 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADiff4TPP: Asynchronous Diffusion Models for Temporal Point Processes
Apr 29, 2025


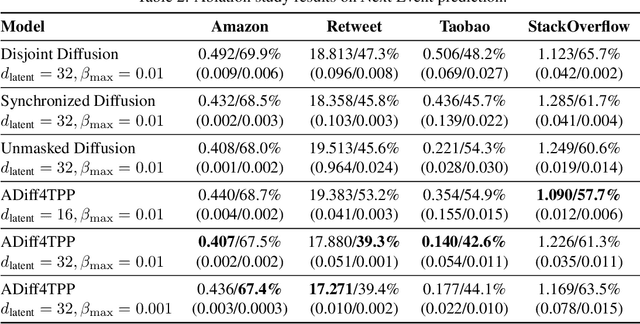
This work introduces a novel approach to modeling temporal point processes using diffusion models with an asynchronous noise schedule. At each step of the diffusion process, the noise schedule injects noise of varying scales into different parts of the data. With a careful design of the noise schedules, earlier events are generated faster than later ones, thus providing stronger conditioning for forecasting the more distant future. We derive an objective to effectively train these models for a general family of noise schedules based on conditional flow matching. Our method models the joint distribution of the latent representations of events in a sequence and achieves state-of-the-art results in predicting both the next inter-event time and event type on benchmark datasets. Additionally, it flexibly accommodates varying lengths of observation and prediction windows in different forecasting settings by adjusting the starting and ending points of the generation process. Finally, our method shows superior performance in long-horizon prediction tasks, outperforming existing baseline methods.
Radar: Fast Long-Context Decoding for Any Transformer
Mar 13, 2025Transformer models have demonstrated exceptional performance across a wide range of applications. Though forming the foundation of Transformer models, the dot-product attention does not scale well to long-context data since its time requirement grows quadratically with context length. In this work, we propose Radar, a training-free approach that accelerates inference by dynamically searching for the most important context tokens. For any pre-trained Transformer, Radar can reduce the decoding time complexity without training or heuristically evicting tokens. Moreover, we provide theoretical justification for our approach, demonstrating that Radar can reliably identify the most important tokens with high probability. We conduct extensive comparisons with the previous methods on a wide range of tasks. The results demonstrate that Radar achieves the state-of-the-art performance across different architectures with reduced time complexity, offering a practical solution for efficient long-context processing of Transformers.
Were RNNs All We Needed?
Oct 02, 2024



The scalability limitations of Transformers regarding sequence length have renewed interest in recurrent sequence models that are parallelizable during training. As a result, many novel recurrent architectures, such as S4, Mamba, and Aaren, have been proposed that achieve comparable performance. In this work, we revisit traditional recurrent neural networks (RNNs) from over a decade ago: LSTMs (1997) and GRUs (2014). While these models were slow due to requiring to backpropagate through time (BPTT), we show that by removing their hidden state dependencies from their input, forget, and update gates, LSTMs and GRUs no longer need to BPTT and can be efficiently trained in parallel. Building on this, we introduce minimal versions (minLSTMs and minGRUs) that (1) use significantly fewer parameters than their traditional counterparts and (2) are fully parallelizable during training (175x faster for a sequence of length 512). Lastly, we show that these stripped-down versions of decade-old RNNs match the empirical performance of recent sequence models.
Forget Sharpness: Perturbed Forgetting of Model Biases Within SAM Dynamics
Jun 10, 2024Despite attaining high empirical generalization, the sharpness of models trained with sharpness-aware minimization (SAM) do not always correlate with generalization error. Instead of viewing SAM as minimizing sharpness to improve generalization, our paper considers a new perspective based on SAM's training dynamics. We propose that perturbations in SAM perform perturbed forgetting, where they discard undesirable model biases to exhibit learning signals that generalize better. We relate our notion of forgetting to the information bottleneck principle, use it to explain observations like the better generalization of smaller perturbation batches, and show that perturbed forgetting can exhibit a stronger correlation with generalization than flatness. While standard SAM targets model biases exposed by the steepest ascent directions, we propose a new perturbation that targets biases exposed through the model's outputs. Our output bias forgetting perturbations outperform standard SAM, GSAM, and ASAM on ImageNet, robustness benchmarks, and transfer to CIFAR-{10,100}, while sometimes converging to sharper regions. Our results suggest that the benefits of SAM can be explained by alternative mechanistic principles that do not require flatness of the loss surface.
Attention as an RNN
May 22, 2024



The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its \textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's \textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce \textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
Pretext Training Algorithms for Event Sequence Data
Feb 16, 2024



Pretext training followed by task-specific fine-tuning has been a successful approach in vision and language domains. This paper proposes a self-supervised pretext training framework tailored to event sequence data. We introduce a novel alignment verification task that is specialized to event sequences, building on good practices in masked reconstruction and contrastive learning. Our pretext tasks unlock foundational representations that are generalizable across different down-stream tasks, including next-event prediction for temporal point process models, event sequence classification, and missing event interpolation. Experiments on popular public benchmarks demonstrate the potential of the proposed method across different tasks and data domains.
AdaFlood: Adaptive Flood Regularization
Nov 06, 2023Although neural networks are conventionally optimized towards zero training loss, it has been recently learned that targeting a non-zero training loss threshold, referred to as a flood level, often enables better test time generalization. Current approaches, however, apply the same constant flood level to all training samples, which inherently assumes all the samples have the same difficulty. We present AdaFlood, a novel flood regularization method that adapts the flood level of each training sample according to the difficulty of the sample. Intuitively, since training samples are not equal in difficulty, the target training loss should be conditioned on the instance. Experiments on datasets covering four diverse input modalities - text, images, asynchronous event sequences, and tabular - demonstrate the versatility of AdaFlood across data domains and noise levels.
Prompting-based Efficient Temporal Domain Generalization
Oct 03, 2023
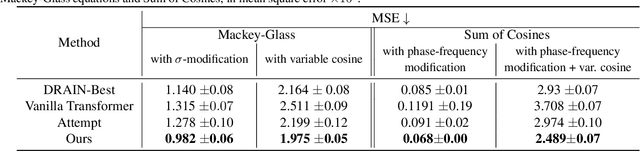
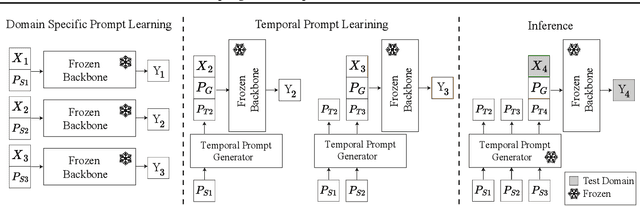
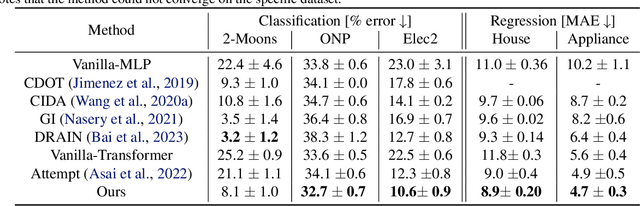
Machine learning traditionally assumes that training and testing data are distributed independently and identically. However, in many real-world settings, the data distribution can shift over time, leading to poor generalization of trained models in future time periods. Our paper presents a novel prompting-based approach to temporal domain generalization that is parameter-efficient, time-efficient, and does not require access to the target domain data (i.e., unseen future time periods) during training. Our method adapts a target pre-trained model to temporal drift by learning global prompts, domain-specific prompts, and drift-aware prompts that capture underlying temporal dynamics. It is compatible across diverse tasks, such as classification, regression, and time series forecasting, and sets a new state-of-the-art benchmark in temporal domain generalization. The code repository will be publicly shared.
Tree Cross Attention
Sep 29, 2023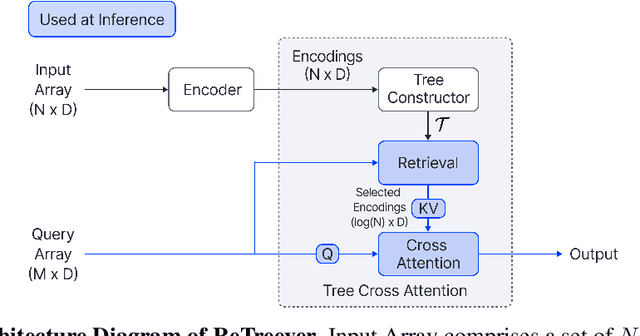
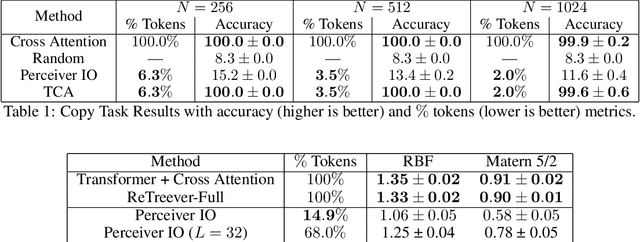
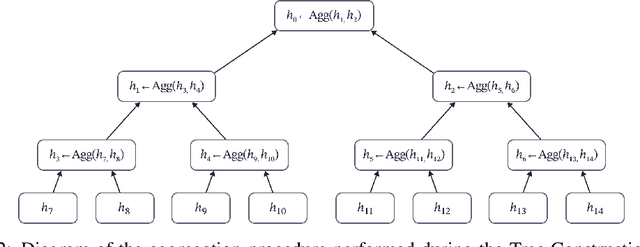

Cross Attention is a popular method for retrieving information from a set of context tokens for making predictions. At inference time, for each prediction, Cross Attention scans the full set of $\mathcal{O}(N)$ tokens. In practice, however, often only a small subset of tokens are required for good performance. Methods such as Perceiver IO are cheap at inference as they distill the information to a smaller-sized set of latent tokens $L < N$ on which cross attention is then applied, resulting in only $\mathcal{O}(L)$ complexity. However, in practice, as the number of input tokens and the amount of information to distill increases, the number of latent tokens needed also increases significantly. In this work, we propose Tree Cross Attention (TCA) - a module based on Cross Attention that only retrieves information from a logarithmic $\mathcal{O}(\log(N))$ number of tokens for performing inference. TCA organizes the data in a tree structure and performs a tree search at inference time to retrieve the relevant tokens for prediction. Leveraging TCA, we introduce ReTreever, a flexible architecture for token-efficient inference. We show empirically that Tree Cross Attention (TCA) performs comparable to Cross Attention across various classification and uncertainty regression tasks while being significantly more token-efficient. Furthermore, we compare ReTreever against Perceiver IO, showing significant gains while using the same number of tokens for inference.
Constant Memory Attention Block
Jun 21, 2023
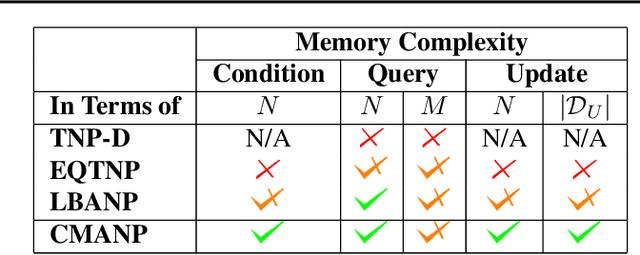
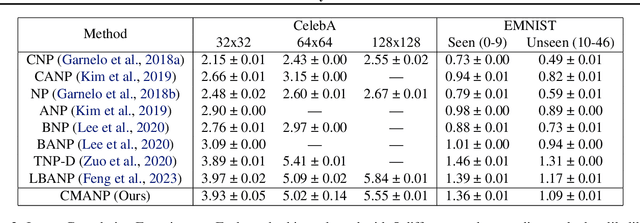

Modern foundation model architectures rely on attention mechanisms to effectively capture context. However, these methods require linear or quadratic memory in terms of the number of inputs/datapoints, limiting their applicability in low-compute domains. In this work, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that computes its output in constant memory and performs updates in constant computation. Highlighting CMABs efficacy, we introduce methods for Neural Processes and Temporal Point Processes. Empirically, we show our proposed methods achieve results competitive with state-of-the-art while being significantly more memory efficient.