 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Graph Auto-Encoder Models for Attributed Graph Clustering
Jul 24, 2021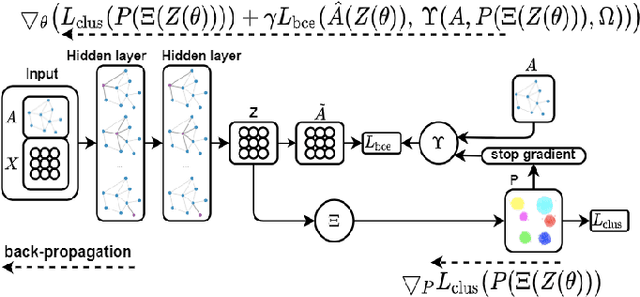
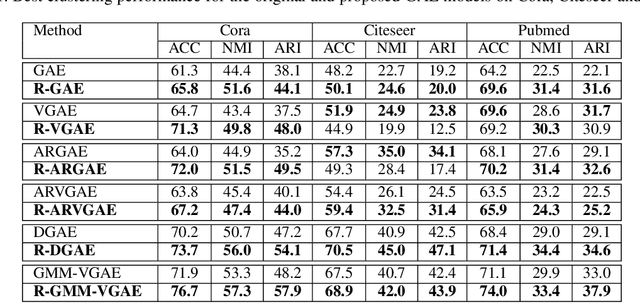
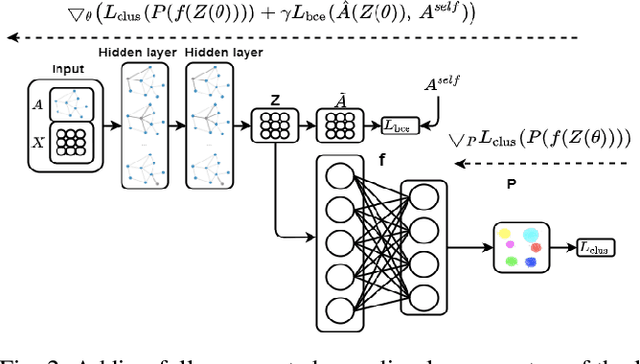
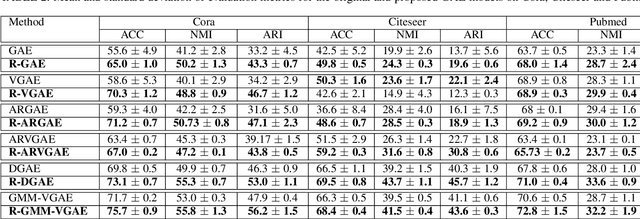
Most recent graph clustering methods have resorted to Graph Auto-Encoders (GAEs) to perform joint clustering and embedding learning. However, two critical issues have been overlooked. First, the accumulative error, inflicted by learning with noisy clustering assignments, degrades the effectiveness and robustness of the clustering model. This problem is called Feature Randomness. Second, reconstructing the adjacency matrix sets the model to learn irrelevant similarities for the clustering task. This problem is called Feature Drift. Interestingly, the theoretical relation between the aforementioned problems has not yet been investigated. We study these issues from two aspects: (1) there is a trade-off between Feature Randomness and Feature Drift when clustering and reconstruction are performed at the same level, and (2) the problem of Feature Drift is more pronounced for GAE models, compared with vanilla auto-encoder models, due to the graph convolutional operation and the graph decoding design. Motivated by these findings, we reformulate the GAE-based clustering methodology. Our solution is two-fold. First, we propose a sampling operator $\Xi$ that triggers a protection mechanism against the noisy clustering assignments. Second, we propose an operator $\Upsilon$ that triggers a correction mechanism against Feature Drift by gradually transforming the reconstructed graph into a clustering-oriented one. As principal advantages, our solution grants a considerable improvement in clustering effectiveness and robustness and can be easily tailored to existing GAE models.