 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossCLR: Cross-modal Contrastive Learning For Multi-modal Video Representations
Sep 30, 2021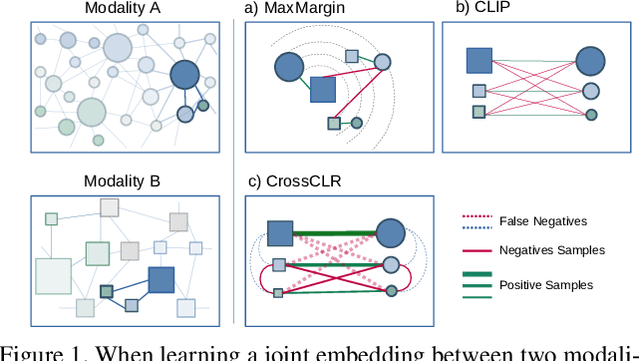

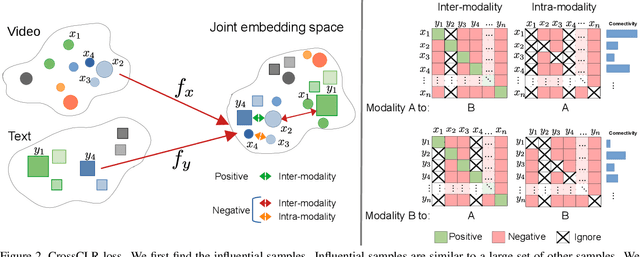

Contrastive learning allows us to flexibly define powerful losses by contrasting positive pairs from sets of negative samples. Recently, the principle has also been used to learn cross-modal embeddings for video and text, yet without exploiting its full potential. In particular, previous losses do not take the intra-modality similarities into account, which leads to inefficient embeddings, as the same content is mapped to multiple points in the embedding space. With CrossCLR, we present a contrastive loss that fixes this issue. Moreover, we define sets of highly related samples in terms of their input embeddings and exclude them from the negative samples to avoid issues with false negatives. We show that these principles consistently improve the quality of the learned embeddings. The joint embeddings learned with CrossCLR extend the state of the art in video-text retrieval on Youcook2 and LSMDC datasets and in video captioning on Youcook2 dataset by a large margin. We also demonstrate the generality of the concept by learning improved joint embeddings for other pairs of modalities.
A Comprehensive Study of Deep Video Action Recognition
Dec 11, 2020
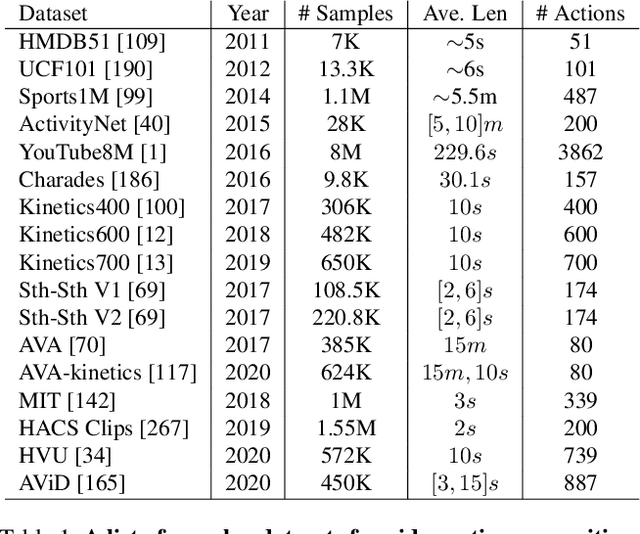
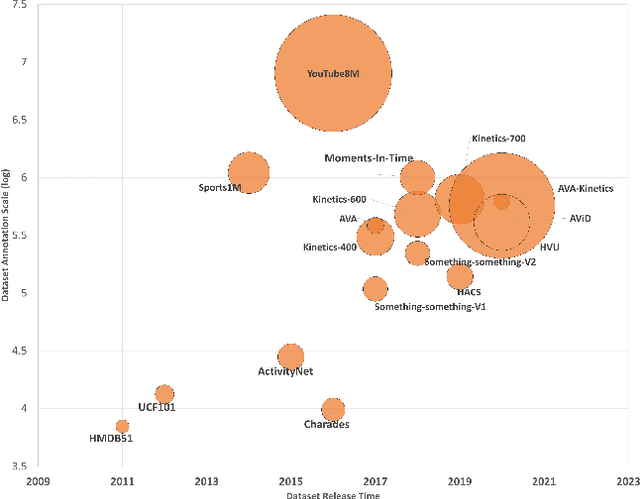
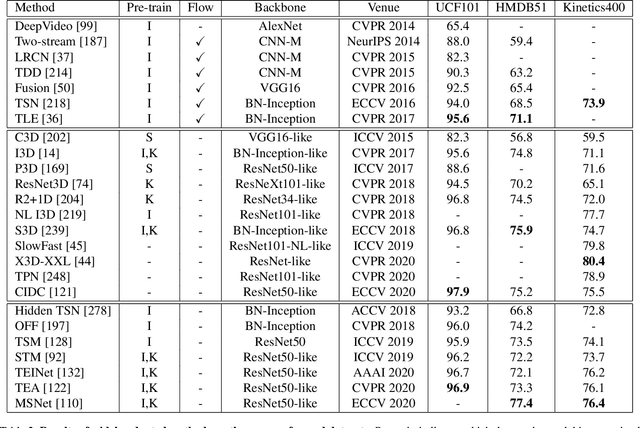
Video action recognition is one of the representative tasks for video understanding. Over the last decade, we have witnessed great advancements in video action recognition thanks to the emergence of deep learning. But we also encountered new challenges, including modeling long-range temporal information in videos, high computation costs, and incomparable results due to datasets and evaluation protocol variances. In this paper, we provide a comprehensive survey of over 200 existing papers on deep learning for video action recognition. We first introduce the 17 video action recognition datasets that influenced the design of models. Then we present video action recognition models in chronological order: starting with early attempts at adapting deep learning, then to the two-stream networks, followed by the adoption of 3D convolutional kernels, and finally to the recent compute-efficient models. In addition, we benchmark popular methods on several representative datasets and release code for reproducibility. In the end, we discuss open problems and shed light on opportunities for video action recognition to facilitate new research ideas.
COOT: Cooperative Hierarchical Transformer for Video-Text Representation Learning
Nov 01, 2020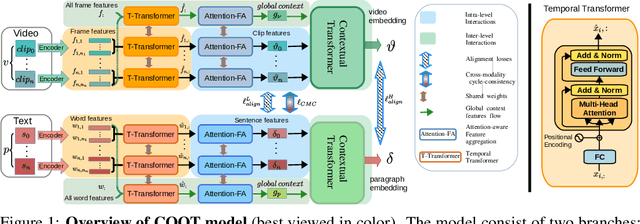

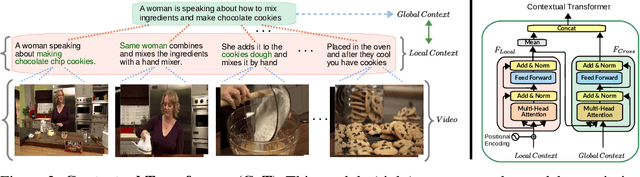
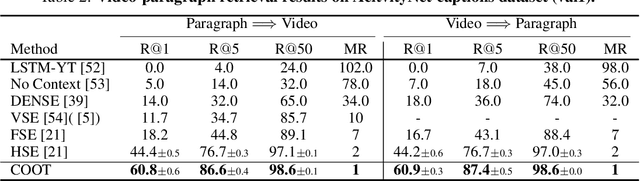
Many real-world video-text tasks involve different levels of granularity, such as frames and words, clip and sentences or videos and paragraphs, each with distinct semantics. In this paper, we propose a Cooperative hierarchical Transformer (COOT) to leverage this hierarchy information and model the interactions between different levels of granularity and different modalities. The method consists of three major components: an attention-aware feature aggregation layer, which leverages the local temporal context (intra-level, e.g., within a clip), a contextual transformer to learn the interactions between low-level and high-level semantics (inter-level, e.g. clip-video, sentence-paragraph), and a cross-modal cycle-consistency loss to connect video and text. The resulting method compares favorably to the state of the art on several benchmarks while having few parameters. All code is available open-source at https://github.com/gingsi/coot-videotext
Multi-Variate Temporal GAN for Large Scale Video Generation
Apr 04, 2020


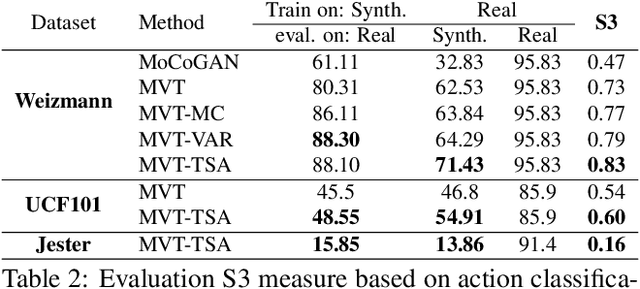
In this paper, we present a network architecture for video generation that models spatio-temporal consistency without resorting to costly 3D architectures. In particular, we elaborate on the components of noise generation, sequence generation, and frame generation. The architecture facilitates the information exchange between neighboring time points, which improves the temporal consistency of the generated frames both at the structural level and the detailed level. The approach achieves state-of-the-art quantitative performance, as measured by the inception score, on the UCF-101 dataset, which is in line with a qualitative inspection of the generated videos. We also introduce a new quantitative measure that uses downstream tasks for evaluation.
Learning Representations for Predicting Future Activities
May 09, 2019
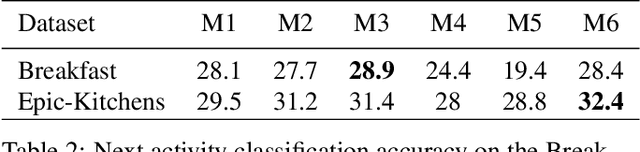
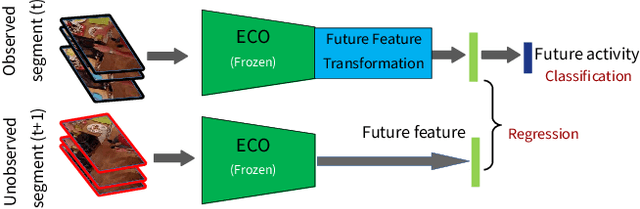

Foreseeing the future is one of the key factors of intelligence. It involves understanding of the past and current environment as well as decent experience of its possible dynamics. In this work, we address future prediction at the abstract level of activities. We propose a network module for learning embeddings of the environment's dynamics in a self-supervised way. To take the ambiguities and high variances in the future activities into account, we use a multi-hypotheses scheme that can represent multiple futures. We demonstrate the approach by classifying future activities on the Epic-Kitchens and Breakfast datasets. Moreover, we generate captions that describe the future activities
ECO: Efficient Convolutional Network for Online Video Understanding
May 07, 2018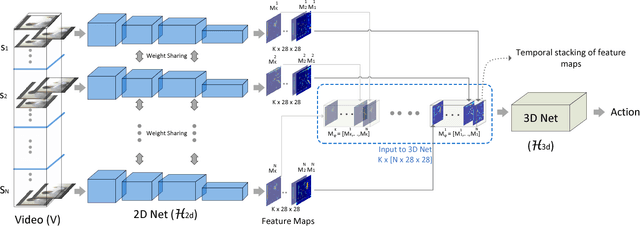
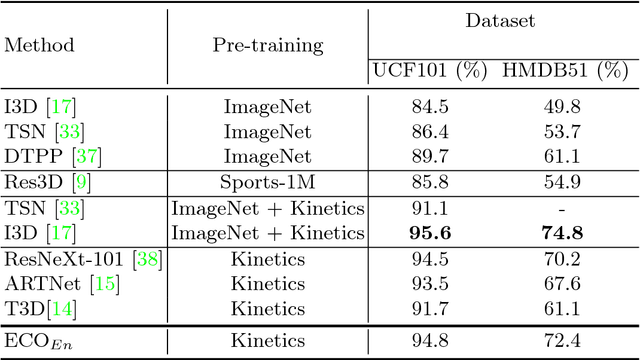
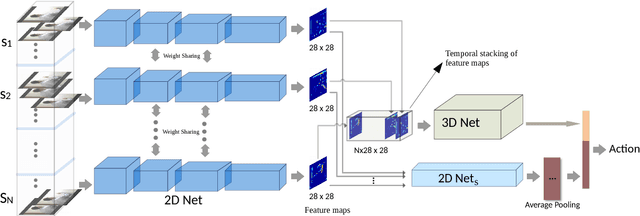

The state of the art in video understanding suffers from two problems: (1) The major part of reasoning is performed locally in the video, therefore, it misses important relationships within actions that span several seconds. (2) While there are local methods with fast per-frame processing, the processing of the whole video is not efficient and hampers fast video retrieval or online classification of long-term activities. In this paper, we introduce a network architecture that takes long-term content into account and enables fast per-video processing at the same time. The architecture is based on merging long-term content already in the network rather than in a post-hoc fusion. Together with a sampling strategy, which exploits that neighboring frames are largely redundant, this yields high-quality action classification and video captioning at up to 230 videos per second, where each video can consist of a few hundred frames. The approach achieves competitive performance across all datasets while being 10x to 80x faster than state-of-the-art methods.
Orientation-boosted Voxel Nets for 3D Object Recognition
Oct 19, 2017
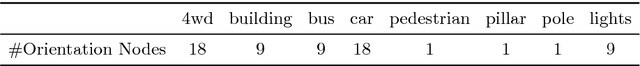
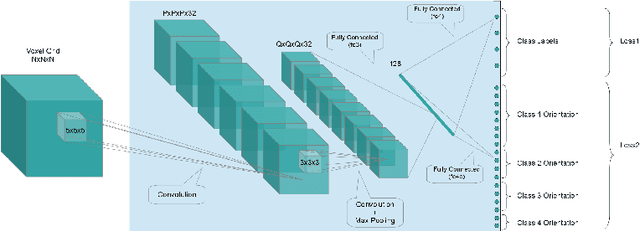

Recent work has shown good recognition results in 3D object recognition using 3D convolutional networks. In this paper, we show that the object orientation plays an important role in 3D recognition. More specifically, we argue that objects induce different features in the network under rotation. Thus, we approach the category-level classification task as a multi-task problem, in which the network is trained to predict the pose of the object in addition to the class label as a parallel task. We show that this yields significant improvements in the classification results. We test our suggested architecture on several datasets representing various 3D data sources: LiDAR data, CAD models, and RGB-D images. We report state-of-the-art results on classification as well as significant improvements in precision and speed over the baseline on 3D detection.
Chained Multi-stream Networks Exploiting Pose, Motion, and Appearance for Action Classification and Detection
May 26, 2017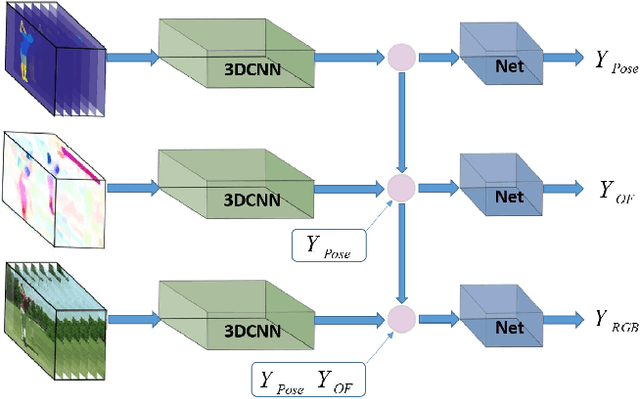
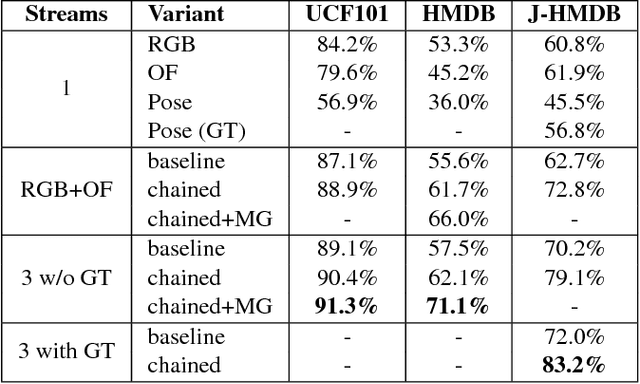

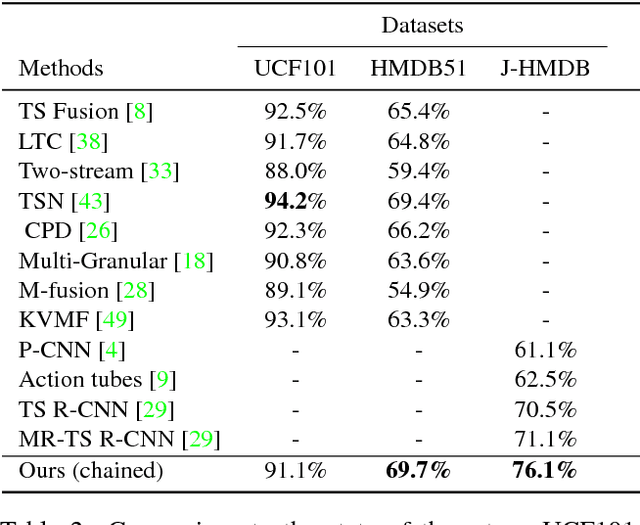
General human action recognition requires understanding of various visual cues. In this paper, we propose a network architecture that computes and integrates the most important visual cues for action recognition: pose, motion, and the raw images. For the integration, we introduce a Markov chain model which adds cues successively. The resulting approach is efficient and applicable to action classification as well as to spatial and temporal action localization. The two contributions clearly improve the performance over respective baselines. The overall approach achieves state-of-the-art action classification performance on HMDB51, J-HMDB and NTU RGB+D datasets. Moreover, it yields state-of-the-art spatio-temporal action localization results on UCF101 and J-HMDB.
Hybrid Learning of Optical Flow and Next Frame Prediction to Boost Optical Flow in the Wild
Apr 07, 2017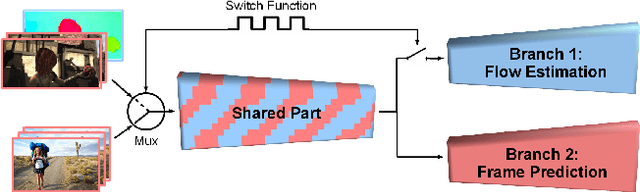



CNN-based optical flow estimation has attracted attention recently, mainly due to its impressively high frame rates. These networks perform well on synthetic datasets, but they are still far behind the classical methods in real-world videos. This is because there is no ground truth optical flow for training these networks on real data. In this paper, we boost CNN-based optical flow estimation in real scenes with the help of the freely available self-supervised task of next-frame prediction. To this end, we train the network in a hybrid way, providing it with a mixture of synthetic and real videos. With the help of a sample-variant multi-tasking architecture, the network is trained on different tasks depending on the availability of ground-truth. We also experiment with the prediction of "next-flow" instead of estimation of the current flow, which is intuitively closer to the task of next-frame prediction and yields favorable results. We demonstrate the improvement in optical flow estimation on the real-world KITTI benchmark. Additionally, we test the optical flow indirectly in an action classification scenario. As a side product of this work, we report significant improvements over state-of-the-art in the task of next-frame prediction.