 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeamVQ: Beam Search with Vector Quantization to Mitigate Data Scarcity in Physical Spatiotemporal Forecasting
Feb 26, 2025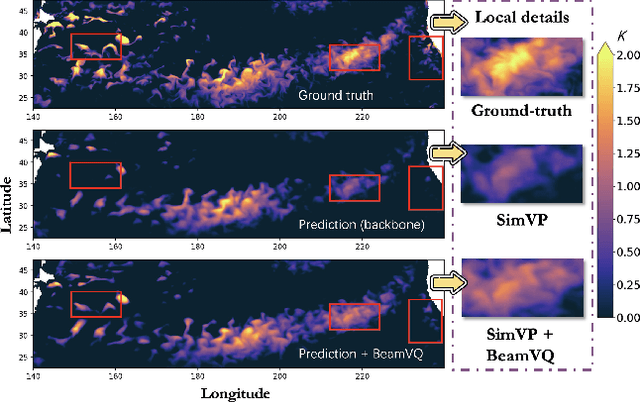
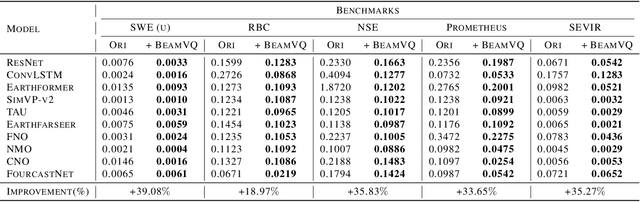
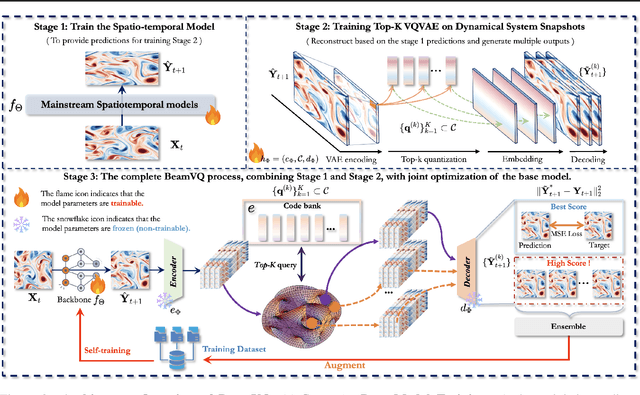
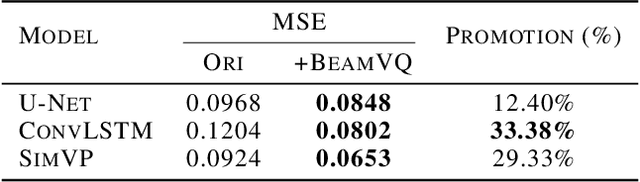
In practice, physical spatiotemporal forecasting can suffer from data scarcity, because collecting large-scale data is non-trivial, especially for extreme events. Hence, we propose \method{}, a novel probabilistic framework to realize iterative self-training with new self-ensemble strategies, achieving better physical consistency and generalization on extreme events. Following any base forecasting model, we can encode its deterministic outputs into a latent space and retrieve multiple codebook entries to generate probabilistic outputs. Then BeamVQ extends the beam search from discrete spaces to the continuous state spaces in this field. We can further employ domain-specific metrics (e.g., Critical Success Index for extreme events) to filter out the top-k candidates and develop the new self-ensemble strategy by combining the high-quality candidates. The self-ensemble can not only improve the inference quality and robustness but also iteratively augment the training datasets during continuous self-training. Consequently, BeamVQ realizes the exploration of rare but critical phenomena beyond the original dataset. Comprehensive experiments on different benchmarks and backbones show that BeamVQ consistently reduces forecasting MSE (up to 39%), enhancing extreme events detection and proving its effectiveness in handling data scarcity.
Robust Sparse Mean Estimation via Incremental Learning
May 24, 2023In this paper, we study the problem of robust sparse mean estimation, where the goal is to estimate a $k$-sparse mean from a collection of partially corrupted samples drawn from a heavy-tailed distribution. Existing estimators face two critical challenges in this setting. First, they are limited by a conjectured computational-statistical tradeoff, implying that any computationally efficient algorithm needs $\tilde\Omega(k^2)$ samples, while its statistically-optimal counterpart only requires $\tilde O(k)$ samples. Second, the existing estimators fall short of practical use as they scale poorly with the ambient dimension. This paper presents a simple mean estimator that overcomes both challenges under moderate conditions: it runs in near-linear time and memory (both with respect to the ambient dimension) while requiring only $\tilde O(k)$ samples to recover the true mean. At the core of our method lies an incremental learning phenomenon: we introduce a simple nonconvex framework that can incrementally learn the top-$k$ nonzero elements of the mean while keeping the zero elements arbitrarily small. Unlike existing estimators, our method does not need any prior knowledge of the sparsity level $k$. We prove the optimality of our estimator by providing a matching information-theoretic lower bound. Finally, we conduct a series of simulations to corroborate our theoretical findings. Our code is available at https://github.com/huihui0902/Robust_mean_estimation.