 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergentTTS-Eval: Evaluating TTS Models on Complex Prosodic, Expressiveness, and Linguistic Challenges Using Model-as-a-Judge
May 29, 2025Text-to-Speech (TTS) benchmarks often fail to capture how well models handle nuanced and semantically complex text. Building on $\textit{EmergentTTS}$, we introduce $\textit{EmergentTTS-Eval}$, a comprehensive benchmark covering six challenging TTS scenarios: emotions, paralinguistics, foreign words, syntactic complexity, complex pronunciation (e.g. URLs, formulas), and questions. Crucially, our framework automates both test-case generation and evaluation, making the benchmark easily extensible. Starting from a small set of human-written seed prompts, we iteratively extend them using LLMs to target specific structural, phonetic and prosodic challenges, resulting in 1,645 diverse test cases. Moreover, we employ a model-as-a-judge approach, using a Large Audio Language Model (LALM) to assess the speech across multiple dimensions such as expressed emotion, prosodic, intonational, and pronunciation accuracy. We evaluate state-of-the-art open-source and proprietary TTS systems, such as 11Labs, Deepgram, and OpenAI's 4o-mini-TTS, on EmergentTTS-Eval, demonstrating its ability to reveal fine-grained performance differences. Results show that the model-as-a-judge approach offers robust TTS assessment and a high correlation with human preferences. We open source the evaluation $\href{https://github.com/boson-ai/EmergentTTS-Eval-public}{code}$ and the $\href{https://huggingface.co/datasets/bosonai/EmergentTTS-Eval}{dataset}$.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
BeamVQ: Beam Search with Vector Quantization to Mitigate Data Scarcity in Physical Spatiotemporal Forecasting
Feb 26, 2025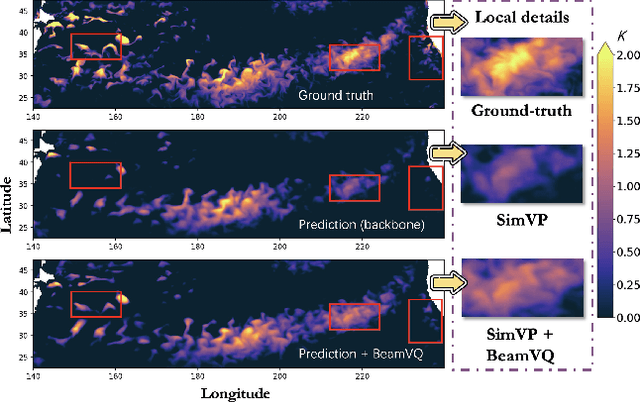
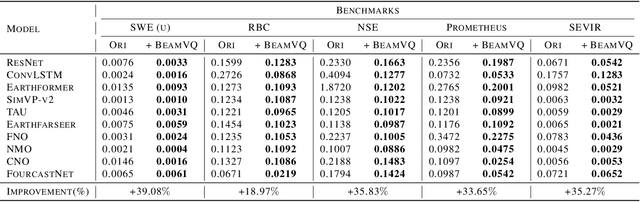
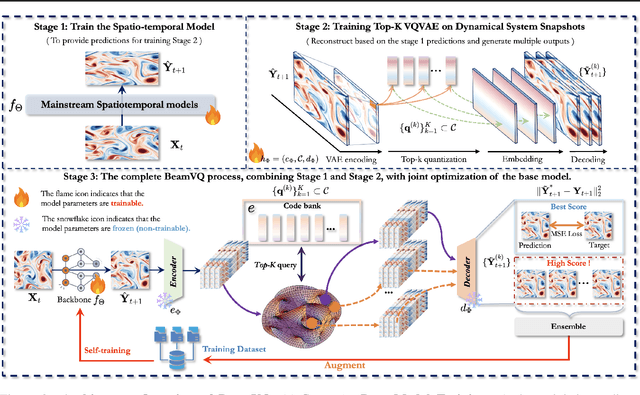
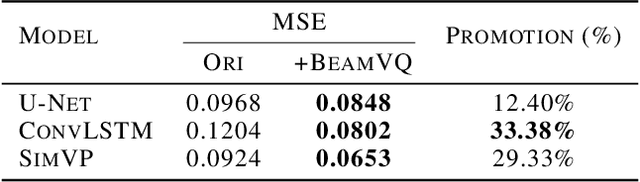
In practice, physical spatiotemporal forecasting can suffer from data scarcity, because collecting large-scale data is non-trivial, especially for extreme events. Hence, we propose \method{}, a novel probabilistic framework to realize iterative self-training with new self-ensemble strategies, achieving better physical consistency and generalization on extreme events. Following any base forecasting model, we can encode its deterministic outputs into a latent space and retrieve multiple codebook entries to generate probabilistic outputs. Then BeamVQ extends the beam search from discrete spaces to the continuous state spaces in this field. We can further employ domain-specific metrics (e.g., Critical Success Index for extreme events) to filter out the top-k candidates and develop the new self-ensemble strategy by combining the high-quality candidates. The self-ensemble can not only improve the inference quality and robustness but also iteratively augment the training datasets during continuous self-training. Consequently, BeamVQ realizes the exploration of rare but critical phenomena beyond the original dataset. Comprehensive experiments on different benchmarks and backbones show that BeamVQ consistently reduces forecasting MSE (up to 39%), enhancing extreme events detection and proving its effectiveness in handling data scarcity.
L3Ms -- Lagrange Large Language Models
Oct 28, 2024



Supervised fine-tuning (SFT) and alignment of large language models (LLMs) are key steps in providing a good user experience. However, the concept of an appropriate alignment is inherently application-dependent, and current methods often rely on heuristic choices to drive the optimization. In this work, we formulate SFT and alignment as a constrained optimization problem, where the LLM is trained on a task while being required to meet application-specific requirements, without resorting to heuristics. To solve this, we propose Lagrange Large Language Models (L3Ms), which employ logarithmic barriers to enforce the constraints. This approach allows for the customization of L3Ms across diverse applications while avoiding heuristic-driven processes. We demonstrate experimentally the versatility and efficacy of L3Ms in achieving tailored alignments for various applications.
BeamVQ: Aligning Space-Time Forecasting Model via Self-training on Physics-aware Metrics
May 27, 2024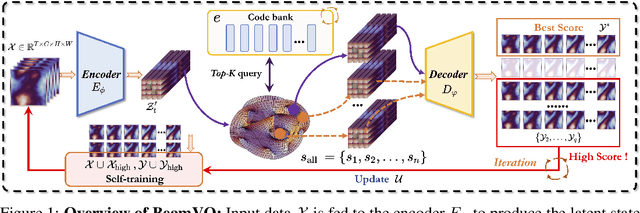
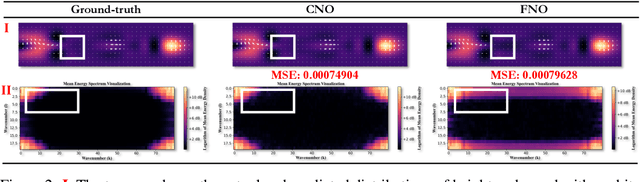
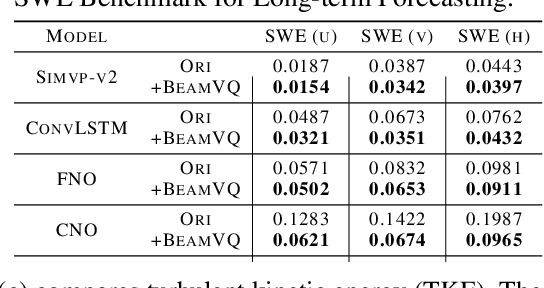
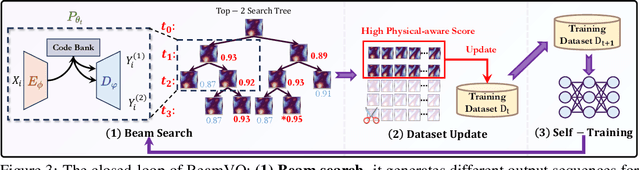
Data-driven deep learning has emerged as the new paradigm to model complex physical space-time systems. These data-driven methods learn patterns by optimizing statistical metrics and tend to overlook the adherence to physical laws, unlike traditional model-driven numerical methods. Thus, they often generate predictions that are not physically realistic. On the other hand, by sampling a large amount of high quality predictions from a data-driven model, some predictions will be more physically plausible than the others and closer to what will happen in the future. Based on this observation, we propose \emph{Beam search by Vector Quantization} (BeamVQ) to enhance the physical alignment of data-driven space-time forecasting models. The key of BeamVQ is to train model on self-generated samples filtered with physics-aware metrics. To be flexibly support different backbone architectures, BeamVQ leverages a code bank to transform any encoder-decoder model to the continuous state space into discrete codes. Afterwards, it iteratively employs beam search to sample high-quality sequences, retains those with the highest physics-aware scores, and trains model on the new dataset. Comprehensive experiments show that BeamVQ not only gave an average statistical skill score boost for more than 32% for ten backbones on five datasets, but also significantly enhances physics-aware metrics.
Bridging Remote Sensors with Multisensor Geospatial Foundation Models
Apr 01, 2024In the realm of geospatial analysis, the diversity of remote sensors, encompassing both optical and microwave technologies, offers a wealth of distinct observational capabilities. Recognizing this, we present msGFM, a multisensor geospatial foundation model that effectively unifies data from four key sensor modalities. This integration spans an expansive dataset of two million multisensor images. msGFM is uniquely adept at handling both paired and unpaired sensor data. For data originating from identical geolocations, our model employs an innovative cross-sensor pretraining approach in masked image modeling, enabling the synthesis of joint representations from diverse sensors. msGFM, incorporating four remote sensors, upholds strong performance, forming a comprehensive model adaptable to various sensor types. msGFM has demonstrated enhanced proficiency in a range of both single-sensor and multisensor downstream tasks. These include scene classification, segmentation, cloud removal, and pan-sharpening. A key discovery of our research is that representations derived from natural images are not always compatible with the distinct characteristics of geospatial remote sensors, underscoring the limitations of existing representations in this field. Our work can serve as a guide for developing multisensor geospatial pretraining models, paving the way for more advanced geospatial capabilities.
PreDiff: Precipitation Nowcasting with Latent Diffusion Models
Jul 19, 2023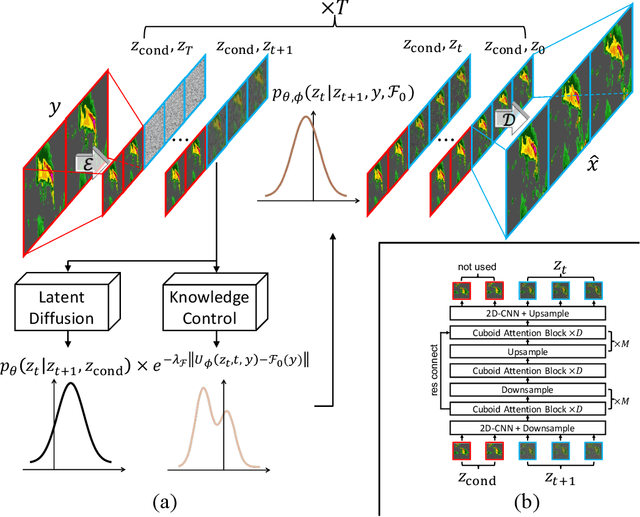
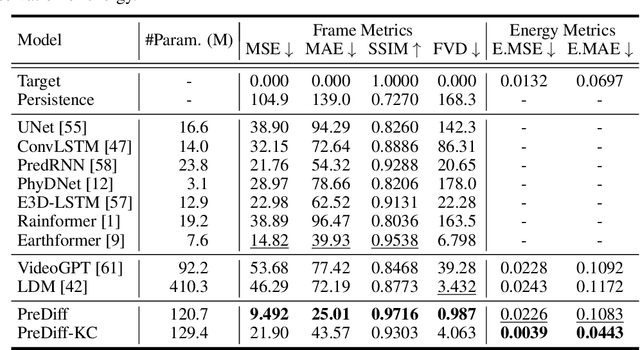

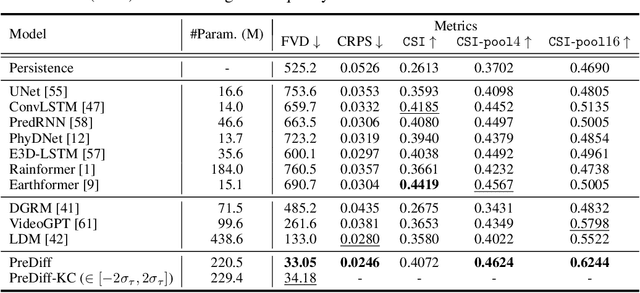
Earth system forecasting has traditionally relied on complex physical models that are computationally expensive and require significant domain expertise. In the past decade, the unprecedented increase in spatiotemporal Earth observation data has enabled data-driven forecasting models using deep learning techniques. These models have shown promise for diverse Earth system forecasting tasks but either struggle with handling uncertainty or neglect domain-specific prior knowledge, resulting in averaging possible futures to blurred forecasts or generating physically implausible predictions. To address these limitations, we propose a two-stage pipeline for probabilistic spatiotemporal forecasting: 1) We develop PreDiff, a conditional latent diffusion model capable of probabilistic forecasts. 2) We incorporate an explicit knowledge control mechanism to align forecasts with domain-specific physical constraints. This is achieved by estimating the deviation from imposed constraints at each denoising step and adjusting the transition distribution accordingly. We conduct empirical studies on two datasets: N-body MNIST, a synthetic dataset with chaotic behavior, and SEVIR, a real-world precipitation nowcasting dataset. Specifically, we impose the law of conservation of energy in N-body MNIST and anticipated precipitation intensity in SEVIR. Experiments demonstrate the effectiveness of PreDiff in handling uncertainty, incorporating domain-specific prior knowledge, and generating forecasts that exhibit high operational utility.
Automated Few-shot Classification with Instruction-Finetuned Language Models
May 21, 2023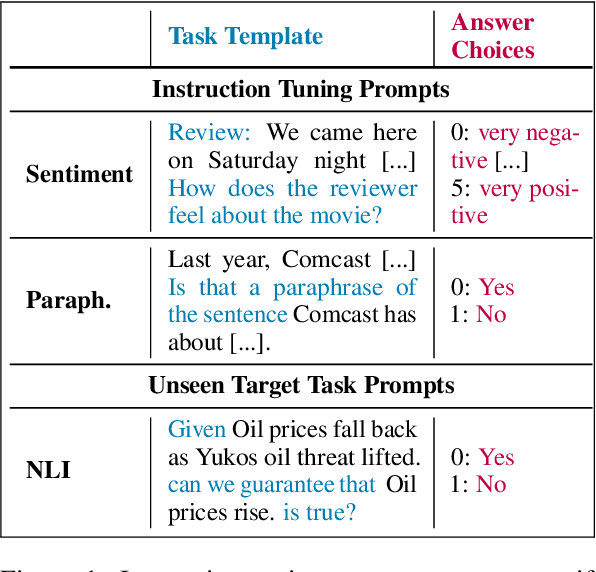

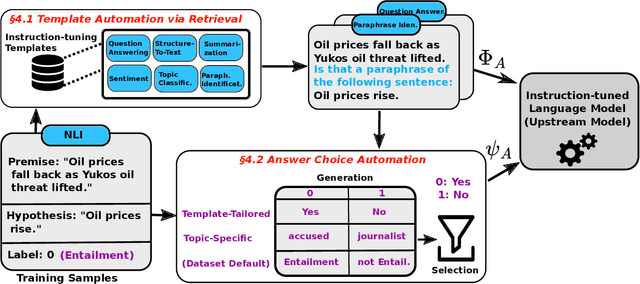
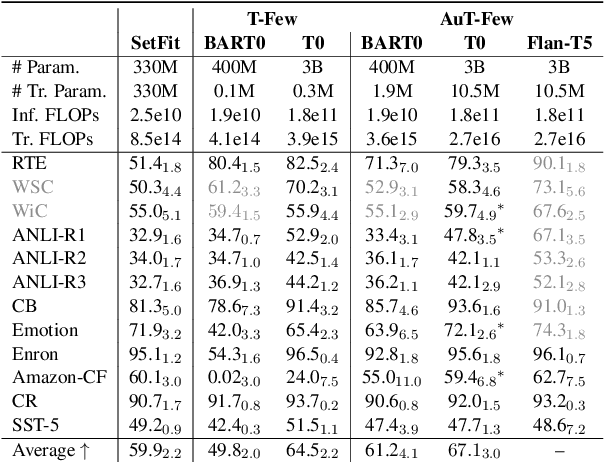
A particularly successful class of approaches for few-shot learning combines language models with prompts -- hand-crafted task descriptions that complement data samples. However, designing prompts by hand for each task commonly requires domain knowledge and substantial guesswork. We observe, in the context of classification tasks, that instruction finetuned language models exhibit remarkable prompt robustness, and we subsequently propose a simple method to eliminate the need for handcrafted prompts, named AuT-Few. This approach consists of (i) a prompt retrieval module that selects suitable task instructions from the instruction-tuning knowledge base, and (ii) the generation of two distinct, semantically meaningful, class descriptions and a selection mechanism via cross-validation. Over $12$ datasets, spanning $8$ classification tasks, we show that AuT-Few outperforms current state-of-the-art few-shot learning methods. Moreover, AuT-Few is the best ranking method across datasets on the RAFT few-shot benchmark. Notably, these results are achieved without task-specific handcrafted prompts on unseen tasks.
Tailoring Instructions to Student's Learning Levels Boosts Knowledge Distillation
May 16, 2023



It has been commonly observed that a teacher model with superior performance does not necessarily result in a stronger student, highlighting a discrepancy between current teacher training practices and effective knowledge transfer. In order to enhance the guidance of the teacher training process, we introduce the concept of distillation influence to determine the impact of distillation from each training sample on the student's generalization ability. In this paper, we propose Learning Good Teacher Matters (LGTM), an efficient training technique for incorporating distillation influence into the teacher's learning process. By prioritizing samples that are likely to enhance the student's generalization ability, our LGTM outperforms 10 common knowledge distillation baselines on 6 text classification tasks in the GLUE benchmark.
XTab: Cross-table Pretraining for Tabular Transformers
May 10, 2023



The success of self-supervised learning in computer vision and natural language processing has motivated pretraining methods on tabular data. However, most existing tabular self-supervised learning models fail to leverage information across multiple data tables and cannot generalize to new tables. In this work, we introduce XTab, a framework for cross-table pretraining of tabular transformers on datasets from various domains. We address the challenge of inconsistent column types and quantities among tables by utilizing independent featurizers and using federated learning to pretrain the shared component. Tested on 84 tabular prediction tasks from the OpenML-AutoML Benchmark (AMLB), we show that (1) XTab consistently boosts the generalizability, learning speed, and performance of multiple tabular transformers, (2) by pretraining FT-Transformer via XTab, we achieve superior performance than other state-of-the-art tabular deep learning models on various tasks such as regression, binary, and multiclass classification.