 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Deep Embedded Clustering: on a better trade-off between Feature Randomness and Feature Drift
Paper and Code
Sep 26, 2019
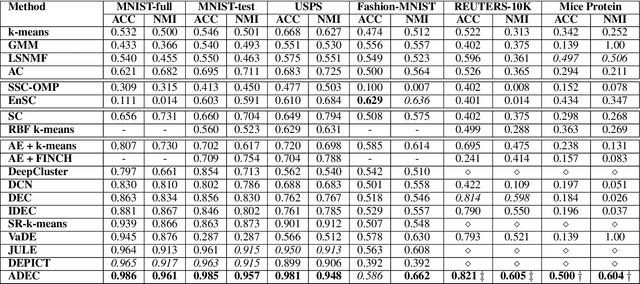


Clustering using deep autoencoders has been thoroughly investigated in recent years. Current approaches rely on simultaneously learning embedded features and clustering the data points in the latent space. Although numerous deep clustering approaches outperform the shallow models in achieving favorable results on several high-semantic datasets, a critical weakness of such models has been overlooked. In the absence of concrete supervisory signals, the embedded clustering objective function may distort the latent space by learning from unreliable pseudo-labels. Thus, the network can learn non-representative features, which in turn undermines the discriminative ability, yielding worse pseudo-labels. In order to alleviate the effect of random discriminative features, modern autoencoder-based clustering papers propose to use the reconstruction loss for pretraining and as a regularizer during the clustering phase. Nevertheless, a clustering-reconstruction trade-off can cause the \textit{Feature Drift} phenomena. In this paper, we propose ADEC (Adversarial Deep Embedded Clustering) a novel autoencoder-based clustering model, which addresses a dual problem, namely, \textit{Feature Randomness} and \textit{Feature Drift}, using adversarial training. We empirically demonstrate the suitability of our model on handling these problems using benchmark real datasets. Experimental results validate that our model outperforms state-of-the-art autoencoder-based clustering methods.