 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Deep Subspace Clustering Network
Dec 24, 2025Subspace clustering methods face inherent scalability limits due to the $O(n^3)$ cost (with $n$ denoting the number of data samples) of constructing full $n\times n$ affinities and performing spectral decomposition. While deep learning-based approaches improve feature extraction, they maintain this computational bottleneck through exhaustive pairwise similarity computations. We propose SDSNet (Scalable Deep Subspace Network), a deep subspace clustering framework that achieves $\mathcal{O}(n)$ complexity through (1) landmark-based approximation, avoiding full affinity matrices, (2) joint optimization of auto-encoder reconstruction with self-expression objectives, and (3) direct spectral clustering on factorized representations. The framework combines convolutional auto-encoders with subspace-preserving constraints. Experimental results demonstrate that SDSNet achieves comparable clustering quality to state-of-the-art methods with significantly improved computational efficiency.
* Published at the 2025 IEEE 12th International Conference on Data Science and Advanced Analytics (DSAA)
A Geometric Perspective for High-Dimensional Multiplex Graphs
Jan 29, 2025High-dimensional multiplex graphs are characterized by their high number of complementary and divergent dimensions. The existence of multiple hierarchical latent relations between the graph dimensions poses significant challenges to embedding methods. In particular, the geometric distortions that might occur in the representational space have been overlooked in the literature. This work studies the problem of high-dimensional multiplex graph embedding from a geometric perspective. We find that the node representations reside on highly curved manifolds, thus rendering their exploitation more challenging for downstream tasks. Moreover, our study reveals that increasing the number of graph dimensions can cause further distortions to the highly curved manifolds. To address this problem, we propose a novel multiplex graph embedding method that harnesses hierarchical dimension embedding and Hyperbolic Graph Neural Networks. The proposed approach hierarchically extracts hyperbolic node representations that reside on Riemannian manifolds while gradually learning fewer and more expressive latent dimensions of the multiplex graph. Experimental results on real-world high-dimensional multiplex graphs show that the synergy between hierarchical and hyperbolic embeddings incurs much fewer geometric distortions and brings notable improvements over state-of-the-art approaches on downstream tasks.
* Published in Proceedings of the ACM Conference on Information and Knowledge Management (CIKM) 2024, DOI: 10.1145/3627673.3679541
Hierarchical Aggregations for High-Dimensional Multiplex Graph Embedding
Dec 28, 2023We investigate the problem of multiplex graph embedding, that is, graphs in which nodes interact through multiple types of relations (dimensions). In recent years, several methods have been developed to address this problem. However, the need for more effective and specialized approaches grows with the production of graph data with diverse characteristics. In particular, real-world multiplex graphs may exhibit a high number of dimensions, making it difficult to construct a single consensus representation. Furthermore, important information can be hidden in complex latent structures scattered in multiple dimensions. To address these issues, we propose HMGE, a novel embedding method based on hierarchical aggregation for high-dimensional multiplex graphs. Hierarchical aggregation consists of learning a hierarchical combination of the graph dimensions and refining the embeddings at each hierarchy level. Non-linear combinations are computed from previous ones, thus uncovering complex information and latent structures hidden in the multiplex graph dimensions. Moreover, we leverage mutual information maximization between local patches and global summaries to train the model without supervision. This allows to capture of globally relevant information present in diverse locations of the graph. Detailed experiments on synthetic and real-world data illustrate the suitability of our approach to downstream supervised tasks, including link prediction and node classification.
A Contrastive Variational Graph Auto-Encoder for Node Clustering
Dec 28, 2023Variational Graph Auto-Encoders (VGAEs) have been widely used to solve the node clustering task. However, the state-of-the-art methods have numerous challenges. First, existing VGAEs do not account for the discrepancy between the inference and generative models after incorporating the clustering inductive bias. Second, current models are prone to degenerate solutions that make the latent codes match the prior independently of the input signal (i.e., Posterior Collapse). Third, existing VGAEs overlook the effect of the noisy clustering assignments (i.e., Feature Randomness) and the impact of the strong trade-off between clustering and reconstruction (i.e., Feature Drift). To address these problems, we formulate a variational lower bound in a contrastive setting. Our lower bound is a tighter approximation of the log-likelihood function than the corresponding Evidence Lower BOund (ELBO). Thanks to a newly identified term, our lower bound can escape Posterior Collapse and has more flexibility to account for the difference between the inference and generative models. Additionally, our solution has two mechanisms to control the trade-off between Feature Randomness and Feature Drift. Extensive experiments show that the proposed method achieves state-of-the-art clustering results on several datasets. We provide strong evidence that this improvement is attributed to four aspects: integrating contrastive learning and alleviating Feature Randomness, Feature Drift, and Posterior Collapse.
Graph Attention Network for Camera Relocalization on Dynamic Scenes
Sep 29, 2022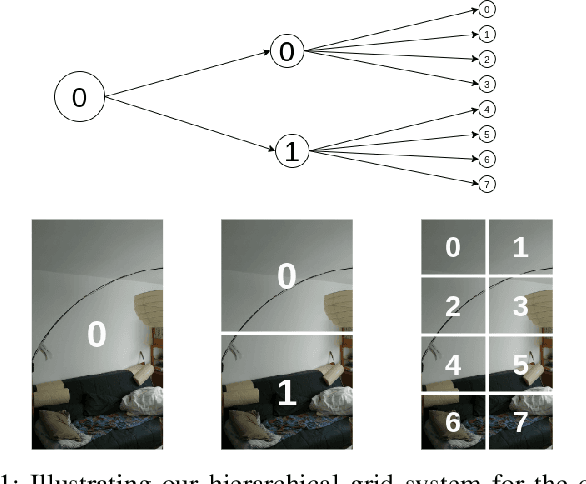
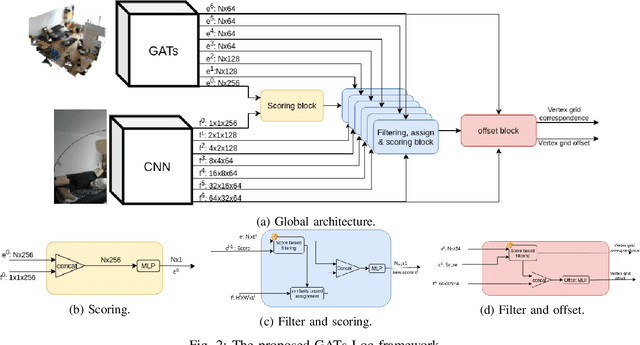
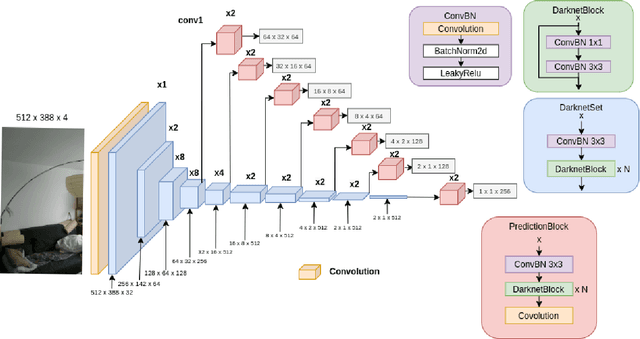
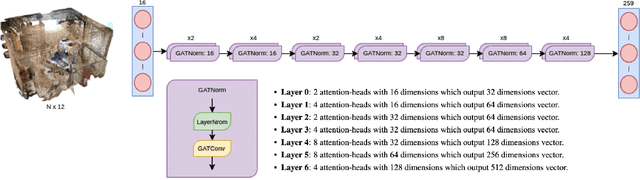
We devise a graph attention network-based approach for learning a scene triangle mesh representation in order to estimate an image camera position in a dynamic environment. Previous approaches built a scene-dependent model that explicitly or implicitly embeds the structure of the scene. They use convolution neural networks or decision trees to establish 2D/3D-3D correspondences. Such a mapping overfits the target scene and does not generalize well to dynamic changes in the environment. Our work introduces a novel approach to solve the camera relocalization problem by using the available triangle mesh. Our 3D-3D matching framework consists of three blocks: (1) a graph neural network to compute the embedding of mesh vertices, (2) a convolution neural network to compute the embedding of grid cells defined on the RGB-D image, and (3) a neural network model to establish the correspondence between the two embeddings. These three components are trained end-to-end. To predict the final pose, we run the RANSAC algorithm to generate camera pose hypotheses, and we refine the prediction using the point-cloud representation. Our approach significantly improves the camera pose accuracy of the state-of-the-art method from $0.358$ to $0.506$ on the RIO10 benchmark for dynamic indoor camera relocalization.
TopoDetect: Framework for Topological Features Detection in Graph Embeddings
Oct 08, 2021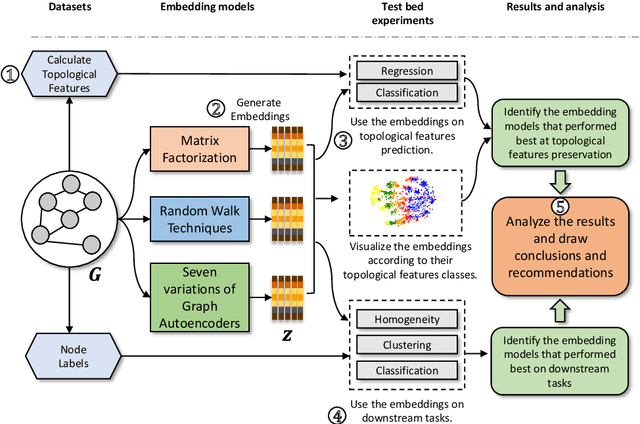
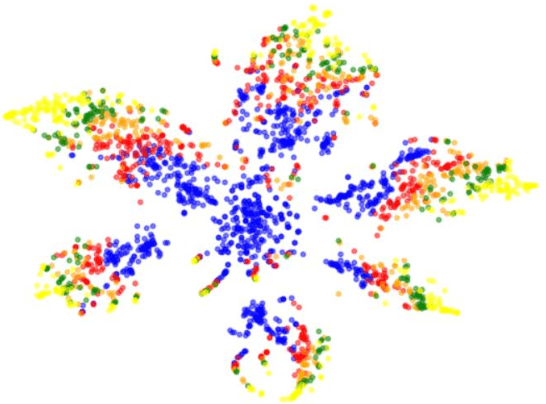
TopoDetect is a Python package that allows the user to investigate if important topological features, such as the Degree of the nodes, their Triangle Count, or their Local Clustering Score, are preserved in the embeddings of graph representation models. Additionally, the framework enables the visualization of the embeddings according to the distribution of the topological features among the nodes. Moreover, TopoDetect enables us to study the effect of the preservation of these features by evaluating the performance of the embeddings on downstream learning tasks such as clustering and classification.
Modeling Regime Shifts in Multiple Time Series
Sep 20, 2021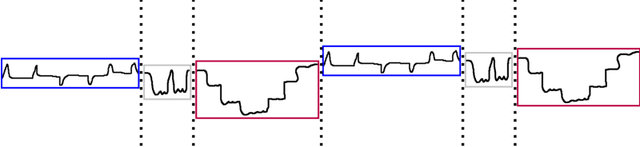
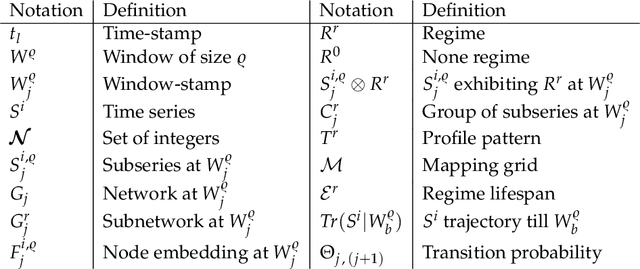


We investigate the problem of discovering and modeling regime shifts in an ecosystem comprising multiple time series known as co-evolving time series. Regime shifts refer to the changing behaviors exhibited by series at different time intervals. Learning these changing behaviors is a key step toward time series forecasting. While advances have been made, existing methods suffer from one or more of the following shortcomings: (1) failure to take relationships between time series into consideration for discovering regimes in multiple time series; (2) lack of an effective approach that models time-dependent behaviors exhibited by series; (3) difficulties in handling data discontinuities which may be informative. Most of the existing methods are unable to handle all of these three issues in a unified framework. This, therefore, motivates our effort to devise a principled approach for modeling interactions and time-dependency in co-evolving time series. Specifically, we model an ecosystem of multiple time series by summarizing the heavy ensemble of time series into a lighter and more meaningful structure called a \textit{mapping grid}. By using the mapping grid, our model first learns time series behavioral dependencies through a dynamic network representation, then learns the regime transition mechanism via a full time-dependent Cox regression model. The originality of our approach lies in modeling interactions between time series in regime identification and in modeling time-dependent regime transition probabilities, usually assumed to be static in existing work.
Rethinking Graph Auto-Encoder Models for Attributed Graph Clustering
Jul 24, 2021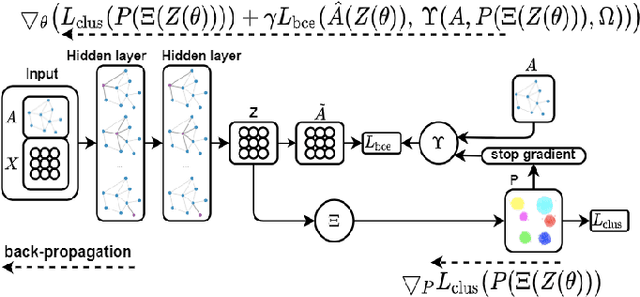
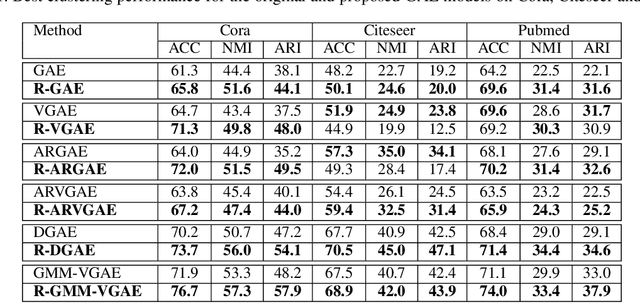
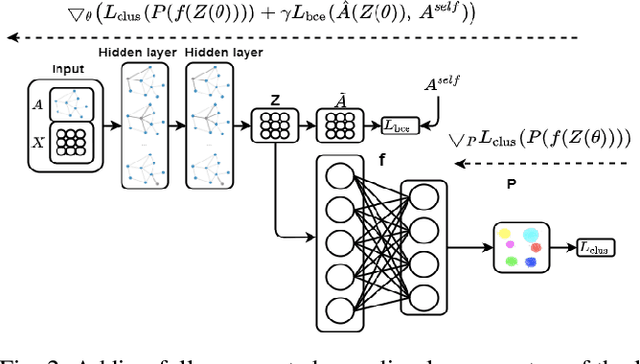
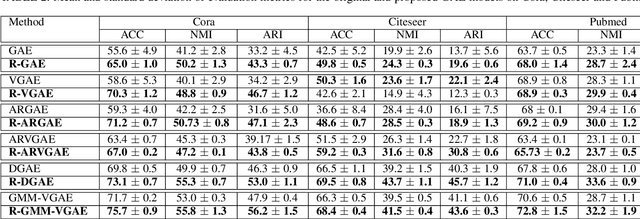
Most recent graph clustering methods have resorted to Graph Auto-Encoders (GAEs) to perform joint clustering and embedding learning. However, two critical issues have been overlooked. First, the accumulative error, inflicted by learning with noisy clustering assignments, degrades the effectiveness and robustness of the clustering model. This problem is called Feature Randomness. Second, reconstructing the adjacency matrix sets the model to learn irrelevant similarities for the clustering task. This problem is called Feature Drift. Interestingly, the theoretical relation between the aforementioned problems has not yet been investigated. We study these issues from two aspects: (1) there is a trade-off between Feature Randomness and Feature Drift when clustering and reconstruction are performed at the same level, and (2) the problem of Feature Drift is more pronounced for GAE models, compared with vanilla auto-encoder models, due to the graph convolutional operation and the graph decoding design. Motivated by these findings, we reformulate the GAE-based clustering methodology. Our solution is two-fold. First, we propose a sampling operator $\Xi$ that triggers a protection mechanism against the noisy clustering assignments. Second, we propose an operator $\Upsilon$ that triggers a correction mechanism against Feature Drift by gradually transforming the reconstructed graph into a clustering-oriented one. As principal advantages, our solution grants a considerable improvement in clustering effectiveness and robustness and can be easily tailored to existing GAE models.
Exploring the Representational Power of Graph Autoencoder
Jun 22, 2021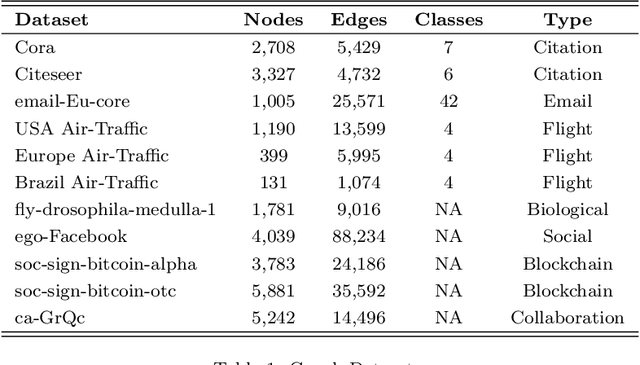
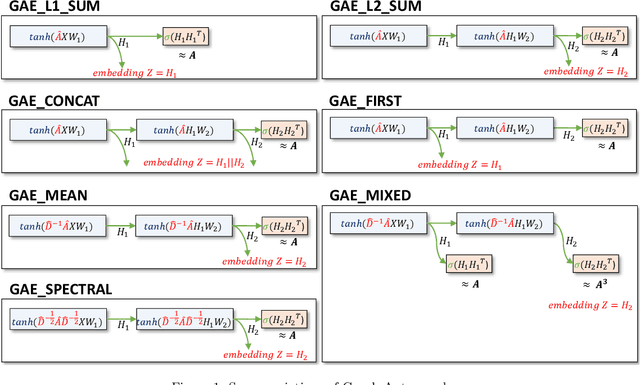
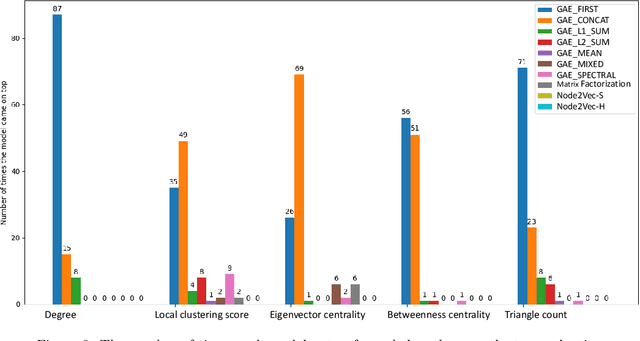

While representation learning has yielded a great success on many graph learning tasks, there is little understanding behind the structures that are being captured by these embeddings. For example, we wonder if the topological features, such as the Triangle Count, the Degree of the node and other centrality measures are concretely encoded in the embeddings. Furthermore, we ask if the presence of these structures in the embeddings is necessary for a better performance on the downstream tasks, such as clustering and classification. To address these questions, we conduct an extensive empirical study over three classes of unsupervised graph embedding models and seven different variants of Graph Autoencoders. Our results show that five topological features: the Degree, the Local Clustering Score, the Betweenness Centrality, the Eigenvector Centrality, and Triangle Count are concretely preserved in the first layer of the graph autoencoder that employs the SUM aggregation rule, under the condition that the model preserves the second-order proximity. We supplement further evidence for the presence of these features by revealing a hierarchy in the distribution of the topological features in the embeddings of the aforementioned model. We also show that a model with such properties can outperform other models on certain downstream tasks, especially when the preserved features are relevant to the task at hand. Finally, we evaluate the suitability of our findings through a test case study related to social influence prediction.
Context Matters: Self-Attention for Sign Language Recognition
Jan 12, 2021



This paper proposes an attentional network for the task of Continuous Sign Language Recognition. The proposed approach exploits co-independent streams of data to model the sign language modalities. These different channels of information can share a complex temporal structure between each other. For that reason, we apply attention to synchronize and help capture entangled dependencies between the different sign language components. Even though Sign Language is multi-channel, handshapes represent the central entities in sign interpretation. Seeing handshapes in their correct context defines the meaning of a sign. Taking that into account, we utilize the attention mechanism to efficiently aggregate the hand features with their appropriate spatio-temporal context for better sign recognition. We found that by doing so the model is able to identify the essential Sign Language components that revolve around the dominant hand and the face areas. We test our model on the benchmark dataset RWTH-PHOENIX-Weather 2014, yielding competitive results.