinity matrices, (2) joint optimization of auto-encoder reconstruction with self-expression objectives, and (3) direct spectral clustering on factorized representations. The framework combines convolutional auto-encoders with subspace-preserving constraints. Experimental results demonstrate that SDSNet achieves comparable clustering quality to state-of-the-art methods with significantly improved computational efficiency.
* Published at the 2025 IEEE 12th International Conference on Data Science and Advanced Analytics (DSAA)
Low-Rank Expert Merging for Multi-Source Domain Adaptation in Person Re-Identification
Aug 09, 2025Adapting person re-identification (reID) models to new target environments remains a challenging problem that is typically addressed using unsupervised domain adaptation (UDA) methods. Recent works show that when labeled data originates from several distinct sources (e.g., datasets and cameras), considering each source separately and applying multi-source domain adaptation (MSDA) typically yields higher accuracy and robustness compared to blending the sources and performing conventional UDA. However, state-of-the-art MSDA methods learn domain-specific backbone models or require access to source domain data during adaptation, resulting in significant growth in training parameters and computational cost. In this paper, a Source-free Adaptive Gated Experts (SAGE-reID) method is introduced for person reID. Our SAGE-reID is a cost-effective, source-free MSDA method that first trains individual source-specific low-rank adapters (LoRA) through source-free UDA. Next, a lightweight gating network is introduced and trained to dynamically assign optimal merging weights for fusion of LoRA experts, enabling effective cross-domain knowledge transfer. While the number of backbone parameters remains constant across source domains, LoRA experts scale linearly but remain negligible in size (<= 2% of the backbone), reducing both the memory consumption and risk of overfitting. Extensive experiments conducted on three challenging benchmarks: Market-1501, DukeMTMC-reID, and MSMT17 indicate that SAGE-reID outperforms state-of-the-art methods while being computationally efficient.
Sparsity Outperforms Low-Rank Projections in Few-Shot Adaptation
Apr 16, 2025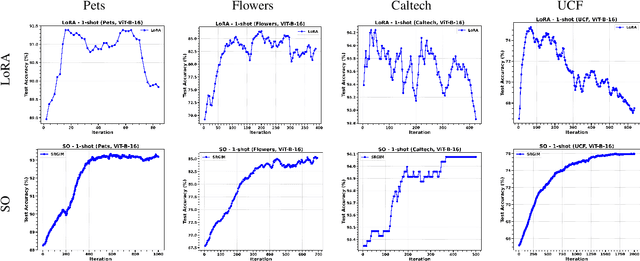
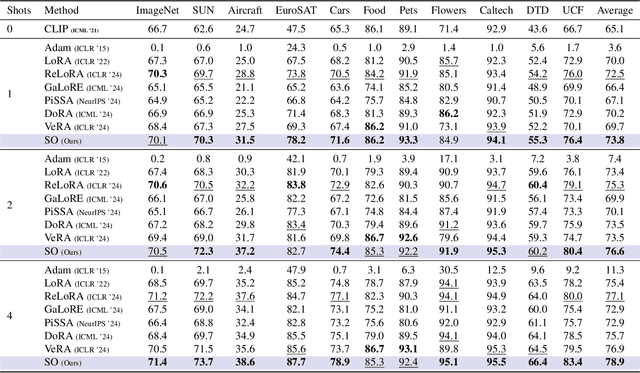
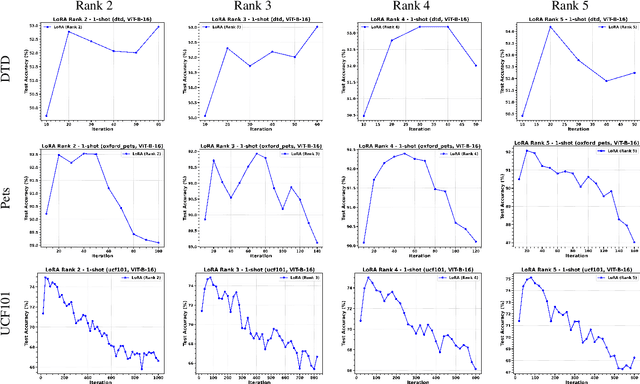
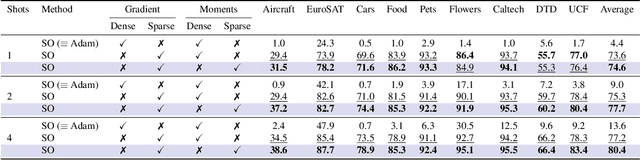
Adapting Vision-Language Models (VLMs) to new domains with few labeled samples remains a significant challenge due to severe overfitting and computational constraints. State-of-the-art solutions, such as low-rank reparameterization, mitigate these issues but often struggle with generalization and require extensive hyperparameter tuning. In this paper, a novel Sparse Optimization (SO) framework is proposed. Unlike low-rank approaches that typically constrain updates to a fixed subspace, our SO method leverages high sparsity to dynamically adjust very few parameters. We introduce two key paradigms. First, we advocate for \textit{local sparsity and global density}, which updates a minimal subset of parameters per iteration while maintaining overall model expressiveness. As a second paradigm, we advocate for \textit{local randomness and global importance}, which sparsifies the gradient using random selection while pruning the first moment based on importance. This combination significantly mitigates overfitting and ensures stable adaptation in low-data regimes. Extensive experiments on 11 diverse datasets show that SO achieves state-of-the-art few-shot adaptation performance while reducing memory overhead.
A Geometric Perspective for High-Dimensional Multiplex Graphs
Jan 29, 2025High-dimensional multiplex graphs are characterized by their high number of complementary and divergent dimensions. The existence of multiple hierarchical latent relations between the graph dimensions poses significant challenges to embedding methods. In particular, the geometric distortions that might occur in the representational space have been overlooked in the literature. This work studies the problem of high-dimensional multiplex graph embedding from a geometric perspective. We find that the node representations reside on highly curved manifolds, thus rendering their exploitation more challenging for downstream tasks. Moreover, our study reveals that increasing the number of graph dimensions can cause further distortions to the highly curved manifolds. To address this problem, we propose a novel multiplex graph embedding method that harnesses hierarchical dimension embedding and Hyperbolic Graph Neural Networks. The proposed approach hierarchically extracts hyperbolic node representations that reside on Riemannian manifolds while gradually learning fewer and more expressive latent dimensions of the multiplex graph. Experimental results on real-world high-dimensional multiplex graphs show that the synergy between hierarchical and hyperbolic embeddings incurs much fewer geometric distortions and brings notable improvements over state-of-the-art approaches on downstream tasks.
* Published in Proceedings of the ACM Conference on Information and Knowledge Management (CIKM) 2024, DOI: 10.1145/3627673.3679541
A Contrastive Variational Graph Auto-Encoder for Node Clustering
Dec 28, 2023Variational Graph Auto-Encoders (VGAEs) have been widely used to solve the node clustering task. However, the state-of-the-art methods have numerous challenges. First, existing VGAEs do not account for the discrepancy between the inference and generative models after incorporating the clustering inductive bias. Second, current models are prone to degenerate solutions that make the latent codes match the prior independently of the input signal (i.e., Posterior Collapse). Third, existing VGAEs overlook the effect of the noisy clustering assignments (i.e., Feature Randomness) and the impact of the strong trade-off between clustering and reconstruction (i.e., Feature Drift). To address these problems, we formulate a variational lower bound in a contrastive setting. Our lower bound is a tighter approximation of the log-likelihood function than the corresponding Evidence Lower BOund (ELBO). Thanks to a newly identified term, our lower bound can escape Posterior Collapse and has more flexibility to account for the difference between the inference and generative models. Additionally, our solution has two mechanisms to control the trade-off between Feature Randomness and Feature Drift. Extensive experiments show that the proposed method achieves state-of-the-art clustering results on several datasets. We provide strong evidence that this improvement is attributed to four aspects: integrating contrastive learning and alleviating Feature Randomness, Feature Drift, and Posterior Collapse.
Hierarchical Aggregations for High-Dimensional Multiplex Graph Embedding
Dec 28, 2023We investigate the problem of multiplex graph embedding, that is, graphs in which nodes interact through multiple types of relations (dimensions). In recent years, several methods have been developed to address this problem. However, the need for more effective and specialized approaches grows with the production of graph data with diverse characteristics. In particular, real-world multiplex graphs may exhibit a high number of dimensions, making it difficult to construct a single consensus representation. Furthermore, important information can be hidden in complex latent structures scattered in multiple dimensions. To address these issues, we propose HMGE, a novel embedding method based on hierarchical aggregation for high-dimensional multiplex graphs. Hierarchical aggregation consists of learning a hierarchical combination of the graph dimensions and refining the embeddings at each hierarchy level. Non-linear combinations are computed from previous ones, thus uncovering complex information and latent structures hidden in the multiplex graph dimensions. Moreover, we leverage mutual information maximization between local patches and global summaries to train the model without supervision. This allows to capture of globally relevant information present in diverse locations of the graph. Detailed experiments on synthetic and real-world data illustrate the suitability of our approach to downstream supervised tasks, including link prediction and node classification.
Rethinking Graph Auto-Encoder Models for Attributed Graph Clustering
Jul 24, 2021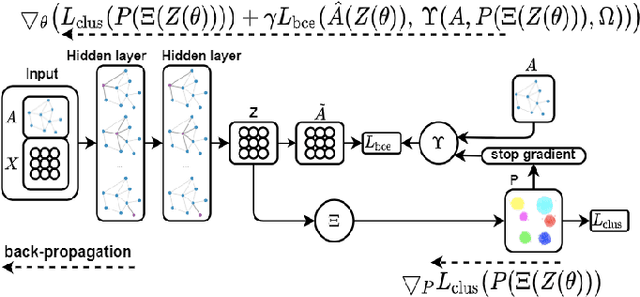
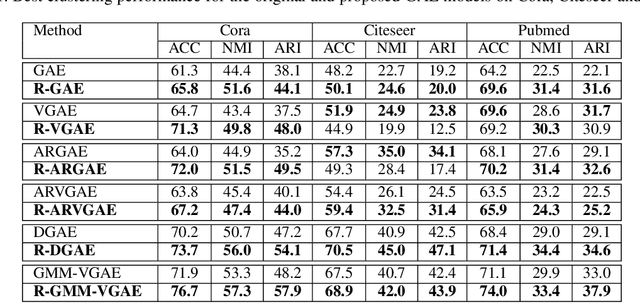
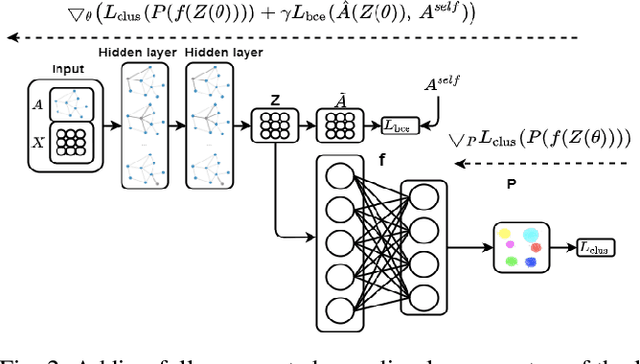
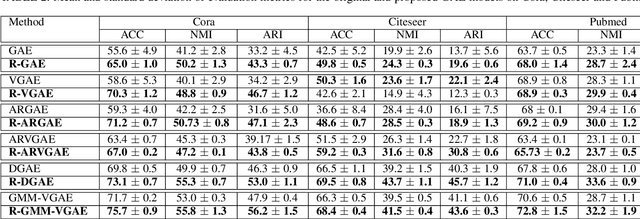
Most recent graph clustering methods have resorted to Graph Auto-Encoders (GAEs) to perform joint clustering and embedding learning. However, two critical issues have been overlooked. First, the accumulative error, inflicted by learning with noisy clustering assignments, degrades the effectiveness and robustness of the clustering model. This problem is called Feature Randomness. Second, reconstructing the adjacency matrix sets the model to learn irrelevant similarities for the clustering task. This problem is called Feature Drift. Interestingly, the theoretical relation between the aforementioned problems has not yet been investigated. We study these issues from two aspects: (1) there is a trade-off between Feature Randomness and Feature Drift when clustering and reconstruction are performed at the same level, and (2) the problem of Feature Drift is more pronounced for GAE models, compared with vanilla auto-encoder models, due to the graph convolutional operation and the graph decoding design. Motivated by these findings, we reformulate the GAE-based clustering methodology. Our solution is two-fold. First, we propose a sampling operator $\Xi$ that triggers a protection mechanism against the noisy clustering assignments. Second, we propose an operator $\Upsilon$ that triggers a correction mechanism against Feature Drift by gradually transforming the reconstructed graph into a clustering-oriented one. As principal advantages, our solution grants a considerable improvement in clustering effectiveness and robustness and can be easily tailored to existing GAE models.
Adversarial Deep Embedded Clustering: on a better trade-off between Feature Randomness and Feature Drift
Sep 26, 2019
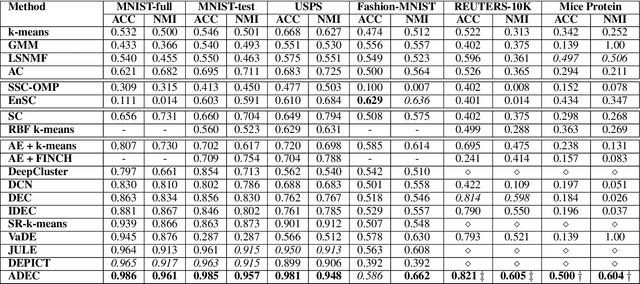


Clustering using deep autoencoders has been thoroughly investigated in recent years. Current approaches rely on simultaneously learning embedded features and clustering the data points in the latent space. Although numerous deep clustering approaches outperform the shallow models in achieving favorable results on several high-semantic datasets, a critical weakness of such models has been overlooked. In the absence of concrete supervisory signals, the embedded clustering objective function may distort the latent space by learning from unreliable pseudo-labels. Thus, the network can learn non-representative features, which in turn undermines the discriminative ability, yielding worse pseudo-labels. In order to alleviate the effect of random discriminative features, modern autoencoder-based clustering papers propose to use the reconstruction loss for pretraining and as a regularizer during the clustering phase. Nevertheless, a clustering-reconstruction trade-off can cause the \textit{Feature Drift} phenomena. In this paper, we propose ADEC (Adversarial Deep Embedded Clustering) a novel autoencoder-based clustering model, which addresses a dual problem, namely, \textit{Feature Randomness} and \textit{Feature Drift}, using adversarial training. We empirically demonstrate the suitability of our model on handling these problems using benchmark real datasets. Experimental results validate that our model outperforms state-of-the-art autoencoder-based clustering methods.
Deep Clustering with a Dynamic Autoencoder
Jan 23, 2019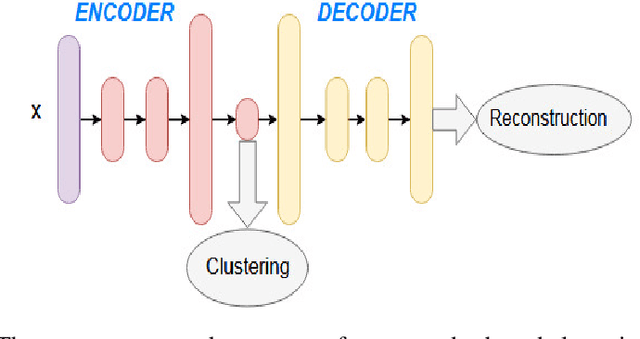


In unsupervised learning, there is no obvious straightforward loss function which can capture the major factors of variations and similarities. Since natural systems have smooth dynamics, an opportunity is lost if an unsupervised loss function remains static during the training process. The absence of concrete supervision suggests that smooth complex dynamics should be integrated as a substitute to the classical static loss functions to better make use of the gradual and uncertain knowledge acquired through self-supervision. In this paper, we propose Dynamic Autoencoder (DynAE), a new model for deep clustering that allows to solve a clustering-reconstruction trade-off by gradually and smoothly eliminating the reconstruction objective in favor of a construction one while preserving the space topology. Experimental evaluations on benchmark datasets show that our approach achieves state-of-the-art results compared to all the other autoencoder-based clustering methods.