 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Basics: Revisiting ASR in the Age of Voice Agents
Mar 26, 2026Automatic speech recognition (ASR) systems have achieved near-human accuracy on curated benchmarks, yet still fail in real-world voice agents under conditions that current evaluations do not systematically cover. Without diagnostic tools that isolate specific failure factors, practitioners cannot anticipate which conditions, in which languages, will cause what degree of degradation. We introduce WildASR, a multilingual (four-language) diagnostic benchmark sourced entirely from real human speech that factorizes ASR robustness along three axes: environmental degradation, demographic shift, and linguistic diversity. Evaluating seven widely used ASR systems, we find severe and uneven performance degradation, and model robustness does not transfer across languages or conditions. Critically, models often hallucinate plausible but unspoken content under partial or degraded inputs, creating concrete safety risks for downstream agent behavior. Our results demonstrate that targeted, factor-isolated evaluation is essential for understanding and improving ASR reliability in production systems. Besides the benchmark itself, we also present three analytical tools that practitioners can use to guide deployment decisions.
Multimodal Priors-Augmented Text-Driven 3D Human-Object Interaction Generation
Feb 11, 2026We address the challenging task of text-driven 3D human-object interaction (HOI) motion generation. Existing methods primarily rely on a direct text-to-HOI mapping, which suffers from three key limitations due to the significant cross-modality gap: (Q1) sub-optimal human motion, (Q2) unnatural object motion, and (Q3) weak interaction between humans and objects. To address these challenges, we propose MP-HOI, a novel framework grounded in four core insights: (1) Multimodal Data Priors: We leverage multimodal data (text, image, pose/object) from large multimodal models as priors to guide HOI generation, which tackles Q1 and Q2 in data modeling. (2) Enhanced Object Representation: We improve existing object representations by incorporating geometric keypoints, contact features, and dynamic properties, enabling expressive object representations, which tackles Q2 in data representation. (3) Multimodal-Aware Mixture-of-Experts (MoE) Model: We propose a modality-aware MoE model for effective multimodal feature fusion paradigm, which tackles Q1 and Q2 in feature fusion. (4) Cascaded Diffusion with Interaction Supervision: We design a cascaded diffusion framework that progressively refines human-object interaction features under dedicated supervision, which tackles Q3 in interaction refinement. Comprehensive experiments demonstrate that MP-HOI outperforms existing approaches in generating high-fidelity and fine-grained HOI motions.
Dynamic Worlds, Dynamic Humans: Generating Virtual Human-Scene Interaction Motion in Dynamic Scenes
Jan 27, 2026Scenes are continuously undergoing dynamic changes in the real world. However, existing human-scene interaction generation methods typically treat the scene as static, which deviates from reality. Inspired by world models, we introduce Dyn-HSI, the first cognitive architecture for dynamic human-scene interaction, which endows virtual humans with three humanoid components. (1)Vision (human eyes): we equip the virtual human with a Dynamic Scene-Aware Navigation, which continuously perceives changes in the surrounding environment and adaptively predicts the next waypoint. (2)Memory (human brain): we equip the virtual human with a Hierarchical Experience Memory, which stores and updates experiential data accumulated during training. This allows the model to leverage prior knowledge during inference for context-aware motion priming, thereby enhancing both motion quality and generalization. (3) Control (human body): we equip the virtual human with Human-Scene Interaction Diffusion Model, which generates high-fidelity interaction motions conditioned on multimodal inputs. To evaluate performance in dynamic scenes, we extend the existing static human-scene interaction datasets to construct a dynamic benchmark, Dyn-Scenes. We conduct extensive qualitative and quantitative experiments to validate Dyn-HSI, showing that our method consistently outperforms existing approaches and generates high-quality human-scene interaction motions in both static and dynamic settings.
DynaQuant: Dynamic Mixed-Precision Quantization for Learned Image Compression
Nov 11, 2025Prevailing quantization techniques in Learned Image Compression (LIC) typically employ a static, uniform bit-width across all layers, failing to adapt to the highly diverse data distributions and sensitivity characteristics inherent in LIC models. This leads to a suboptimal trade-off between performance and efficiency. In this paper, we introduce DynaQuant, a novel framework for dynamic mixed-precision quantization that operates on two complementary levels. First, we propose content-aware quantization, where learnable scaling and offset parameters dynamically adapt to the statistical variations of latent features. This fine-grained adaptation is trained end-to-end using a novel Distance-aware Gradient Modulator (DGM), which provides a more informative learning signal than the standard Straight-Through Estimator. Second, we introduce a data-driven, dynamic bit-width selector that learns to assign an optimal bit precision to each layer, dynamically reconfiguring the network's precision profile based on the input data. Our fully dynamic approach offers substantial flexibility in balancing rate-distortion (R-D) performance and computational cost. Experiments demonstrate that DynaQuant achieves rd performance comparable to full-precision models while significantly reducing computational and storage requirements, thereby enabling the practical deployment of advanced LIC on diverse hardware platforms.
Dataset Distillation as Data Compression: A Rate-Utility Perspective
Jul 23, 2025Driven by the ``scale-is-everything'' paradigm, modern machine learning increasingly demands ever-larger datasets and models, yielding prohibitive computational and storage requirements. Dataset distillation mitigates this by compressing an original dataset into a small set of synthetic samples, while preserving its full utility. Yet, existing methods either maximize performance under fixed storage budgets or pursue suitable synthetic data representations for redundancy removal, without jointly optimizing both objectives. In this work, we propose a joint rate-utility optimization method for dataset distillation. We parameterize synthetic samples as optimizable latent codes decoded by extremely lightweight networks. We estimate the Shannon entropy of quantized latents as the rate measure and plug any existing distillation loss as the utility measure, trading them off via a Lagrange multiplier. To enable fair, cross-method comparisons, we introduce bits per class (bpc), a precise storage metric that accounts for sample, label, and decoder parameter costs. On CIFAR-10, CIFAR-100, and ImageNet-128, our method achieves up to $170\times$ greater compression than standard distillation at comparable accuracy. Across diverse bpc budgets, distillation losses, and backbone architectures, our approach consistently establishes better rate-utility trade-offs.
EmergentTTS-Eval: Evaluating TTS Models on Complex Prosodic, Expressiveness, and Linguistic Challenges Using Model-as-a-Judge
May 29, 2025Text-to-Speech (TTS) benchmarks often fail to capture how well models handle nuanced and semantically complex text. Building on $\textit{EmergentTTS}$, we introduce $\textit{EmergentTTS-Eval}$, a comprehensive benchmark covering six challenging TTS scenarios: emotions, paralinguistics, foreign words, syntactic complexity, complex pronunciation (e.g. URLs, formulas), and questions. Crucially, our framework automates both test-case generation and evaluation, making the benchmark easily extensible. Starting from a small set of human-written seed prompts, we iteratively extend them using LLMs to target specific structural, phonetic and prosodic challenges, resulting in 1,645 diverse test cases. Moreover, we employ a model-as-a-judge approach, using a Large Audio Language Model (LALM) to assess the speech across multiple dimensions such as expressed emotion, prosodic, intonational, and pronunciation accuracy. We evaluate state-of-the-art open-source and proprietary TTS systems, such as 11Labs, Deepgram, and OpenAI's 4o-mini-TTS, on EmergentTTS-Eval, demonstrating its ability to reveal fine-grained performance differences. Results show that the model-as-a-judge approach offers robust TTS assessment and a high correlation with human preferences. We open source the evaluation $\href{https://github.com/boson-ai/EmergentTTS-Eval-public}{code}$ and the $\href{https://huggingface.co/datasets/bosonai/EmergentTTS-Eval}{dataset}$.
Learned Image Compression with Dictionary-based Entropy Model
Apr 01, 2025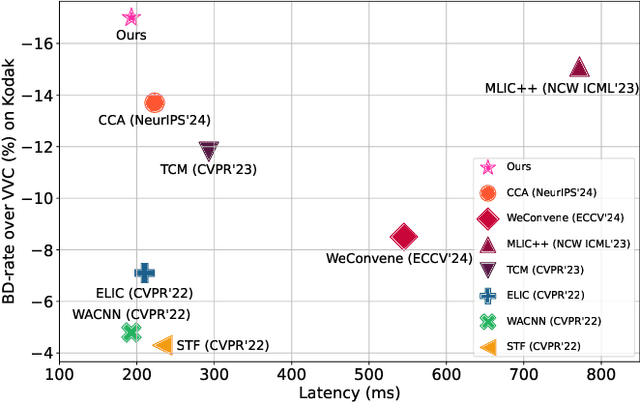
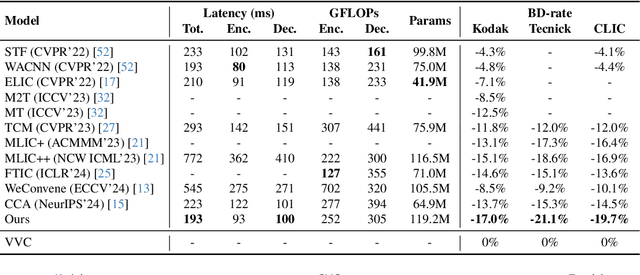
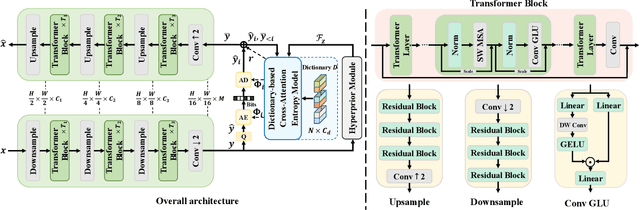
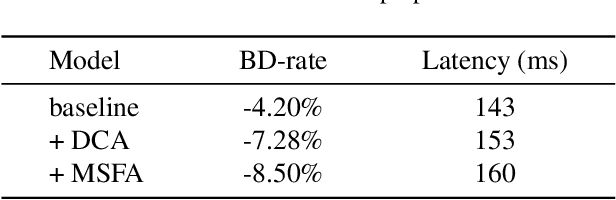
Learned image compression methods have attracted great research interest and exhibited superior rate-distortion performance to the best classical image compression standards of the present. The entropy model plays a key role in learned image compression, which estimates the probability distribution of the latent representation for further entropy coding. Most existing methods employed hyper-prior and auto-regressive architectures to form their entropy models. However, they only aimed to explore the internal dependencies of latent representation while neglecting the importance of extracting prior from training data. In this work, we propose a novel entropy model named Dictionary-based Cross Attention Entropy model, which introduces a learnable dictionary to summarize the typical structures occurring in the training dataset to enhance the entropy model. Extensive experimental results have demonstrated that the proposed model strikes a better balance between performance and latency, achieving state-of-the-art results on various benchmark datasets.
ShiftLIC: Lightweight Learned Image Compression with Spatial-Channel Shift Operations
Mar 29, 2025Learned Image Compression (LIC) has attracted considerable attention due to their outstanding rate-distortion (R-D) performance and flexibility. However, the substantial computational cost poses challenges for practical deployment. The issue of feature redundancy in LIC is rarely addressed. Our findings indicate that many features within the LIC backbone network exhibit similarities. This paper introduces ShiftLIC, a novel and efficient LIC framework that employs parameter-free shift operations to replace large-kernel convolutions, significantly reducing the model's computational burden and parameter count. Specifically, we propose the Spatial Shift Block (SSB), which combines shift operations with small-kernel convolutions to replace large-kernel. This approach maintains feature extraction efficiency while reducing both computational complexity and model size. To further enhance the representation capability in the channel dimension, we propose a channel attention module based on recursive feature fusion. This module enhances feature interaction while minimizing computational overhead. Additionally, we introduce an improved entropy model integrated with the SSB module, making the entropy estimation process more lightweight and thereby comprehensively reducing computational costs. Experimental results demonstrate that ShiftLIC outperforms leading compression methods, such as VVC Intra and GMM, in terms of computational cost, parameter count, and decoding latency. Additionally, ShiftLIC sets a new SOTA benchmark with a BD-rate gain per MACs/pixel of -102.6\%, showcasing its potential for practical deployment in resource-constrained environments. The code is released at https://github.com/baoyu2020/ShiftLIC.
Fg-T2M++: LLMs-Augmented Fine-Grained Text Driven Human Motion Generation
Feb 08, 2025We address the challenging problem of fine-grained text-driven human motion generation. Existing works generate imprecise motions that fail to accurately capture relationships specified in text due to: (1) lack of effective text parsing for detailed semantic cues regarding body parts, (2) not fully modeling linguistic structures between words to comprehend text comprehensively. To tackle these limitations, we propose a novel fine-grained framework Fg-T2M++ that consists of: (1) an LLMs semantic parsing module to extract body part descriptions and semantics from text, (2) a hyperbolic text representation module to encode relational information between text units by embedding the syntactic dependency graph into hyperbolic space, and (3) a multi-modal fusion module to hierarchically fuse text and motion features. Extensive experiments on HumanML3D and KIT-ML datasets demonstrate that Fg-T2M++ outperforms SOTA methods, validating its ability to accurately generate motions adhering to comprehensive text semantics.
Learned Scanpaths Aid Blind Panoramic Video Quality Assessment
Mar 30, 2024Panoramic videos have the advantage of providing an immersive and interactive viewing experience. Nevertheless, their spherical nature gives rise to various and uncertain user viewing behaviors, which poses significant challenges for panoramic video quality assessment (PVQA). In this work, we propose an end-to-end optimized, blind PVQA method with explicit modeling of user viewing patterns through visual scanpaths. Our method consists of two modules: a scanpath generator and a quality assessor. The scanpath generator is initially trained to predict future scanpaths by minimizing their expected code length and then jointly optimized with the quality assessor for quality prediction. Our blind PVQA method enables direct quality assessment of panoramic images by treating them as videos composed of identical frames. Experiments on three public panoramic image and video quality datasets, encompassing both synthetic and authentic distortions, validate the superiority of our blind PVQA model over existing methods.