 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
TransMamba: Flexibly Switching between Transformer and Mamba
Mar 31, 2025Transformers are the cornerstone of modern large language models, but their quadratic computational complexity limits efficiency in long-sequence processing. Recent advancements in Mamba, a state space model (SSM) with linear complexity, offer promising efficiency gains but suffer from unstable contextual learning and multitask generalization. This paper proposes TransMamba, a novel framework that unifies Transformer and Mamba through shared parameter matrices (e.g., QKV and CBx), and thus could dynamically switch between attention and SSM mechanisms at different token lengths and layers. We design the Memory converter to bridge Transformer and Mamba by converting attention outputs into SSM-compatible states, ensuring seamless information flow at TransPoints where the transformation happens. The TransPoint scheduling is also thoroughly explored for further improvements. We conducted extensive experiments demonstrating that TransMamba achieves superior training efficiency and performance compared to baselines, and validated the deeper consistency between Transformer and Mamba paradigms, offering a scalable solution for next-generation sequence modeling.
BeamVQ: Beam Search with Vector Quantization to Mitigate Data Scarcity in Physical Spatiotemporal Forecasting
Feb 26, 2025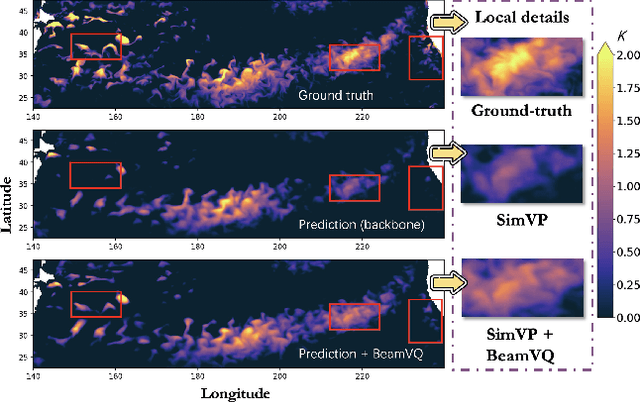
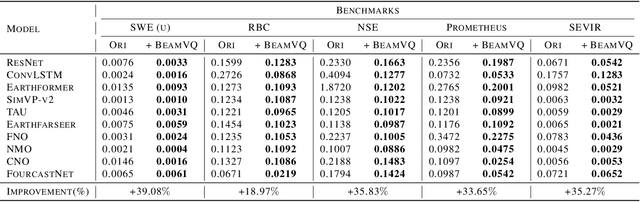
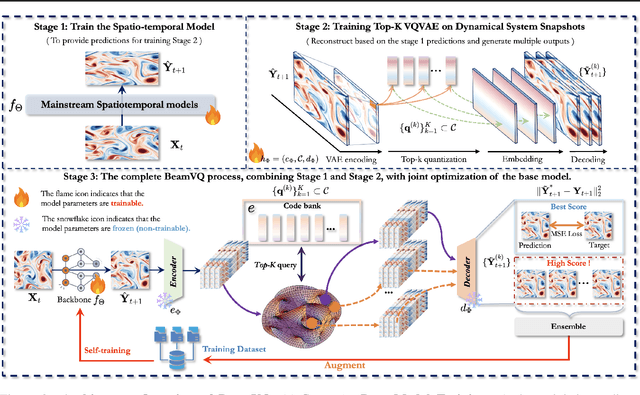
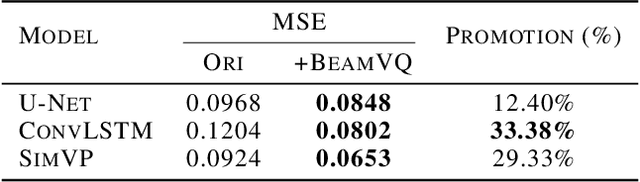
In practice, physical spatiotemporal forecasting can suffer from data scarcity, because collecting large-scale data is non-trivial, especially for extreme events. Hence, we propose \method{}, a novel probabilistic framework to realize iterative self-training with new self-ensemble strategies, achieving better physical consistency and generalization on extreme events. Following any base forecasting model, we can encode its deterministic outputs into a latent space and retrieve multiple codebook entries to generate probabilistic outputs. Then BeamVQ extends the beam search from discrete spaces to the continuous state spaces in this field. We can further employ domain-specific metrics (e.g., Critical Success Index for extreme events) to filter out the top-k candidates and develop the new self-ensemble strategy by combining the high-quality candidates. The self-ensemble can not only improve the inference quality and robustness but also iteratively augment the training datasets during continuous self-training. Consequently, BeamVQ realizes the exploration of rare but critical phenomena beyond the original dataset. Comprehensive experiments on different benchmarks and backbones show that BeamVQ consistently reduces forecasting MSE (up to 39%), enhancing extreme events detection and proving its effectiveness in handling data scarcity.
Scaling Laws for Floating Point Quantization Training
Jan 05, 2025



Low-precision training is considered an effective strategy for reducing both training and downstream inference costs. Previous scaling laws for precision mainly focus on integer quantization, which pay less attention to the constituents in floating-point quantization and thus cannot well fit the LLM losses in this scenario. In contrast, while floating-point quantization training is more commonly implemented in production, the research on it has been relatively superficial. In this paper, we thoroughly explore the effects of floating-point quantization targets, exponent bits, mantissa bits, and the calculation granularity of the scaling factor in floating-point quantization training performance of LLM models. While presenting an accurate floating-point quantization unified scaling law, we also provide valuable suggestions for the community: (1) Exponent bits contribute slightly more to the model performance than mantissa bits. We provide the optimal exponent-mantissa bit ratio for different bit numbers, which is available for future reference by hardware manufacturers; (2) We discover the formation of the critical data size in low-precision LLM training. Too much training data exceeding the critical data size will inversely bring in degradation of LLM performance; (3) The optimal floating-point quantization precision is directly proportional to the computational power, but within a wide computational power range, we estimate that the best cost-performance precision lies between 4-8 bits.
More Expressive Attention with Negative Weights
Nov 14, 2024We propose a novel attention mechanism, named Cog Attention, that enables attention weights to be negative for enhanced expressiveness, which stems from two key factors: (1) Cog Attention can shift the token deletion and copying function from a static OV matrix to dynamic QK inner products, with the OV matrix now focusing more on refinement or modification. The attention head can simultaneously delete, copy, or retain tokens by assigning them negative, positive, or minimal attention weights, respectively. As a result, a single attention head becomes more flexible and expressive. (2) Cog Attention improves the model's robustness against representational collapse, which can occur when earlier tokens are over-squashed into later positions, leading to homogeneous representations. Negative weights reduce effective information paths from earlier to later tokens, helping to mitigate this issue. We develop Transformer-like models which use Cog Attention as attention modules, including decoder-only models for language modeling and U-ViT diffusion models for image generation. Experiments show that models using Cog Attention exhibit superior performance compared to those employing traditional softmax attention modules. Our approach suggests a promising research direction for rethinking and breaking the entrenched constraints of traditional softmax attention, such as the requirement for non-negative weights.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
HMoE: Heterogeneous Mixture of Experts for Language Modeling
Aug 20, 2024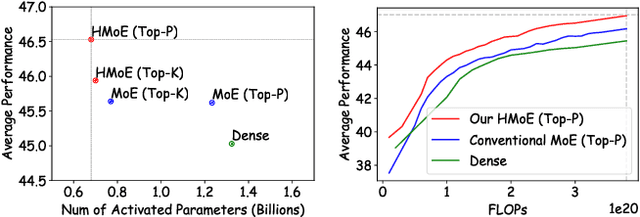
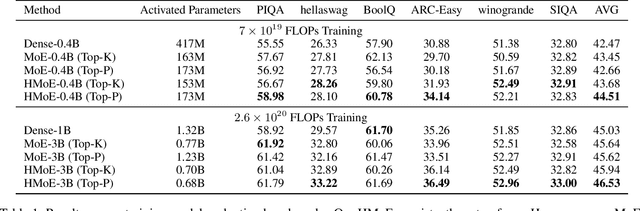
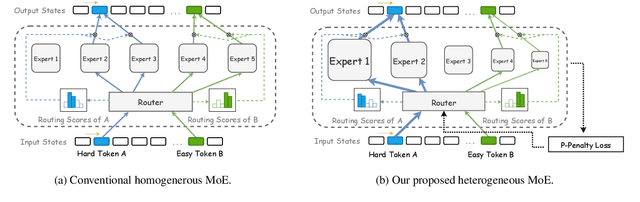

Mixture of Experts (MoE) offers remarkable performance and computational efficiency by selectively activating subsets of model parameters. Traditionally, MoE models use homogeneous experts, each with identical capacity. However, varying complexity in input data necessitates experts with diverse capabilities, while homogeneous MoE hinders effective expert specialization and efficient parameter utilization. In this study, we propose a novel Heterogeneous Mixture of Experts (HMoE), where experts differ in size and thus possess diverse capacities. This heterogeneity allows for more specialized experts to handle varying token complexities more effectively. To address the imbalance in expert activation, we propose a novel training objective that encourages the frequent activation of smaller experts, enhancing computational efficiency and parameter utilization. Extensive experiments demonstrate that HMoE achieves lower loss with fewer activated parameters and outperforms conventional homogeneous MoE models on various pre-training evaluation benchmarks. Codes will be released upon acceptance.
Efficiently Training 7B LLM with 1 Million Sequence Length on 8 GPUs
Jul 16, 2024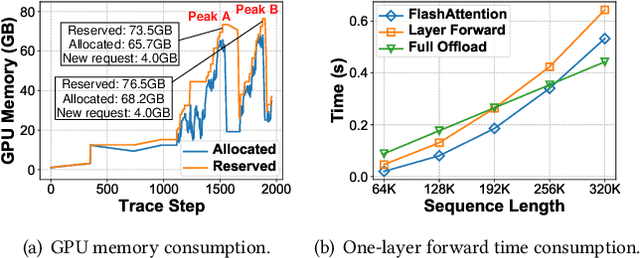

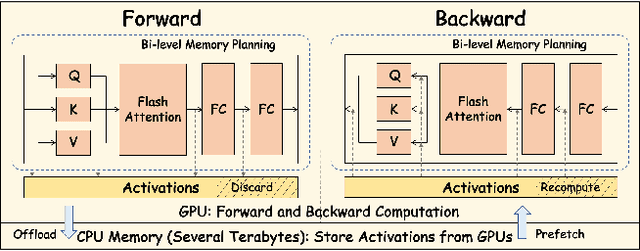
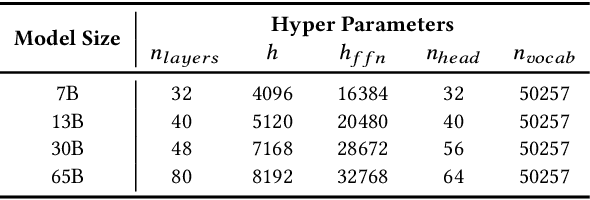
Nowadays, Large Language Models (LLMs) have been trained using extended context lengths to foster more creative applications. However, long context training poses great challenges considering the constraint of GPU memory. It not only leads to substantial activation memory consumption during training, but also incurs considerable memory fragmentation. To facilitate long context training, existing frameworks have adopted strategies such as recomputation and various forms of parallelisms. Nevertheless, these techniques rely on redundant computation or extensive communication, resulting in low Model FLOPS Utilization (MFU). In this paper, we propose MEMO, a novel LLM training framework designed for fine-grained activation memory management. Given the quadratic scaling of computation and linear scaling of memory with sequence lengths when using FlashAttention, we offload memory-consuming activations to CPU memory after each layer's forward pass and fetch them during the backward pass. To maximize the swapping of activations without hindering computation, and to avoid exhausting limited CPU memory, we implement a token-wise activation recomputation and swapping mechanism. Furthermore, we tackle the memory fragmentation issue by employing a bi-level Mixed Integer Programming (MIP) approach, optimizing the reuse of memory across transformer layers. Empirical results demonstrate that MEMO achieves an average of 2.42x and 2.26x MFU compared to Megatron-LM and DeepSpeed, respectively. This improvement is attributed to MEMO's ability to minimize memory fragmentation, reduce recomputation and intensive communication, and circumvent the delays associated with the memory reorganization process due to fragmentation. By leveraging fine-grained activation memory management, MEMO facilitates efficient training of 7B LLM with 1 million sequence length on just 8 A800 GPUs, achieving an MFU of 52.30%.
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
May 23, 2024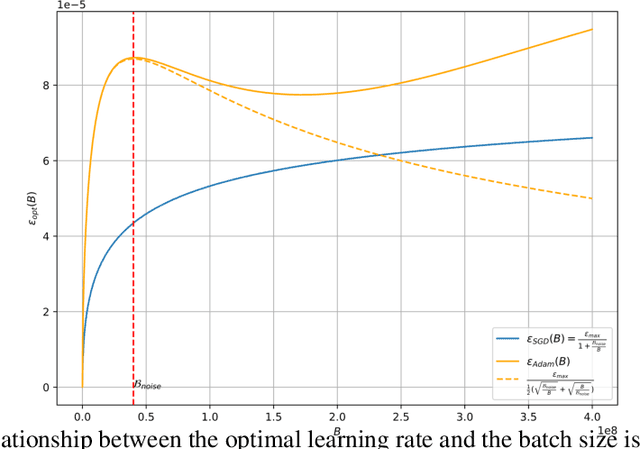
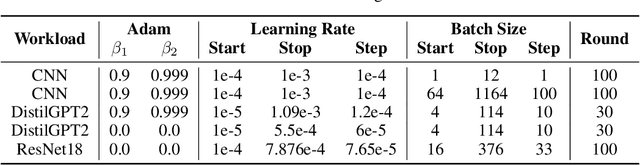
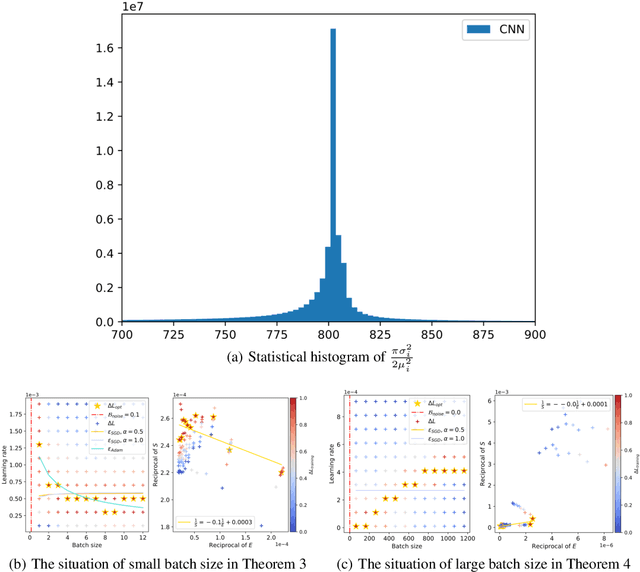
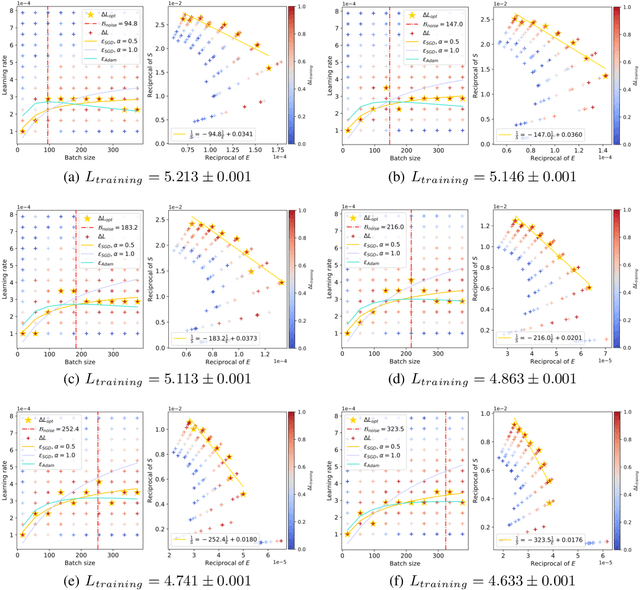
In current deep learning tasks, Adam style optimizers such as Adam, Adagrad, RMSProp, Adafactor, and Lion have been widely used as alternatives to SGD style optimizers. These optimizers typically update model parameters using the sign of gradients, resulting in more stable convergence curves. The learning rate and the batch size are the most critical hyperparameters for optimizers, which require careful tuning to enable effective convergence. Previous research has shown that the optimal learning rate increases linearly or follows similar rules with batch size for SGD style optimizers. However, this conclusion is not applicable to Adam style optimizers. In this paper, we elucidate the connection between optimal learning rates and batch sizes for Adam style optimizers through both theoretical analysis and extensive experiments. First, we raise the scaling law between batch sizes and optimal learning rates in the sign of gradient case, in which we prove that the optimal learning rate first rises and then falls as the batch size increases. Moreover, the peak value of the surge will gradually move toward the larger batch size as training progresses. Second, we conducted experiments on various CV and NLP tasks and verified the correctness of the scaling law.
HAL: Improved Text-Image Matching by Mitigating Visual Semantic Hubs
Nov 22, 2019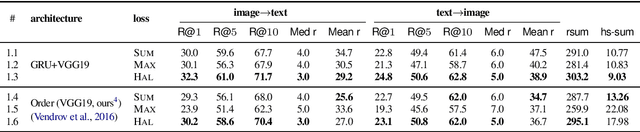
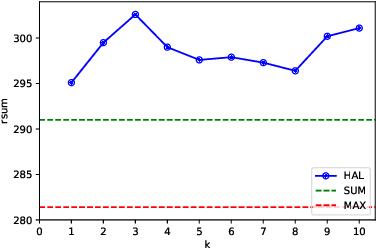
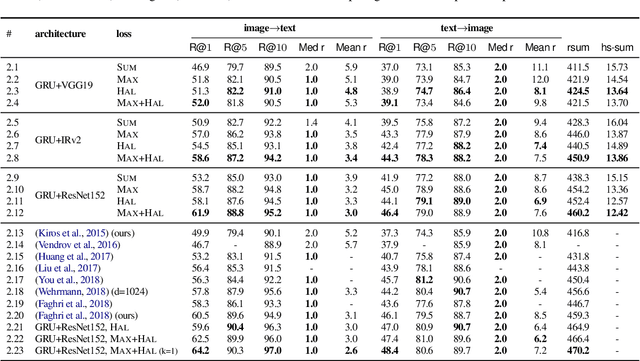
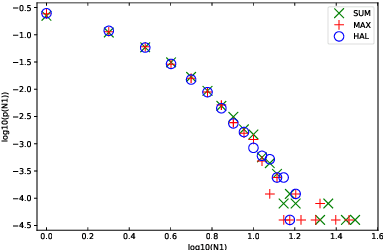
The hubness problem widely exists in high-dimensional embedding space and is a fundamental source of error for cross-modal matching tasks. In this work, we study the emergence of hubs in Visual Semantic Embeddings (VSE) with application to text-image matching. We analyze the pros and cons of two widely adopted optimization objectives for training VSE and propose a novel hubness-aware loss function (HAL) that addresses previous methods' defects. Unlike (Faghri et al.2018) which simply takes the hardest sample within a mini-batch, HAL takes all samples into account, using both local and global statistics to scale up the weights of "hubs". We experiment our method with various configurations of model architectures and datasets. The method exhibits exceptionally good robustness and brings consistent improvement on the task of text-image matching across all settings. Specifically, under the same model architectures as (Faghri et al. 2018) and (Lee at al. 2018), by switching only the learning objective, we report a maximum R@1improvement of 7.4% on MS-COCO and 8.3% on Flickr30k.