 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Herding: One Active Learning Method for All Label Budgets
Dec 30, 2024Most active learning research has focused on methods which perform well when many labels are available, but can be dramatically worse than random selection when label budgets are small. Other methods have focused on the low-budget regime, but do poorly as label budgets increase. As the line between "low" and "high" budgets varies by problem, this is a serious issue in practice. We propose uncertainty coverage, an objective which generalizes a variety of low- and high-budget objectives, as well as natural, hyperparameter-light methods to smoothly interpolate between low- and high-budget regimes. We call greedy optimization of the estimate Uncertainty Herding; this simple method is computationally fast, and we prove that it nearly optimizes the distribution-level coverage. In experimental validation across a variety of active learning tasks, our proposal matches or beats state-of-the-art performance in essentially all cases; it is the only method of which we are aware that reliably works well in both low- and high-budget settings.
Forget Sharpness: Perturbed Forgetting of Model Biases Within SAM Dynamics
Jun 10, 2024Despite attaining high empirical generalization, the sharpness of models trained with sharpness-aware minimization (SAM) do not always correlate with generalization error. Instead of viewing SAM as minimizing sharpness to improve generalization, our paper considers a new perspective based on SAM's training dynamics. We propose that perturbations in SAM perform perturbed forgetting, where they discard undesirable model biases to exhibit learning signals that generalize better. We relate our notion of forgetting to the information bottleneck principle, use it to explain observations like the better generalization of smaller perturbation batches, and show that perturbed forgetting can exhibit a stronger correlation with generalization than flatness. While standard SAM targets model biases exposed by the steepest ascent directions, we propose a new perturbation that targets biases exposed through the model's outputs. Our output bias forgetting perturbations outperform standard SAM, GSAM, and ASAM on ImageNet, robustness benchmarks, and transfer to CIFAR-{10,100}, while sometimes converging to sharper regions. Our results suggest that the benefits of SAM can be explained by alternative mechanistic principles that do not require flatness of the loss surface.
AdaFlood: Adaptive Flood Regularization
Nov 06, 2023Although neural networks are conventionally optimized towards zero training loss, it has been recently learned that targeting a non-zero training loss threshold, referred to as a flood level, often enables better test time generalization. Current approaches, however, apply the same constant flood level to all training samples, which inherently assumes all the samples have the same difficulty. We present AdaFlood, a novel flood regularization method that adapts the flood level of each training sample according to the difficulty of the sample. Intuitively, since training samples are not equal in difficulty, the target training loss should be conditioned on the instance. Experiments on datasets covering four diverse input modalities - text, images, asynchronous event sequences, and tabular - demonstrate the versatility of AdaFlood across data domains and noise levels.
Meta Temporal Point Processes
Jan 27, 2023



A temporal point process (TPP) is a stochastic process where its realization is a sequence of discrete events in time. Recent work in TPPs model the process using a neural network in a supervised learning framework, where a training set is a collection of all the sequences. In this work, we propose to train TPPs in a meta learning framework, where each sequence is treated as a different task, via a novel framing of TPPs as neural processes (NPs). We introduce context sets to model TPPs as an instantiation of NPs. Motivated by attentive NP, we also introduce local history matching to help learn more informative features. We demonstrate the potential of the proposed method on popular public benchmark datasets and tasks, and compare with state-of-the-art TPP methods.
Heterogeneous Multi-task Learning with Expert Diversity
Jun 20, 2021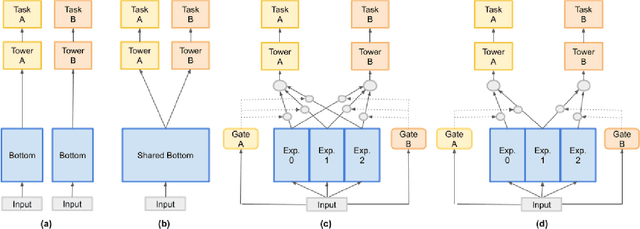
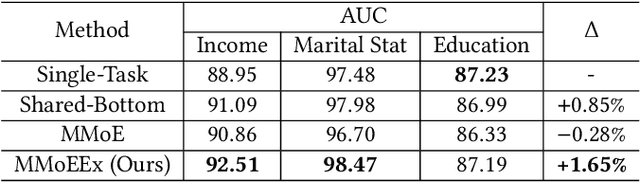
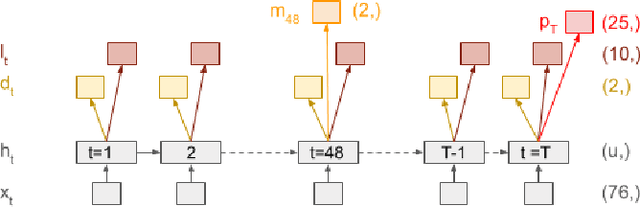
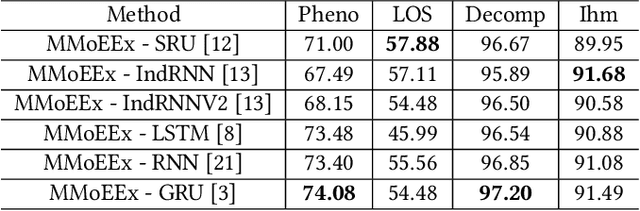
Predicting multiple heterogeneous biological and medical targets is a challenge for traditional deep learning models. In contrast to single-task learning, in which a separate model is trained for each target, multi-task learning (MTL) optimizes a single model to predict multiple related targets simultaneously. To address this challenge, we propose the Multi-gate Mixture-of-Experts with Exclusivity (MMoEEx). Our work aims to tackle the heterogeneous MTL setting, in which the same model optimizes multiple tasks with different characteristics. Such a scenario can overwhelm current MTL approaches due to the challenges in balancing shared and task-specific representations and the need to optimize tasks with competing optimization paths. Our method makes two key contributions: first, we introduce an approach to induce more diversity among experts, thus creating representations more suitable for highly imbalanced and heterogenous MTL learning; second, we adopt a two-step optimization [6, 11] approach to balancing the tasks at the gradient level. We validate our method on three MTL benchmark datasets, including Medical Information Mart for Intensive Care (MIMIC-III) and PubChem BioAssay (PCBA).
Beyond Single Stage Encoder-Decoder Networks: Deep Decoders for Semantic Image Segmentation
Jul 19, 2020



Single encoder-decoder methodologies for semantic segmentation are reaching their peak in terms of segmentation quality and efficiency per number of layers. To address these limitations, we propose a new architecture based on a decoder which uses a set of shallow networks for capturing more information content. The new decoder has a new topology of skip connections, namely backward and stacked residual connections. In order to further improve the architecture we introduce a weight function which aims to re-balance classes to increase the attention of the networks to under-represented objects. We carried out an extensive set of experiments that yielded state-of-the-art results for the CamVid, Gatech and Freiburg Forest datasets. Moreover, to further prove the effectiveness of our decoder, we conducted a set of experiments studying the impact of our decoder to state-of-the-art segmentation techniques. Additionally, we present a set of experiments augmenting semantic segmentation with optical flow information, showing that motion clues can boost pure image based semantic segmentation approaches.
Topometric Localization with Deep Learning
Jun 27, 2017
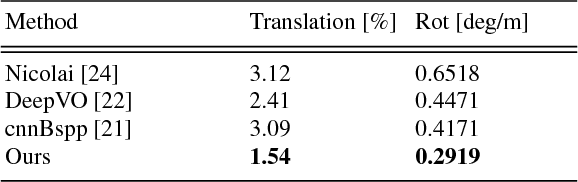
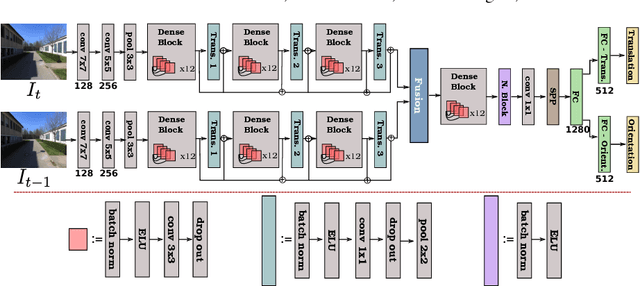

Compared to LiDAR-based localization methods, which provide high accuracy but rely on expensive sensors, visual localization approaches only require a camera and thus are more cost-effective while their accuracy and reliability typically is inferior to LiDAR-based methods. In this work, we propose a vision-based localization approach that learns from LiDAR-based localization methods by using their output as training data, thus combining a cheap, passive sensor with an accuracy that is on-par with LiDAR-based localization. The approach consists of two deep networks trained on visual odometry and topological localization, respectively, and a successive optimization to combine the predictions of these two networks. We evaluate the approach on a new challenging pedestrian-based dataset captured over the course of six months in varying weather conditions with a high degree of noise. The experiments demonstrate that the localization errors are up to 10 times smaller than with traditional vision-based localization methods.
Deep Semantic Classification for 3D LiDAR Data
Jun 26, 2017
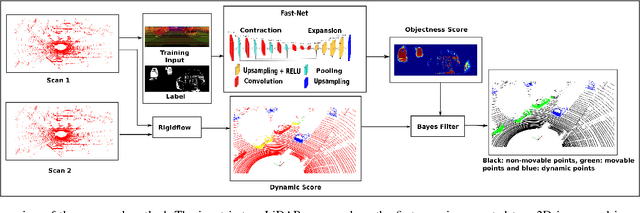
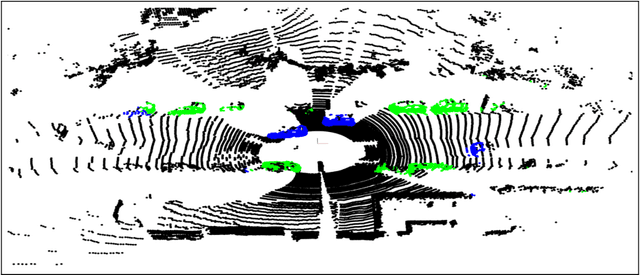
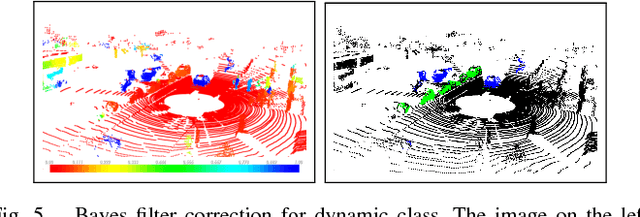
Robots are expected to operate autonomously in dynamic environments. Understanding the underlying dynamic characteristics of objects is a key enabler for achieving this goal. In this paper, we propose a method for pointwise semantic classification of 3D LiDAR data into three classes: non-movable, movable and dynamic. We concentrate on understanding these specific semantics because they characterize important information required for an autonomous system. Non-movable points in the scene belong to unchanging segments of the environment, whereas the remaining classes corresponds to the changing parts of the scene. The difference between the movable and dynamic class is their motion state. The dynamic points can be perceived as moving, whereas movable objects can move, but are perceived as static. To learn the distinction between movable and non-movable points in the environment, we introduce an approach based on deep neural network and for detecting the dynamic points, we estimate pointwise motion. We propose a Bayes filter framework for combining the learned semantic cues with the motion cues to infer the required semantic classification. In extensive experiments, we compare our approach with other methods on a standard benchmark dataset and report competitive results in comparison to the existing state-of-the-art. Furthermore, we show an improvement in the classification of points by combining the semantic cues retrieved from the neural network with the motion cues.
Chained Multi-stream Networks Exploiting Pose, Motion, and Appearance for Action Classification and Detection
May 26, 2017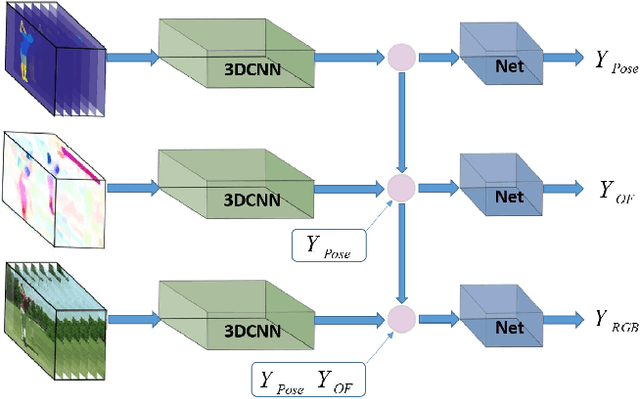
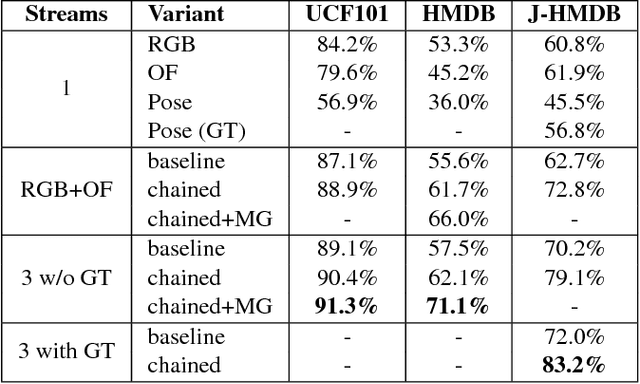

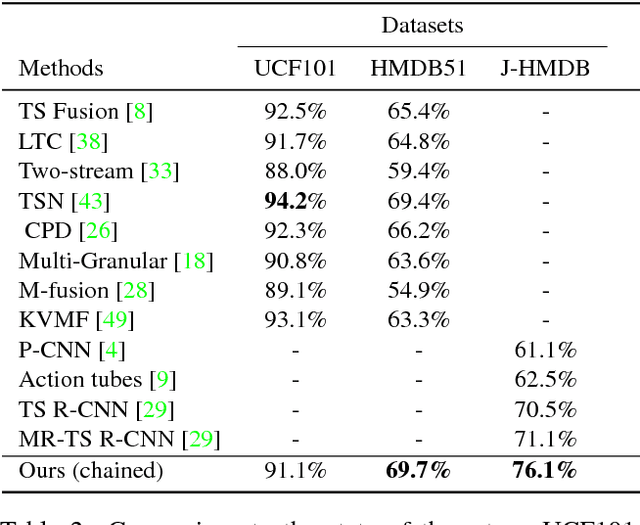
General human action recognition requires understanding of various visual cues. In this paper, we propose a network architecture that computes and integrates the most important visual cues for action recognition: pose, motion, and the raw images. For the integration, we introduce a Markov chain model which adds cues successively. The resulting approach is efficient and applicable to action classification as well as to spatial and temporal action localization. The two contributions clearly improve the performance over respective baselines. The overall approach achieves state-of-the-art action classification performance on HMDB51, J-HMDB and NTU RGB+D datasets. Moreover, it yields state-of-the-art spatio-temporal action localization results on UCF101 and J-HMDB.