 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Modality Prompt for Adapting Vision-Language Object Detectors
Dec 01, 2024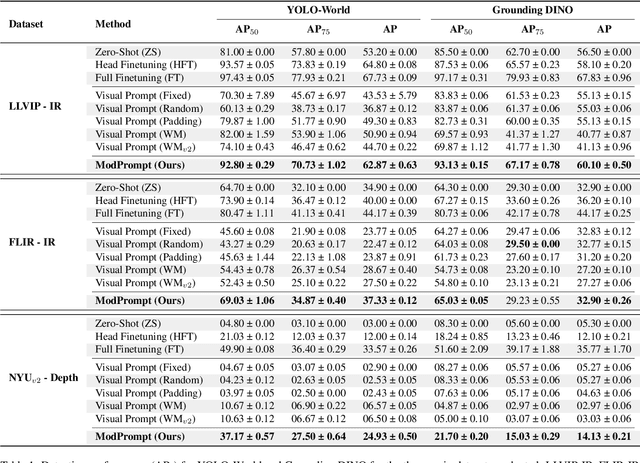

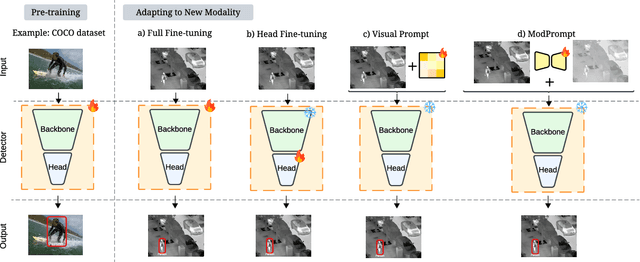
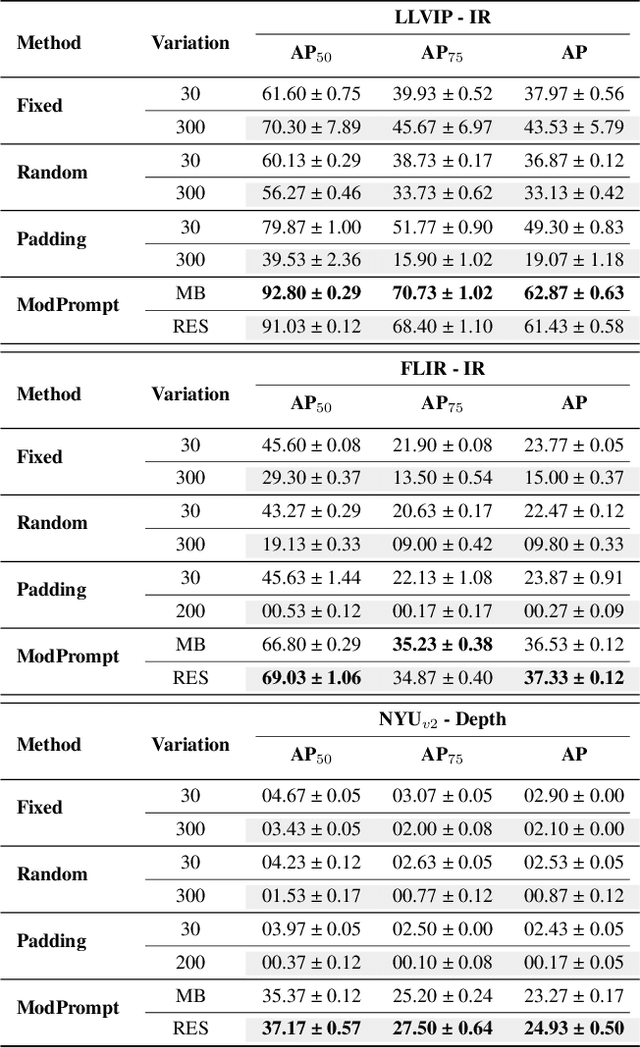
The zero-shot performance of object detectors degrades when tested on different modalities, such as infrared and depth. While recent work has explored image translation techniques to adapt detectors to new modalities, these methods are limited to a single modality and apply only to traditional detectors. Recently, vision-language detectors, such as YOLO-World and Grounding DINO, have shown promising zero-shot capabilities, however, they have not yet been adapted for other visual modalities. Traditional fine-tuning approaches tend to compromise the zero-shot capabilities of the detectors. The visual prompt strategies commonly used for classification with vision-language models apply the same linear prompt translation to each image making them less effective. To address these limitations, we propose ModPrompt, a visual prompt strategy to adapt vision-language detectors to new modalities without degrading zero-shot performance. In particular, an encoder-decoder visual prompt strategy is proposed, further enhanced by the integration of inference-friendly task residuals, facilitating more robust adaptation. Empirically, we benchmark our method for modality adaptation on two vision-language detectors, YOLO-World and Grounding DINO, and on challenging infrared (LLVIP, FLIR) and depth (NYUv2) data, achieving performance comparable to full fine-tuning while preserving the model's zero-shot capability. Our code is available at: https://github.com/heitorrapela/ModPrompt
Class Semantics-based Attention for Action Detection
Sep 06, 2021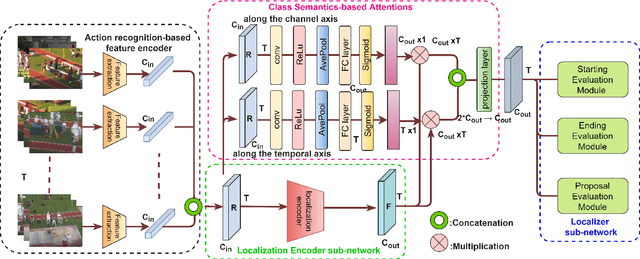
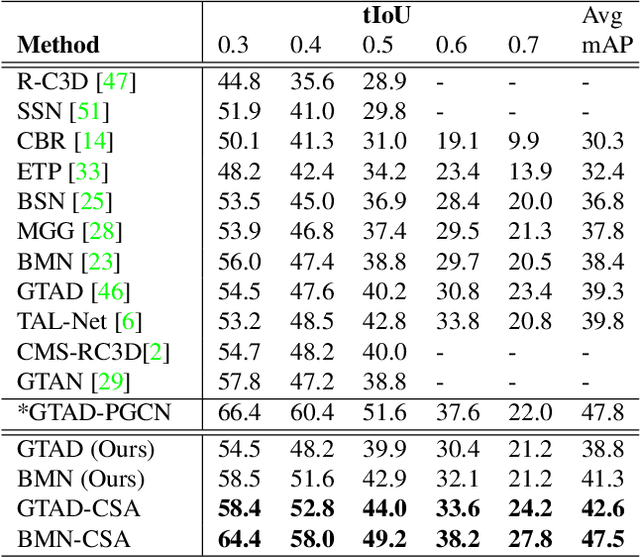
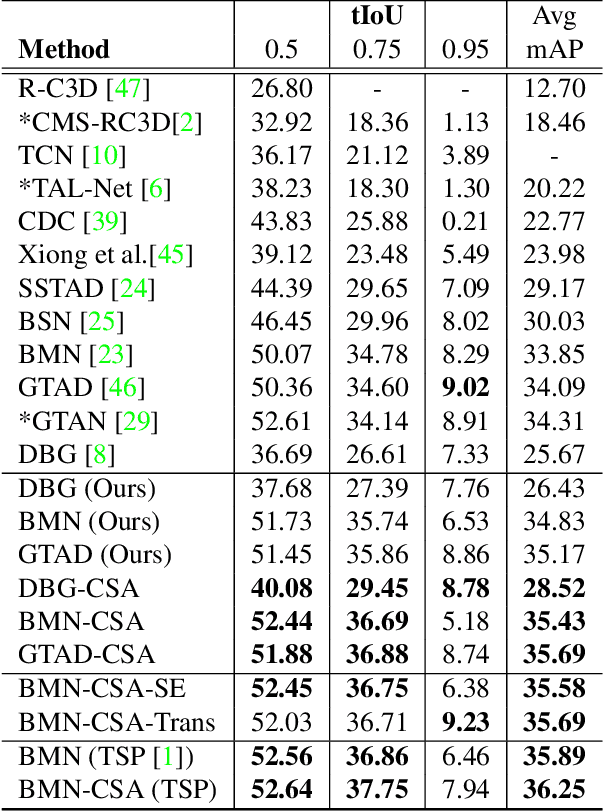
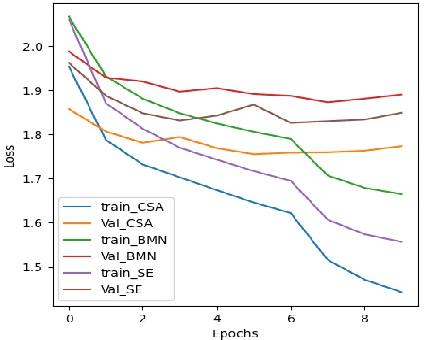
Action localization networks are often structured as a feature encoder sub-network and a localization sub-network, where the feature encoder learns to transform an input video to features that are useful for the localization sub-network to generate reliable action proposals. While some of the encoded features may be more useful for generating action proposals, prior action localization approaches do not include any attention mechanism that enables the localization sub-network to attend more to the more important features. In this paper, we propose a novel attention mechanism, the Class Semantics-based Attention (CSA), that learns from the temporal distribution of semantics of action classes present in an input video to find the importance scores of the encoded features, which are used to provide attention to the more useful encoded features. We demonstrate on two popular action detection datasets that incorporating our novel attention mechanism provides considerable performance gains on competitive action detection models (e.g., around 6.2% improvement over BMN action detection baseline to obtain 47.5% mAP on the THUMOS-14 dataset), and a new state-of-the-art of 36.25% mAP on the ActivityNet v1.3 dataset. Further, the CSA localization model family which includes BMN-CSA, was part of the second-placed submission at the 2021 ActivityNet action localization challenge. Our attention mechanism outperforms prior self-attention modules such as the squeeze-and-excitation in action detection task. We also observe that our attention mechanism is complementary to such self-attention modules in that performance improvements are seen when both are used together.
Fine-Pruning: Joint Fine-Tuning and Compression of a Convolutional Network with Bayesian Optimization
Jul 28, 2017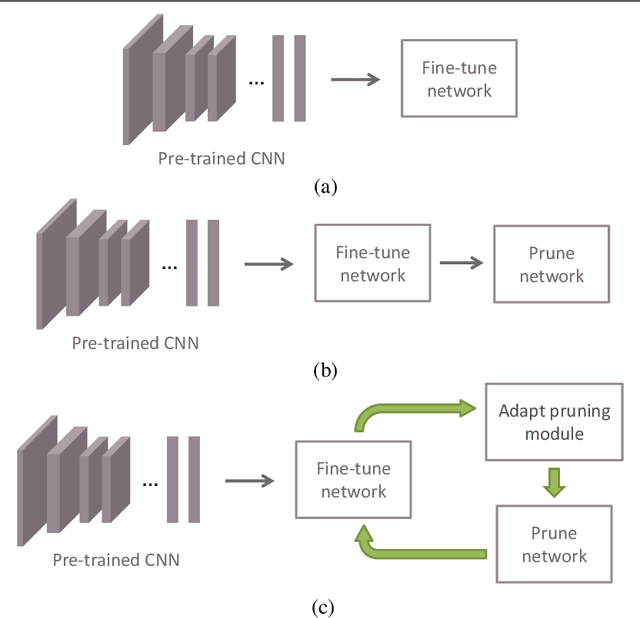
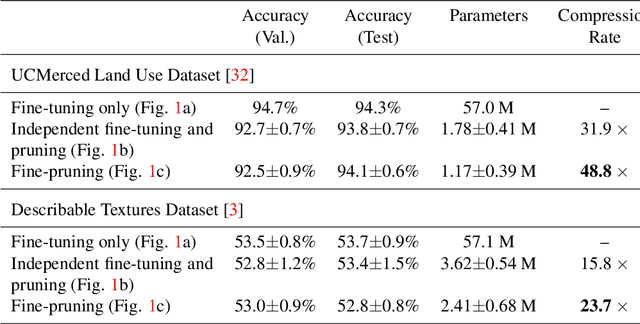

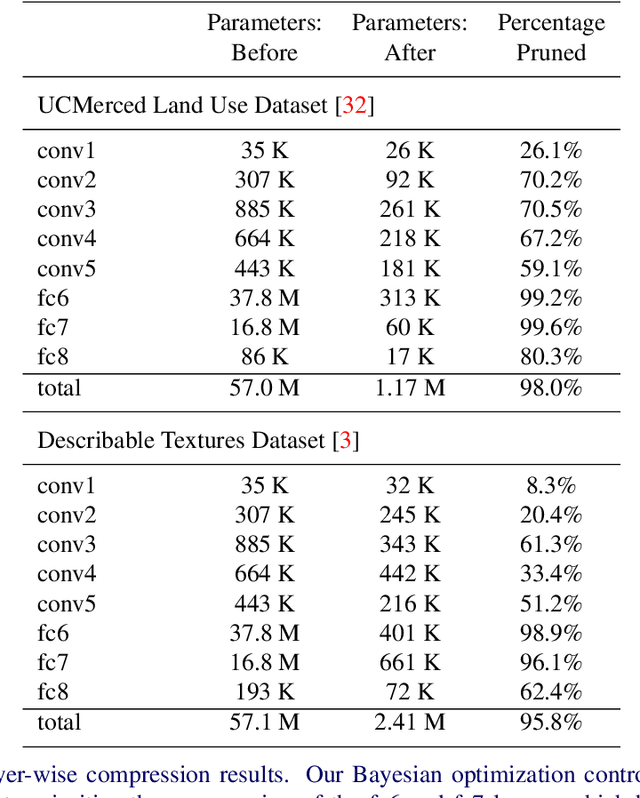
When approaching a novel visual recognition problem in a specialized image domain, a common strategy is to start with a pre-trained deep neural network and fine-tune it to the specialized domain. If the target domain covers a smaller visual space than the source domain used for pre-training (e.g. ImageNet), the fine-tuned network is likely to be over-parameterized. However, applying network pruning as a post-processing step to reduce the memory requirements has drawbacks: fine-tuning and pruning are performed independently; pruning parameters are set once and cannot adapt over time; and the highly parameterized nature of state-of-the-art pruning methods make it prohibitive to manually search the pruning parameter space for deep networks, leading to coarse approximations. We propose a principled method for jointly fine-tuning and compressing a pre-trained convolutional network that overcomes these limitations. Experiments on two specialized image domains (remote sensing images and describable textures) demonstrate the validity of the proposed approach.
Hierarchical Deep Temporal Models for Group Activity Recognition
Jul 09, 2016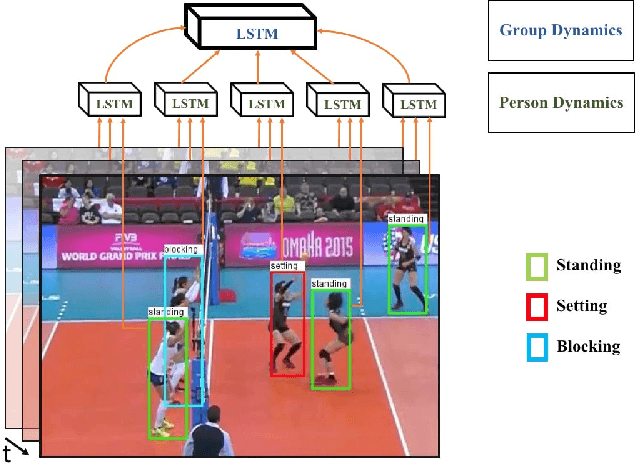

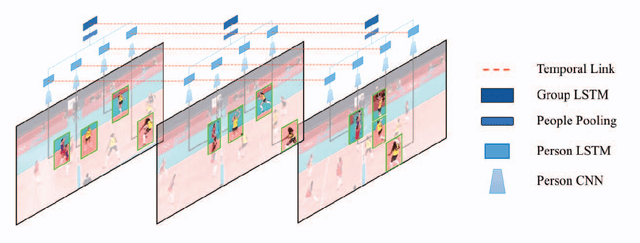
In this paper we present an approach for classifying the activity performed by a group of people in a video sequence. This problem of group activity recognition can be addressed by examining individual person actions and their relations. Temporal dynamics exist both at the level of individual person actions as well as at the level of group activity. Given a video sequence as input, methods can be developed to capture these dynamics at both person-level and group-level detail. We build a deep model to capture these dynamics based on LSTM (long short-term memory) models. In order to model both person-level and group-level dynamics, we present a 2-stage deep temporal model for the group activity recognition problem. In our approach, one LSTM model is designed to represent action dynamics of individual people in a video sequence and another LSTM model is designed to aggregate person-level information for group activity recognition. We collected a new dataset consisting of volleyball videos labeled with individual and group activities in order to evaluate our method. Experimental results on this new Volleyball Dataset and the standard benchmark Collective Activity Dataset demonstrate the efficacy of the proposed models.
A Hierarchical Deep Temporal Model for Group Activity Recognition
Apr 05, 2016In group activity recognition, the temporal dynamics of the whole activity can be inferred based on the dynamics of the individual people representing the activity. We build a deep model to capture these dynamics based on LSTM (long-short term memory) models. To make use of these ob- servations, we present a 2-stage deep temporal model for the group activity recognition problem. In our model, a LSTM model is designed to represent action dynamics of in- dividual people in a sequence and another LSTM model is designed to aggregate human-level information for whole activity understanding. We evaluate our model over two datasets: the collective activity dataset and a new volley- ball dataset. Experimental results demonstrate that our proposed model improves group activity recognition perfor- mance with compared to baseline methods.
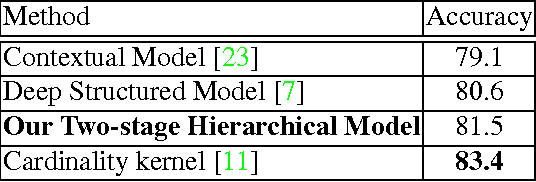
Deep Structured Models For Group Activity Recognition
Jun 12, 2015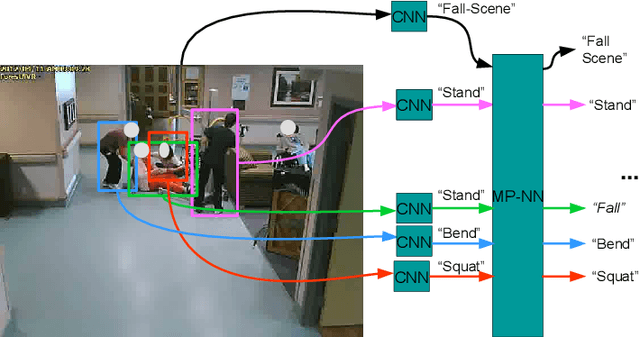

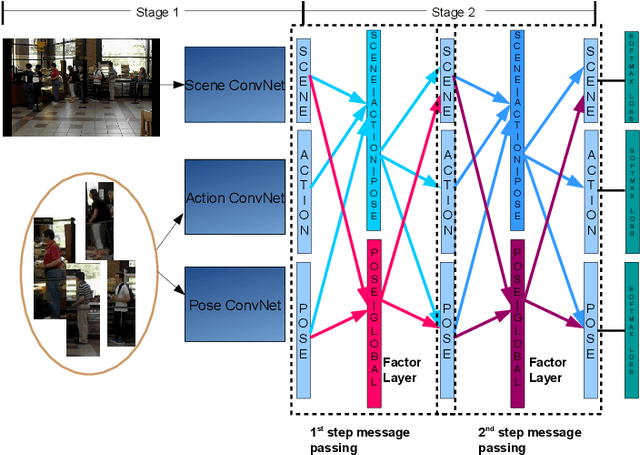

This paper presents a deep neural-network-based hierarchical graphical model for individual and group activity recognition in surveillance scenes. Deep networks are used to recognize the actions of individual people in a scene. Next, a neural-network-based hierarchical graphical model refines the predicted labels for each class by considering dependencies between the classes. This refinement step mimics a message-passing step similar to inference in a probabilistic graphical model. We show that this approach can be effective in group activity recognition, with the deep graphical model improving recognition rates over baseline methods.