 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-AUTT: Test-Time Personalization with Action Unit Prompting for Fine-Grained Video Emotion Recognition
Mar 31, 2026Personalization in emotion recognition (ER) is essential for an accurate interpretation of subtle and subject-specific expressive patterns. Recent advances in vision-language models (VLMs) such as CLIP demonstrate strong potential for leveraging joint image-text representations in ER. However, CLIP-based methods either depend on CLIP's contrastive pretraining or on LLMs to generate descriptive text prompts, which are noisy, computationally expensive, and fail to capture fine-grained expressions, leading to degraded performance. In this work, we leverage Action Units (AUs) as structured textual prompts within CLIP to model fine-grained facial expressions. AUs encode the subtle muscle activations underlying expressions, providing localized and interpretable semantic cues for more robust ER. We introduce CLIP-AU, a lightweight AU-guided temporal learning method that integrates interpretable AU semantics into CLIP. It learns generic, subject-agnostic representations by aligning AU prompts with facial dynamics, enabling fine-grained ER without CLIP fine-tuning or LLM-generated text supervision. Although CLIP-AU models fine-grained AU semantics, it does not adapt to subject-specific variability in subtle expressions. To address this limitation, we propose CLIP-AUTT, a video-based test-time personalization method that dynamically adapts AU prompts to videos from unseen subjects. By combining entropy-guided temporal window selection with prompt tuning, CLIP-AUTT enables subject-specific adaptation while preserving temporal consistency. Our extensive experiments on three challenging video-based subtle ER datasets, BioVid, StressID, and BAH, indicate that CLIP-AU and CLIP-AUTT outperform state-of-the-art CLIP-based FER and TTA methods, achieving robust and personalized subtle ER. Our code is publicly available at: https://github.com/osamazeeshan/CLIP-AUTT.
Test-Time Adaptation via Cache Personalization for Facial Expression Recognition in Videos
Mar 22, 2026Facial expression recognition (FER) in videos requires model personalization to capture the considerable variations across subjects. Vision-language models (VLMs) offer strong transfer to downstream tasks through image-text alignment, but their performance can still degrade under inter-subject distribution shifts. Personalizing models using test-time adaptation (TTA) methods can mitigate this challenge. However, most state-of-the-art TTA methods rely on unsupervised parameter optimization, introducing computational overhead that is impractical in many real-world applications. This paper introduces TTA through Cache Personalization (TTA-CaP), a cache-based TTA method that enables cost-effective (gradient-free) personalization of VLMs for video FER. Prior cache-based TTA methods rely solely on dynamic memories that store test samples, which can accumulate errors and drift due to noisy pseudo-labels. TTA-CaP leverages three coordinated caches: a personalized source cache that stores source-domain prototypes, a positive target cache that accumulates reliable subject-specific samples, and a negative target cache that stores low-confidence cases as negative samples to reduce the impact of noisy pseudo-labels. Cache updates and replacement are controlled by a tri-gate mechanism based on temporal stability, confidence, and consistency with the personalized cache. Finally, TTA-CaP refines predictions through fusion of embeddings, yielding refined representations that support temporally stable video-level predictions. Our experiments on three challenging video FER datasets, BioVid, StressID, and BAH, indicate that TTA-CaP can outperform state-of-the-art TTA methods under subject-specific and environmental shifts, while maintaining low computational and memory overhead for real-world deployment.
LT-Soups: Bridging Head and Tail Classes via Subsampled Model Soups
Nov 11, 2025Real-world datasets typically exhibit long-tailed (LT) distributions, where a few head classes dominate and many tail classes are severely underrepresented. While recent work shows that parameter-efficient fine-tuning (PEFT) methods like LoRA and AdaptFormer preserve tail-class performance on foundation models such as CLIP, we find that they do so at the cost of head-class accuracy. We identify the head-tail ratio, the proportion of head to tail classes, as a crucial but overlooked factor influencing this trade-off. Through controlled experiments on CIFAR100 with varying imbalance ratio ($ρ$) and head-tail ratio ($η$), we show that PEFT excels in tail-heavy scenarios but degrades in more balanced and head-heavy distributions. To overcome these limitations, we propose LT-Soups, a two-stage model soups framework designed to generalize across diverse LT regimes. In the first stage, LT-Soups averages models fine-tuned on balanced subsets to reduce head-class bias; in the second, it fine-tunes only the classifier on the full dataset to restore head-class accuracy. Experiments across six benchmark datasets show that LT-Soups achieves superior trade-offs compared to both PEFT and traditional model soups across a wide range of imbalance regimes.
Revisiting Mixout: An Overlooked Path to Robust Finetuning
Oct 08, 2025Finetuning vision foundation models often improves in-domain accuracy but comes at the cost of robustness under distribution shift. We revisit Mixout, a stochastic regularizer that intermittently replaces finetuned weights with their pretrained reference, through the lens of a single-run, weight-sharing implicit ensemble. This perspective reveals three key levers that govern robustness: the \emph{masking anchor}, \emph{resampling frequency}, and \emph{mask sparsity}. Guided by this analysis, we introduce GMixout, which (i) replaces the fixed anchor with an exponential moving-average snapshot that adapts during training, and (ii) regulates masking period via an explicit resampling-frequency hyperparameter. Our sparse-kernel implementation updates only a small fraction of parameters with no inference-time overhead, enabling training on consumer-grade GPUs. Experiments on benchmarks covering covariate shift, corruption, and class imbalance, ImageNet / ImageNet-LT, DomainNet, iWildCam, and CIFAR100-C, GMixout consistently improves in-domain accuracy beyond zero-shot performance while surpassing both Model Soups and strong parameter-efficient finetuning baselines under distribution shift.
High-Rate Mixout: Revisiting Mixout for Robust Domain Generalization
Oct 08, 2025Ensembling fine-tuned models initialized from powerful pre-trained weights is a common strategy to improve robustness under distribution shifts, but it comes with substantial computational costs due to the need to train and store multiple models. Dropout offers a lightweight alternative by simulating ensembles through random neuron deactivation; however, when applied to pre-trained models, it tends to over-regularize and disrupt critical representations necessary for generalization. In this work, we investigate Mixout, a stochastic regularization technique that provides an alternative to Dropout for domain generalization. Rather than deactivating neurons, Mixout mitigates overfitting by probabilistically swapping a subset of fine-tuned weights with their pre-trained counterparts during training, thereby maintaining a balance between adaptation and retention of prior knowledge. Our study reveals that achieving strong performance with Mixout on domain generalization benchmarks requires a notably high masking probability of 0.9 for ViTs and 0.8 for ResNets. While this may seem like a simple adjustment, it yields two key advantages for domain generalization: (1) higher masking rates more strongly penalize deviations from the pre-trained parameters, promoting better generalization to unseen domains; and (2) high-rate masking substantially reduces computational overhead, cutting gradient computation by up to 45% and gradient memory usage by up to 90%. Experiments across five domain generalization benchmarks, PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet, using ResNet and ViT architectures, show that our approach, High-rate Mixout, achieves out-of-domain accuracy comparable to ensemble-based methods while significantly reducing training costs.
VLOD-TTA: Test-Time Adaptation of Vision-Language Object Detectors
Oct 01, 2025Vision-language object detectors (VLODs) such as YOLO-World and Grounding DINO achieve impressive zero-shot recognition by aligning region proposals with text representations. However, their performance often degrades under domain shift. We introduce VLOD-TTA, a test-time adaptation (TTA) framework for VLODs that leverages dense proposal overlap and image-conditioned prompt scores. First, an IoU-weighted entropy objective is proposed that concentrates adaptation on spatially coherent proposal clusters and reduces confirmation bias from isolated boxes. Second, image-conditioned prompt selection is introduced, which ranks prompts by image-level compatibility and fuses the most informative prompts with the detector logits. Our benchmarking across diverse distribution shifts -- including stylized domains, driving scenes, low-light conditions, and common corruptions -- shows the effectiveness of our method on two state-of-the-art VLODs, YOLO-World and Grounding DINO, with consistent improvements over the zero-shot and TTA baselines. Code : https://github.com/imatif17/VLOD-TTA
MuSACo: Multimodal Subject-Specific Selection and Adaptation for Expression Recognition with Co-Training
Aug 17, 2025Personalized expression recognition (ER) involves adapting a machine learning model to subject-specific data for improved recognition of expressions with considerable interpersonal variability. Subject-specific ER can benefit significantly from multi-source domain adaptation (MSDA) methods, where each domain corresponds to a specific subject, to improve model accuracy and robustness. Despite promising results, state-of-the-art MSDA approaches often overlook multimodal information or blend sources into a single domain, limiting subject diversity and failing to explicitly capture unique subject-specific characteristics. To address these limitations, we introduce MuSACo, a multi-modal subject-specific selection and adaptation method for ER based on co-training. It leverages complementary information across multiple modalities and multiple source domains for subject-specific adaptation. This makes MuSACo particularly relevant for affective computing applications in digital health, such as patient-specific assessment for stress or pain, where subject-level nuances are crucial. MuSACo selects source subjects relevant to the target and generates pseudo-labels using the dominant modality for class-aware learning, in conjunction with a class-agnostic loss to learn from less confident target samples. Finally, source features from each modality are aligned, while only confident target features are combined. Our experimental results on challenging multimodal ER datasets: BioVid and StressID, show that MuSACo can outperform UDA (blending) and state-of-the-art MSDA methods.
Low-Rank Expert Merging for Multi-Source Domain Adaptation in Person Re-Identification
Aug 09, 2025Adapting person re-identification (reID) models to new target environments remains a challenging problem that is typically addressed using unsupervised domain adaptation (UDA) methods. Recent works show that when labeled data originates from several distinct sources (e.g., datasets and cameras), considering each source separately and applying multi-source domain adaptation (MSDA) typically yields higher accuracy and robustness compared to blending the sources and performing conventional UDA. However, state-of-the-art MSDA methods learn domain-specific backbone models or require access to source domain data during adaptation, resulting in significant growth in training parameters and computational cost. In this paper, a Source-free Adaptive Gated Experts (SAGE-reID) method is introduced for person reID. Our SAGE-reID is a cost-effective, source-free MSDA method that first trains individual source-specific low-rank adapters (LoRA) through source-free UDA. Next, a lightweight gating network is introduced and trained to dynamically assign optimal merging weights for fusion of LoRA experts, enabling effective cross-domain knowledge transfer. While the number of backbone parameters remains constant across source domains, LoRA experts scale linearly but remain negligible in size (<= 2% of the backbone), reducing both the memory consumption and risk of overfitting. Extensive experiments conducted on three challenging benchmarks: Market-1501, DukeMTMC-reID, and MSMT17 indicate that SAGE-reID outperforms state-of-the-art methods while being computationally efficient.
Rendering-Aware Reinforcement Learning for Vector Graphics Generation
May 27, 2025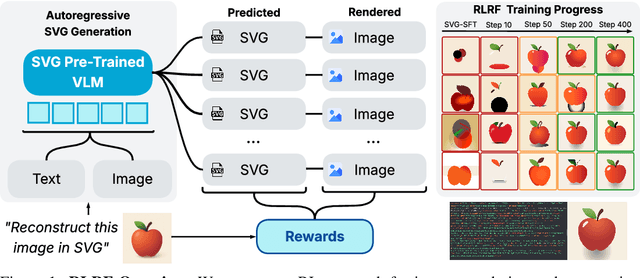
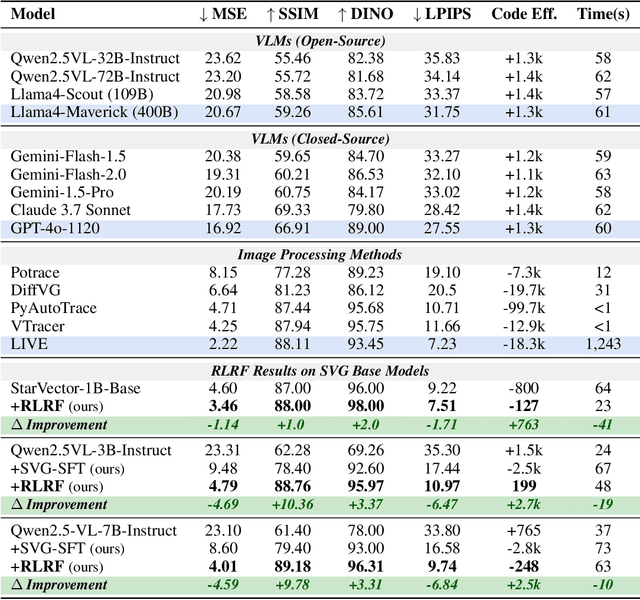
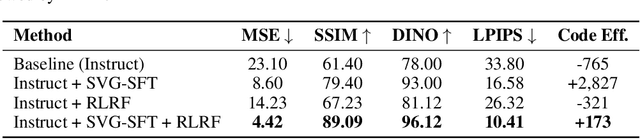
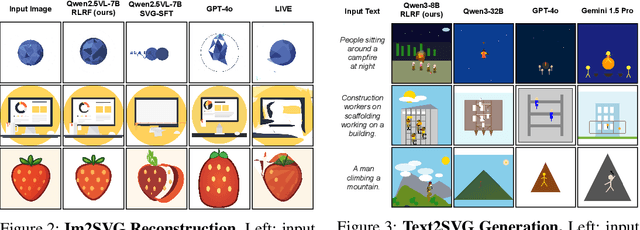
Scalable Vector Graphics (SVG) offer a powerful format for representing visual designs as interpretable code. Recent advances in vision-language models (VLMs) have enabled high-quality SVG generation by framing the problem as a code generation task and leveraging large-scale pretraining. VLMs are particularly suitable for this task as they capture both global semantics and fine-grained visual patterns, while transferring knowledge across vision, natural language, and code domains. However, existing VLM approaches often struggle to produce faithful and efficient SVGs because they never observe the rendered images during training. Although differentiable rendering for autoregressive SVG code generation remains unavailable, rendered outputs can still be compared to original inputs, enabling evaluative feedback suitable for reinforcement learning (RL). We introduce RLRF(Reinforcement Learning from Rendering Feedback), an RL method that enhances SVG generation in autoregressive VLMs by leveraging feedback from rendered SVG outputs. Given an input image, the model generates SVG roll-outs that are rendered and compared to the original image to compute a reward. This visual fidelity feedback guides the model toward producing more accurate, efficient, and semantically coherent SVGs. RLRF significantly outperforms supervised fine-tuning, addressing common failure modes and enabling precise, high-quality SVG generation with strong structural understanding and generalization.
BAH Dataset for Ambivalence/Hesitancy Recognition in Videos for Behavioural Change
May 25, 2025



Recognizing complex emotions linked to ambivalence and hesitancy (A/H) can play a critical role in the personalization and effectiveness of digital behaviour change interventions. These subtle and conflicting emotions are manifested by a discord between multiple modalities, such as facial and vocal expressions, and body language. Although experts can be trained to identify A/H, integrating them into digital interventions is costly and less effective. Automatic learning systems provide a cost-effective alternative that can adapt to individual users, and operate seamlessly within real-time, and resource-limited environments. However, there are currently no datasets available for the design of ML models to recognize A/H. This paper introduces a first Behavioural Ambivalence/Hesitancy (BAH) dataset collected for subject-based multimodal recognition of A/H in videos. It contains videos from 224 participants captured across 9 provinces in Canada, with different age, and ethnicity. Through our web platform, we recruited participants to answer 7 questions, some of which were designed to elicit A/H while recording themselves via webcam with microphone. BAH amounts to 1,118 videos for a total duration of 8.26 hours with 1.5 hours of A/H. Our behavioural team annotated timestamp segments to indicate where A/H occurs, and provide frame- and video-level annotations with the A/H cues. Video transcripts and their timestamps are also included, along with cropped and aligned faces in each frame, and a variety of participants meta-data. We include results baselines for BAH at frame- and video-level recognition in multi-modal setups, in addition to zero-shot prediction, and for personalization using unsupervised domain adaptation. The limited performance of baseline models highlights the challenges of recognizing A/H in real-world videos. The data, code, and pretrained weights are available.