 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Learning of Optical Flow and Next Frame Prediction to Boost Optical Flow in the Wild
Paper and Code
Apr 07, 2017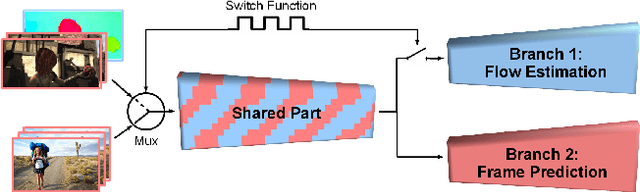



CNN-based optical flow estimation has attracted attention recently, mainly due to its impressively high frame rates. These networks perform well on synthetic datasets, but they are still far behind the classical methods in real-world videos. This is because there is no ground truth optical flow for training these networks on real data. In this paper, we boost CNN-based optical flow estimation in real scenes with the help of the freely available self-supervised task of next-frame prediction. To this end, we train the network in a hybrid way, providing it with a mixture of synthetic and real videos. With the help of a sample-variant multi-tasking architecture, the network is trained on different tasks depending on the availability of ground-truth. We also experiment with the prediction of "next-flow" instead of estimation of the current flow, which is intuitively closer to the task of next-frame prediction and yields favorable results. We demonstrate the improvement in optical flow estimation on the real-world KITTI benchmark. Additionally, we test the optical flow indirectly in an action classification scenario. As a side product of this work, we report significant improvements over state-of-the-art in the task of next-frame prediction.