 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfish Evolution: Making Discoveries in Extreme Label Noise with the Help of Overfitting Dynamics
Nov 26, 2024
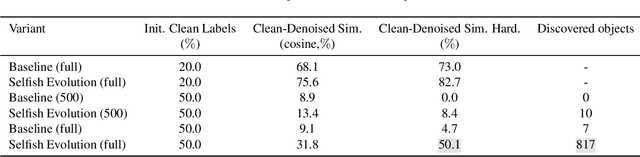
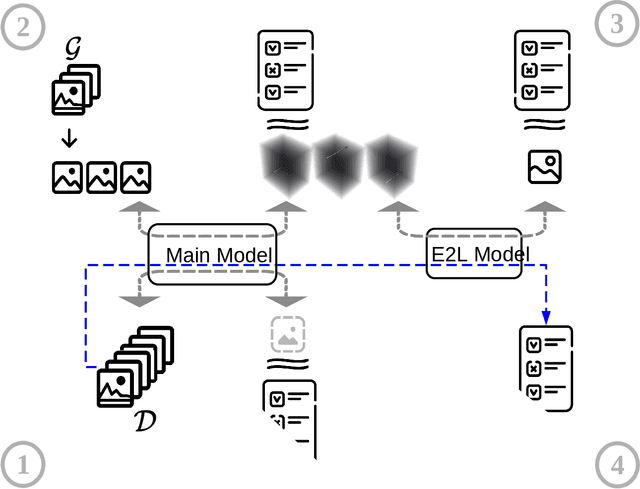
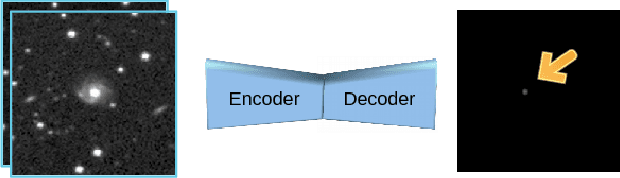
Motivated by the scarcity of proper labels in an astrophysical application, we have developed a novel technique, called Selfish Evolution, which allows for the detection and correction of corrupted labels in a weakly supervised fashion. Unlike methods based on early stopping, we let the model train on the noisy dataset. Only then do we intervene and allow the model to overfit to individual samples. The ``evolution'' of the model during this process reveals patterns with enough information about the noisiness of the label, as well as its correct version. We train a secondary network on these spatiotemporal ``evolution cubes'' to correct potentially corrupted labels. We incorporate the technique in a closed-loop fashion, allowing for automatic convergence towards a mostly clean dataset, without presumptions about the state of the network in which we intervene. We evaluate on the main task of the Supernova-hunting dataset but also demonstrate efficiency on the more standard MNIST dataset.
Orientation-boosted Voxel Nets for 3D Object Recognition
Oct 19, 2017
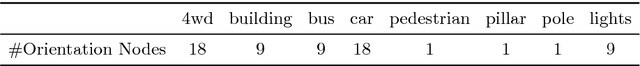
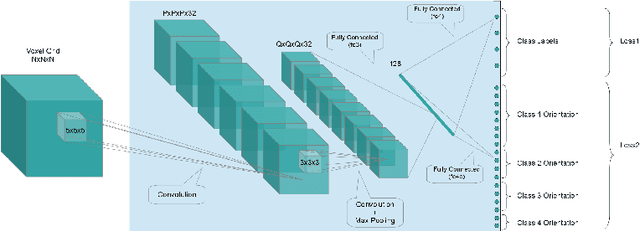

Recent work has shown good recognition results in 3D object recognition using 3D convolutional networks. In this paper, we show that the object orientation plays an important role in 3D recognition. More specifically, we argue that objects induce different features in the network under rotation. Thus, we approach the category-level classification task as a multi-task problem, in which the network is trained to predict the pose of the object in addition to the class label as a parallel task. We show that this yields significant improvements in the classification results. We test our suggested architecture on several datasets representing various 3D data sources: LiDAR data, CAD models, and RGB-D images. We report state-of-the-art results on classification as well as significant improvements in precision and speed over the baseline on 3D detection.
Effective Image Differencing with ConvNets for Real-time Transient Hunting
Oct 04, 2017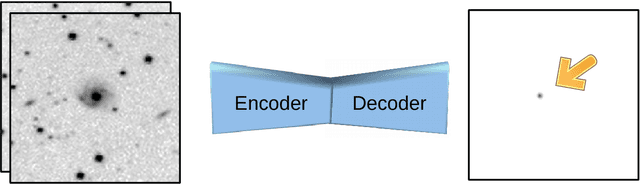

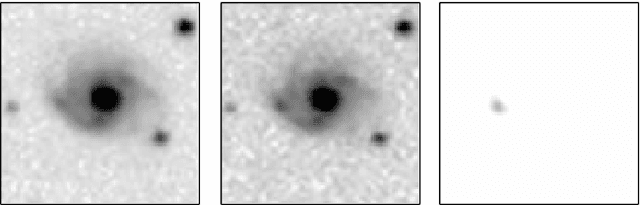
Large sky surveys are increasingly relying on image subtraction pipelines for real-time (and archival) transient detection. In this process one has to contend with varying PSF, small brightness variations in many sources, as well as artifacts resulting from saturated stars, and, in general, matching errors. Very often the differencing is done with a reference image that is deeper than individual images and the attendant difference in noise characteristics can also lead to artifacts. We present here a deep-learning approach to transient detection that encapsulates all the steps of a traditional image subtraction pipeline -- image registration, background subtraction, noise removal, psf matching, and subtraction -- into a single real-time convolutional network. Once trained the method works lighteningly fast, and given that it does multiple steps at one go, the advantages for multi-CCD, fast surveys like ZTF and LSST are obvious.
Chained Multi-stream Networks Exploiting Pose, Motion, and Appearance for Action Classification and Detection
May 26, 2017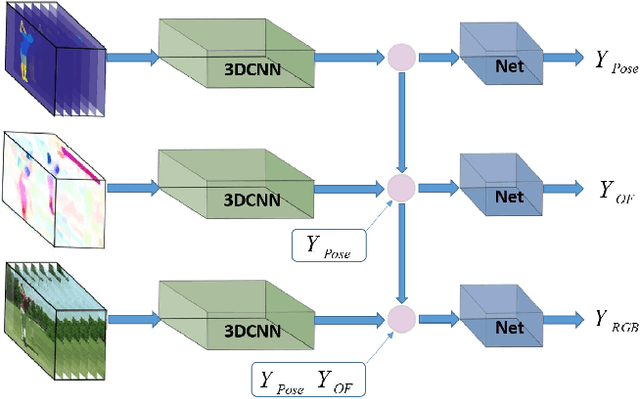
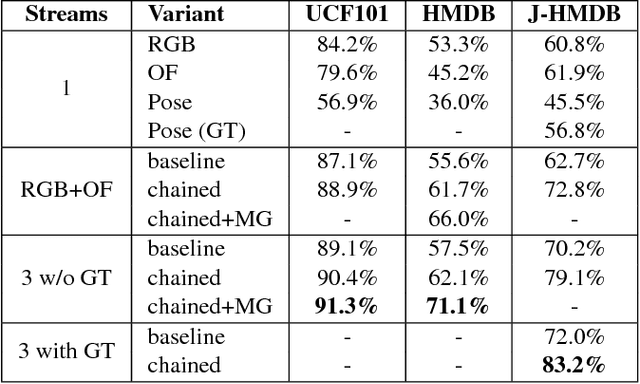

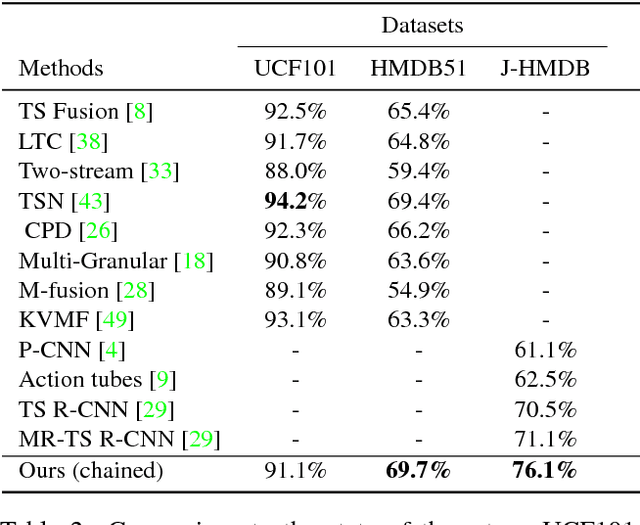
General human action recognition requires understanding of various visual cues. In this paper, we propose a network architecture that computes and integrates the most important visual cues for action recognition: pose, motion, and the raw images. For the integration, we introduce a Markov chain model which adds cues successively. The resulting approach is efficient and applicable to action classification as well as to spatial and temporal action localization. The two contributions clearly improve the performance over respective baselines. The overall approach achieves state-of-the-art action classification performance on HMDB51, J-HMDB and NTU RGB+D datasets. Moreover, it yields state-of-the-art spatio-temporal action localization results on UCF101 and J-HMDB.
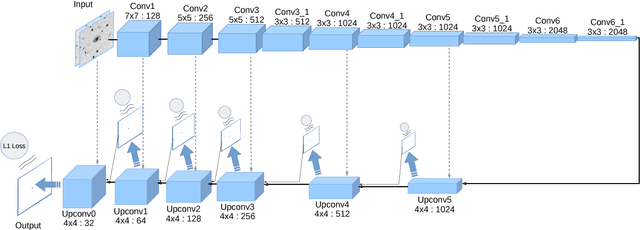
Hybrid Learning of Optical Flow and Next Frame Prediction to Boost Optical Flow in the Wild
Apr 07, 2017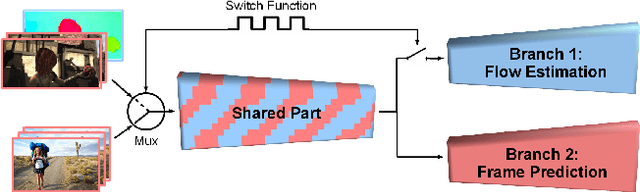



CNN-based optical flow estimation has attracted attention recently, mainly due to its impressively high frame rates. These networks perform well on synthetic datasets, but they are still far behind the classical methods in real-world videos. This is because there is no ground truth optical flow for training these networks on real data. In this paper, we boost CNN-based optical flow estimation in real scenes with the help of the freely available self-supervised task of next-frame prediction. To this end, we train the network in a hybrid way, providing it with a mixture of synthetic and real videos. With the help of a sample-variant multi-tasking architecture, the network is trained on different tasks depending on the availability of ground-truth. We also experiment with the prediction of "next-flow" instead of estimation of the current flow, which is intuitively closer to the task of next-frame prediction and yields favorable results. We demonstrate the improvement in optical flow estimation on the real-world KITTI benchmark. Additionally, we test the optical flow indirectly in an action classification scenario. As a side product of this work, we report significant improvements over state-of-the-art in the task of next-frame prediction.