 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dynamically Weighted Loss Function for Unsupervised Image Segmentation
Mar 17, 2024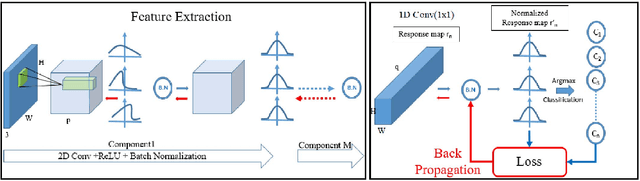


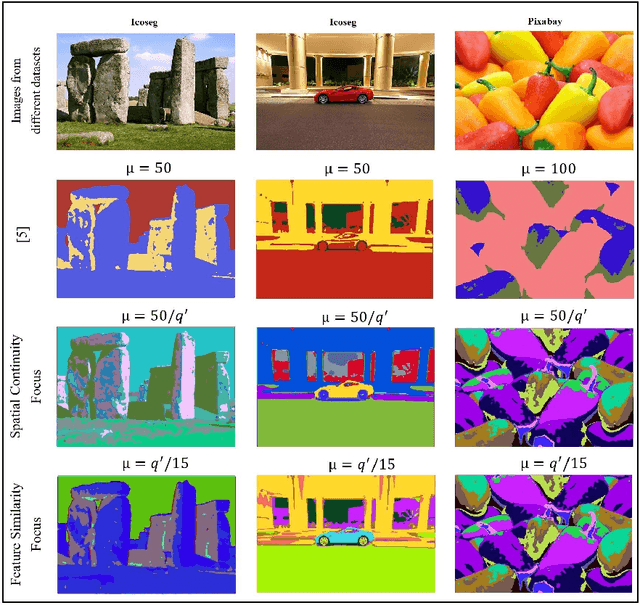
Image segmentation is the foundation of several computer vision tasks, where pixel-wise knowledge is a prerequisite for achieving the desired target. Deep learning has shown promising performance in supervised image segmentation. However, supervised segmentation algorithms require a massive amount of data annotated at a pixel level, thus limiting their applicability and scalability. Therefore, there is a need to invest in unsupervised learning for segmentation. This work presents an improved version of an unsupervised Convolutional Neural Network (CNN) based algorithm that uses a constant weight factor to balance between the segmentation criteria of feature similarity and spatial continuity, and it requires continuous manual adjustment of parameters depending on the degree of detail in the image and the dataset. In contrast, we propose a novel dynamic weighting scheme that leads to a flexible update of the parameters and an automatic tuning of the balancing weight between the two criteria above to bring out the details in the images in a genuinely unsupervised manner. We present quantitative and qualitative results on four datasets, which show that the proposed scheme outperforms the current unsupervised segmentation approaches without requiring manual adjustment.
A Contrastive Variational Graph Auto-Encoder for Node Clustering
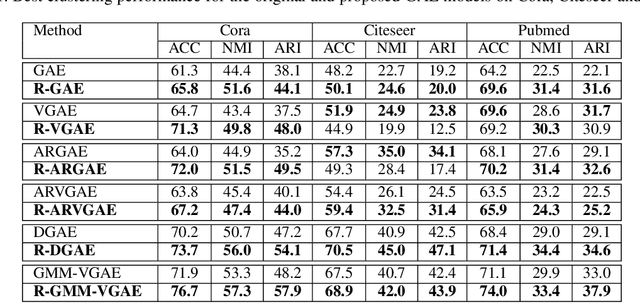
Dec 28, 2023Variational Graph Auto-Encoders (VGAEs) have been widely used to solve the node clustering task. However, the state-of-the-art methods have numerous challenges. First, existing VGAEs do not account for the discrepancy between the inference and generative models after incorporating the clustering inductive bias. Second, current models are prone to degenerate solutions that make the latent codes match the prior independently of the input signal (i.e., Posterior Collapse). Third, existing VGAEs overlook the effect of the noisy clustering assignments (i.e., Feature Randomness) and the impact of the strong trade-off between clustering and reconstruction (i.e., Feature Drift). To address these problems, we formulate a variational lower bound in a contrastive setting. Our lower bound is a tighter approximation of the log-likelihood function than the corresponding Evidence Lower BOund (ELBO). Thanks to a newly identified term, our lower bound can escape Posterior Collapse and has more flexibility to account for the difference between the inference and generative models. Additionally, our solution has two mechanisms to control the trade-off between Feature Randomness and Feature Drift. Extensive experiments show that the proposed method achieves state-of-the-art clustering results on several datasets. We provide strong evidence that this improvement is attributed to four aspects: integrating contrastive learning and alleviating Feature Randomness, Feature Drift, and Posterior Collapse.
Graph Attention Network for Camera Relocalization on Dynamic Scenes
Sep 29, 2022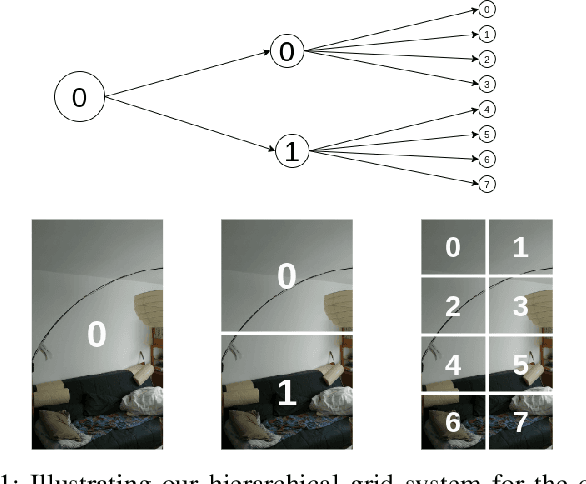
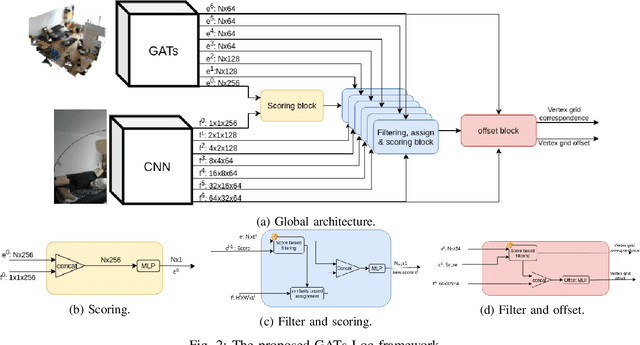
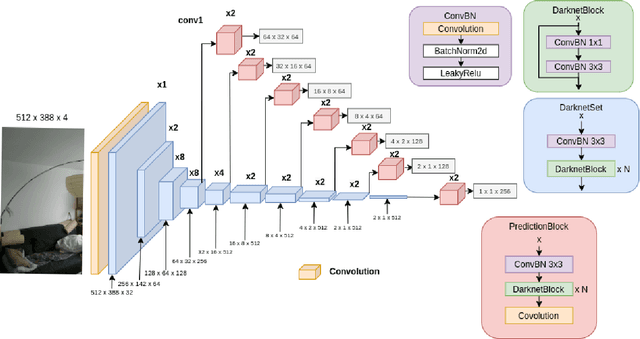
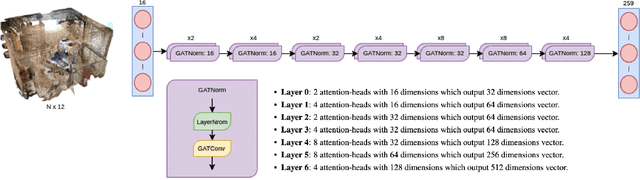
We devise a graph attention network-based approach for learning a scene triangle mesh representation in order to estimate an image camera position in a dynamic environment. Previous approaches built a scene-dependent model that explicitly or implicitly embeds the structure of the scene. They use convolution neural networks or decision trees to establish 2D/3D-3D correspondences. Such a mapping overfits the target scene and does not generalize well to dynamic changes in the environment. Our work introduces a novel approach to solve the camera relocalization problem by using the available triangle mesh. Our 3D-3D matching framework consists of three blocks: (1) a graph neural network to compute the embedding of mesh vertices, (2) a convolution neural network to compute the embedding of grid cells defined on the RGB-D image, and (3) a neural network model to establish the correspondence between the two embeddings. These three components are trained end-to-end. To predict the final pose, we run the RANSAC algorithm to generate camera pose hypotheses, and we refine the prediction using the point-cloud representation. Our approach significantly improves the camera pose accuracy of the state-of-the-art method from $0.358$ to $0.506$ on the RIO10 benchmark for dynamic indoor camera relocalization.
Rethinking Graph Auto-Encoder Models for Attributed Graph Clustering
Jul 24, 2021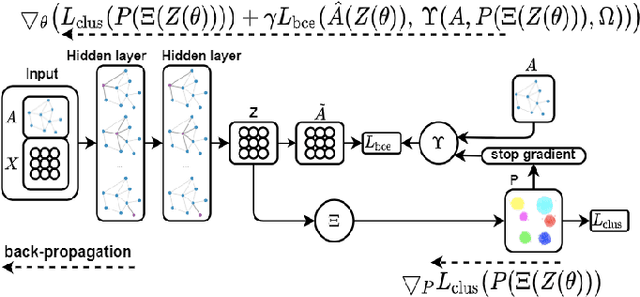
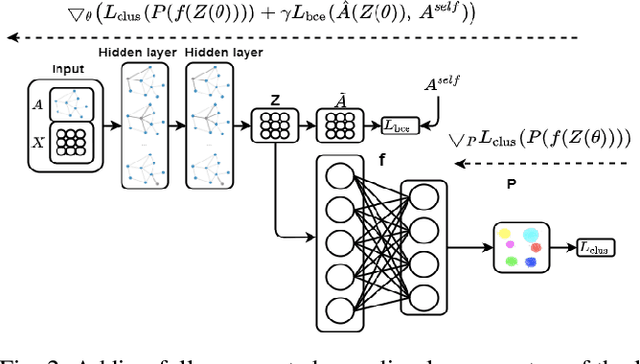
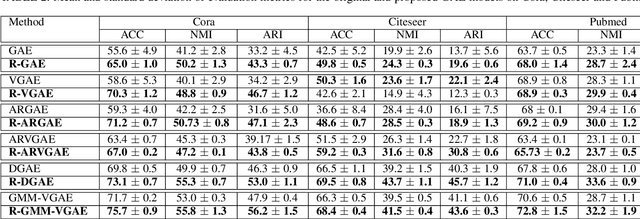
Most recent graph clustering methods have resorted to Graph Auto-Encoders (GAEs) to perform joint clustering and embedding learning. However, two critical issues have been overlooked. First, the accumulative error, inflicted by learning with noisy clustering assignments, degrades the effectiveness and robustness of the clustering model. This problem is called Feature Randomness. Second, reconstructing the adjacency matrix sets the model to learn irrelevant similarities for the clustering task. This problem is called Feature Drift. Interestingly, the theoretical relation between the aforementioned problems has not yet been investigated. We study these issues from two aspects: (1) there is a trade-off between Feature Randomness and Feature Drift when clustering and reconstruction are performed at the same level, and (2) the problem of Feature Drift is more pronounced for GAE models, compared with vanilla auto-encoder models, due to the graph convolutional operation and the graph decoding design. Motivated by these findings, we reformulate the GAE-based clustering methodology. Our solution is two-fold. First, we propose a sampling operator $\Xi$ that triggers a protection mechanism against the noisy clustering assignments. Second, we propose an operator $\Upsilon$ that triggers a correction mechanism against Feature Drift by gradually transforming the reconstructed graph into a clustering-oriented one. As principal advantages, our solution grants a considerable improvement in clustering effectiveness and robustness and can be easily tailored to existing GAE models.
Coarse-to-Fine Object Tracking Using Deep Features and Correlation Filters
Dec 23, 2020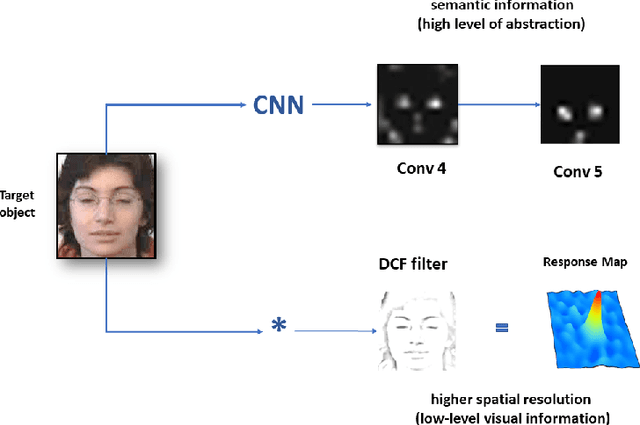



During the last years, deep learning trackers achieved stimulating results while bringing interesting ideas to solve the tracking problem. This progress is mainly due to the use of learned deep features obtained by training deep convolutional neural networks (CNNs) on large image databases. But since CNNs were originally developed for image classification, appearance modeling provided by their deep layers might be not enough discriminative for the tracking task. In fact,such features represent high-level information, that is more related to object category than to a specific instance of the object. Motivated by this observation, and by the fact that discriminative correlation filters(DCFs) may provide a complimentary low-level information, we presenta novel tracking algorithm taking advantage of both approaches. We formulate the tracking task as a two-stage procedure. First, we exploit the generalization ability of deep features to coarsely estimate target translation, while ensuring invariance to appearance change. Then, we capitalize on the discriminative power of correlation filters to precisely localize the tracked object. Furthermore, we designed an update control mechanism to learn appearance change while avoiding model drift. We evaluated the proposed tracker on object tracking benchmarks. Experimental results show the robustness of our algorithm, which performs favorably against CNN and DCF-based trackers. Code is available at: https://github.com/AhmedZgaren/Coarse-to-fine-Tracker
Adversarial Deep Embedded Clustering: on a better trade-off between Feature Randomness and Feature Drift
Sep 26, 2019
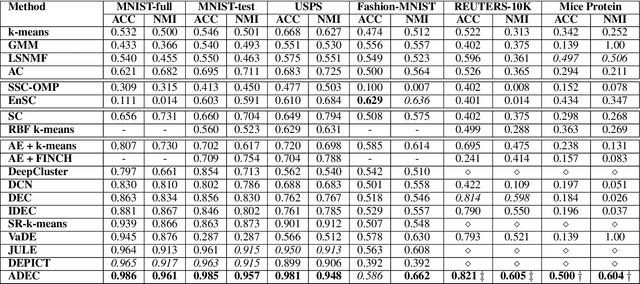


Clustering using deep autoencoders has been thoroughly investigated in recent years. Current approaches rely on simultaneously learning embedded features and clustering the data points in the latent space. Although numerous deep clustering approaches outperform the shallow models in achieving favorable results on several high-semantic datasets, a critical weakness of such models has been overlooked. In the absence of concrete supervisory signals, the embedded clustering objective function may distort the latent space by learning from unreliable pseudo-labels. Thus, the network can learn non-representative features, which in turn undermines the discriminative ability, yielding worse pseudo-labels. In order to alleviate the effect of random discriminative features, modern autoencoder-based clustering papers propose to use the reconstruction loss for pretraining and as a regularizer during the clustering phase. Nevertheless, a clustering-reconstruction trade-off can cause the \textit{Feature Drift} phenomena. In this paper, we propose ADEC (Adversarial Deep Embedded Clustering) a novel autoencoder-based clustering model, which addresses a dual problem, namely, \textit{Feature Randomness} and \textit{Feature Drift}, using adversarial training. We empirically demonstrate the suitability of our model on handling these problems using benchmark real datasets. Experimental results validate that our model outperforms state-of-the-art autoencoder-based clustering methods.
Deep Clustering with a Dynamic Autoencoder
Jan 23, 2019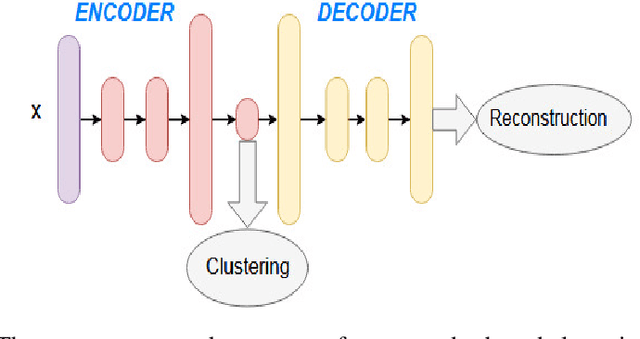


In unsupervised learning, there is no obvious straightforward loss function which can capture the major factors of variations and similarities. Since natural systems have smooth dynamics, an opportunity is lost if an unsupervised loss function remains static during the training process. The absence of concrete supervision suggests that smooth complex dynamics should be integrated as a substitute to the classical static loss functions to better make use of the gradual and uncertain knowledge acquired through self-supervision. In this paper, we propose Dynamic Autoencoder (DynAE), a new model for deep clustering that allows to solve a clustering-reconstruction trade-off by gradually and smoothly eliminating the reconstruction objective in favor of a construction one while preserving the space topology. Experimental evaluations on benchmark datasets show that our approach achieves state-of-the-art results compared to all the other autoencoder-based clustering methods.
Incremental One-Class Models for Data Classification
Oct 15, 2016In this paper we outline a PhD research plan. This research contributes to the field of one-class incremental learning and classification in case of non-stationary environments. The goal of this PhD is to define a new classification framework able to deal with very small learning dataset at the beginning of the process and with abilities to adjust itself according to the variability of the incoming data which create large scale datasets. As a preliminary work, incremental Covariance-guided One-Class Support Vector Machine is proposed to deal with sequentially obtained data. It is inspired from COSVM which put more emphasis on the low variance directions while keeping the basic formulation of incremental One-Class Support Vector Machine untouched. The incremental procedure is introduced by controlling the possible changes of support vectors after the addition of new data points, thanks to the Karush-Kuhn-Tucker conditions, that have to be maintained on all previously acquired data. Comparative experimental results with contemporary incremental and non-incremental one-class classifiers on numerous artificial and real data sets show that our method results in significantly better classification performance.