 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Apr 15, 2026We introduce HY-World 2.0, a multi-modal world model framework that advances our prior project HY-World 1.0. HY-World 2.0 accommodates diverse input modalities, including text prompts, single-view images, multi-view images, and videos, and produces 3D world representations. With text or single-view image inputs, the model performs world generation, synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes. This is achieved through a four-stage method: a) Panorama Generation with HY-Pano 2.0, b) Trajectory Planning with WorldNav, c) World Expansion with WorldStereo 2.0, and d) World Composition with WorldMirror 2.0. Specifically, we introduce key innovations to enhance panorama fidelity, enable 3D scene understanding and planning, and upgrade WorldStereo, our keyframe-based view generation model with consistent memory. We also upgrade WorldMirror, a feed-forward model for universal 3D prediction, by refining model architecture and learning strategy, enabling world reconstruction from multi-view images or videos. Also, we introduce WorldLens, a high-performance 3DGS rendering platform featuring a flexible engine-agnostic architecture, automatic IBL lighting, efficient collision detection, and training-rendering co-design, enabling interactive exploration of 3D worlds with character support. Extensive experiments demonstrate that HY-World 2.0 achieves state-of-the-art performance on several benchmarks among open-source approaches, delivering results comparable to the closed-source model Marble. We release all model weights, code, and technical details to facilitate reproducibility and support further research on 3D world models.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
BeamVQ: Aligning Space-Time Forecasting Model via Self-training on Physics-aware Metrics
May 27, 2024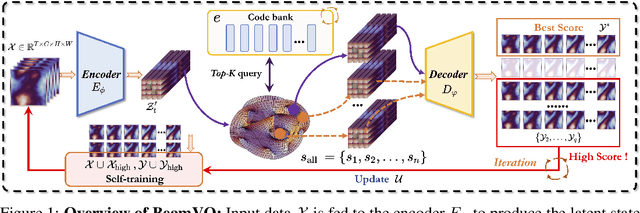
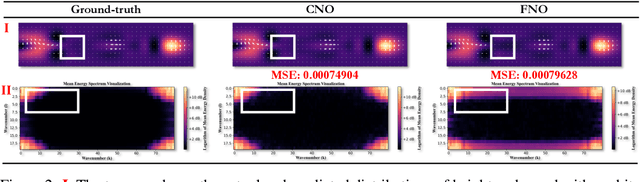
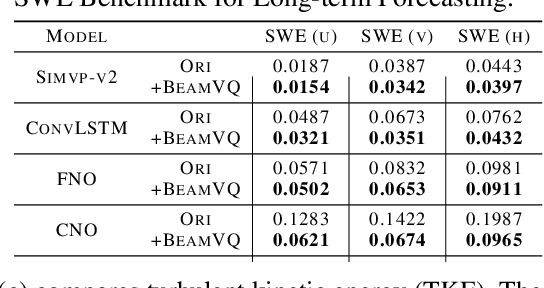
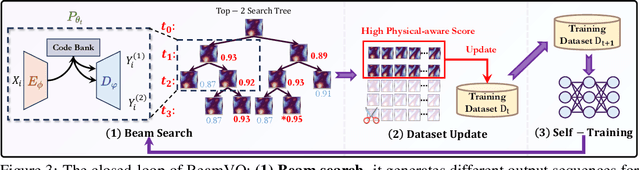
Data-driven deep learning has emerged as the new paradigm to model complex physical space-time systems. These data-driven methods learn patterns by optimizing statistical metrics and tend to overlook the adherence to physical laws, unlike traditional model-driven numerical methods. Thus, they often generate predictions that are not physically realistic. On the other hand, by sampling a large amount of high quality predictions from a data-driven model, some predictions will be more physically plausible than the others and closer to what will happen in the future. Based on this observation, we propose \emph{Beam search by Vector Quantization} (BeamVQ) to enhance the physical alignment of data-driven space-time forecasting models. The key of BeamVQ is to train model on self-generated samples filtered with physics-aware metrics. To be flexibly support different backbone architectures, BeamVQ leverages a code bank to transform any encoder-decoder model to the continuous state space into discrete codes. Afterwards, it iteratively employs beam search to sample high-quality sequences, retains those with the highest physics-aware scores, and trains model on the new dataset. Comprehensive experiments show that BeamVQ not only gave an average statistical skill score boost for more than 32% for ten backbones on five datasets, but also significantly enhances physics-aware metrics.
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
May 23, 2024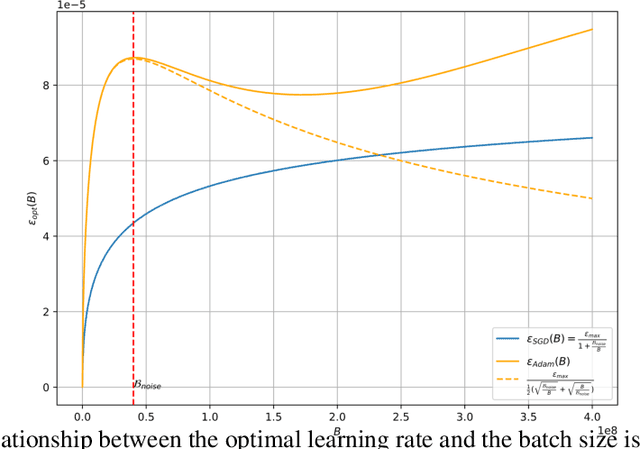
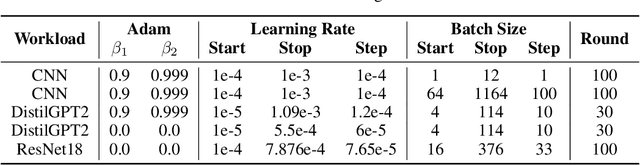
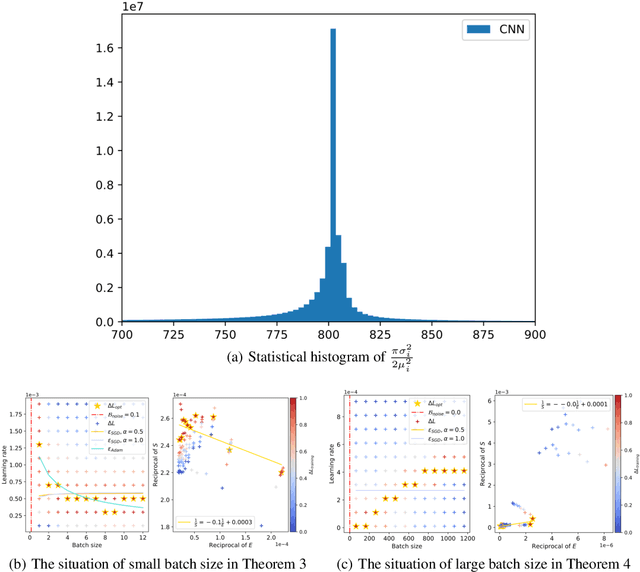
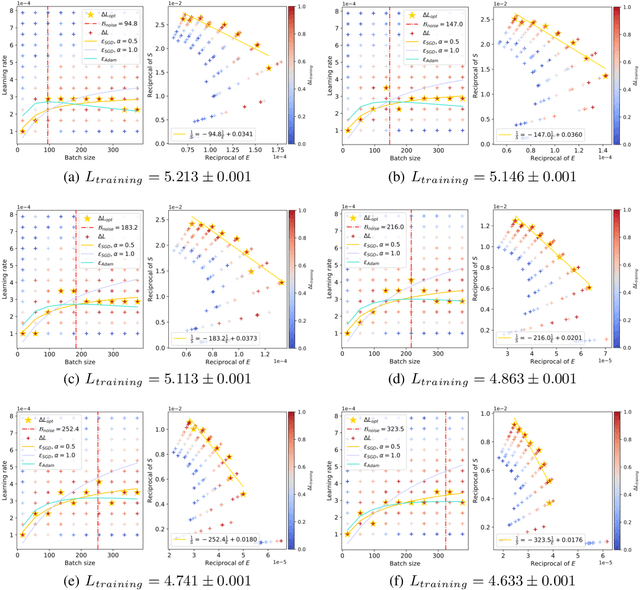
In current deep learning tasks, Adam style optimizers such as Adam, Adagrad, RMSProp, Adafactor, and Lion have been widely used as alternatives to SGD style optimizers. These optimizers typically update model parameters using the sign of gradients, resulting in more stable convergence curves. The learning rate and the batch size are the most critical hyperparameters for optimizers, which require careful tuning to enable effective convergence. Previous research has shown that the optimal learning rate increases linearly or follows similar rules with batch size for SGD style optimizers. However, this conclusion is not applicable to Adam style optimizers. In this paper, we elucidate the connection between optimal learning rates and batch sizes for Adam style optimizers through both theoretical analysis and extensive experiments. First, we raise the scaling law between batch sizes and optimal learning rates in the sign of gradient case, in which we prove that the optimal learning rate first rises and then falls as the batch size increases. Moreover, the peak value of the surge will gradually move toward the larger batch size as training progresses. Second, we conducted experiments on various CV and NLP tasks and verified the correctness of the scaling law.
Retrieval-Augmented Generation for AI-Generated Content: A Survey
Feb 29, 2024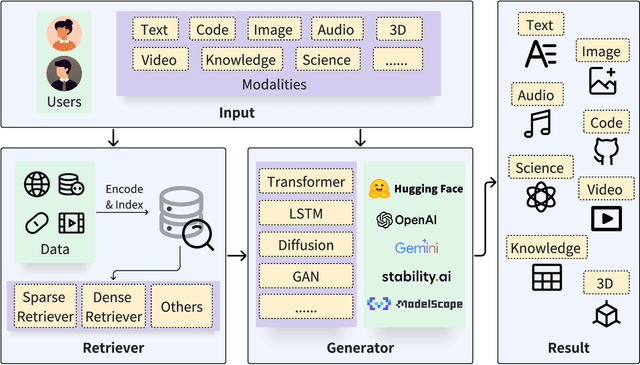
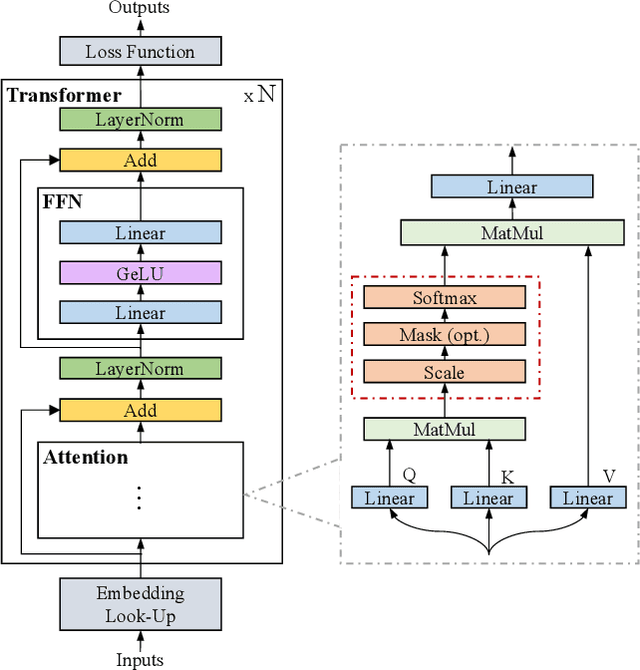
The development of Artificial Intelligence Generated Content (AIGC) has been facilitated by advancements in model algorithms, scalable foundation model architectures, and the availability of ample high-quality datasets. While AIGC has achieved remarkable performance, it still faces challenges, such as the difficulty of maintaining up-to-date and long-tail knowledge, the risk of data leakage, and the high costs associated with training and inference. Retrieval-Augmented Generation (RAG) has recently emerged as a paradigm to address such challenges. In particular, RAG introduces the information retrieval process, which enhances AIGC results by retrieving relevant objects from available data stores, leading to greater accuracy and robustness. In this paper, we comprehensively review existing efforts that integrate RAG technique into AIGC scenarios. We first classify RAG foundations according to how the retriever augments the generator. We distill the fundamental abstractions of the augmentation methodologies for various retrievers and generators. This unified perspective encompasses all RAG scenarios, illuminating advancements and pivotal technologies that help with potential future progress. We also summarize additional enhancements methods for RAG, facilitating effective engineering and implementation of RAG systems. Then from another view, we survey on practical applications of RAG across different modalities and tasks, offering valuable references for researchers and practitioners. Furthermore, we introduce the benchmarks for RAG, discuss the limitations of current RAG systems, and suggest potential directions for future research. Project: https://github.com/hymie122/RAG-Survey
Experimental Analysis of Large-scale Learnable Vector Storage Compression
Nov 27, 2023
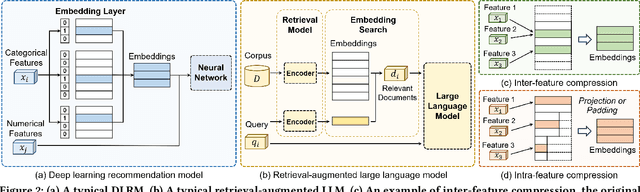
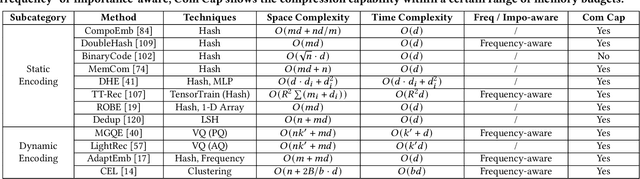
Learnable embedding vector is one of the most important applications in machine learning, and is widely used in various database-related domains. However, the high dimensionality of sparse data in recommendation tasks and the huge volume of corpus in retrieval-related tasks lead to a large memory consumption of the embedding table, which poses a great challenge to the training and deployment of models. Recent research has proposed various methods to compress the embeddings at the cost of a slight decrease in model quality or the introduction of other overheads. Nevertheless, the relative performance of these methods remains unclear. Existing experimental comparisons only cover a subset of these methods and focus on limited metrics. In this paper, we perform a comprehensive comparative analysis and experimental evaluation of embedding compression. We introduce a new taxonomy that categorizes these techniques based on their characteristics and methodologies, and further develop a modular benchmarking framework that integrates 14 representative methods. Under a uniform test environment, our benchmark fairly evaluates each approach, presents their strengths and weaknesses under different memory budgets, and recommends the best method based on the use case. In addition to providing useful guidelines, our study also uncovers the limitations of current methods and suggests potential directions for future research.
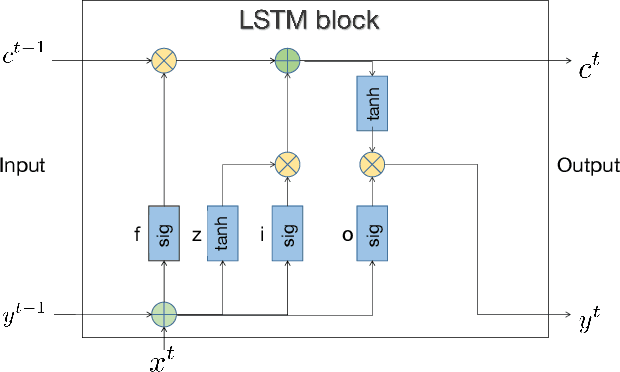
Learning from Training Dynamics: Identifying Mislabeled Data Beyond Manually Designed Features
Dec 20, 2022
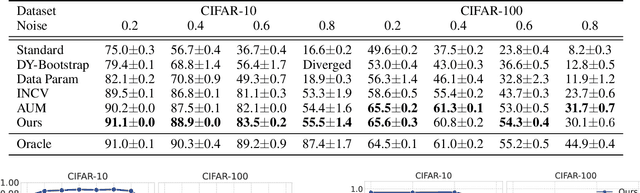
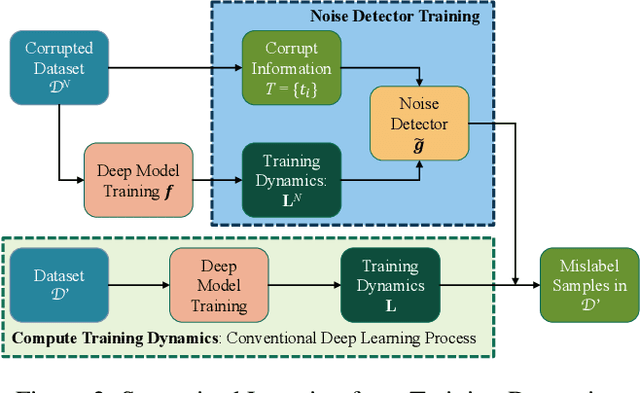

While mislabeled or ambiguously-labeled samples in the training set could negatively affect the performance of deep models, diagnosing the dataset and identifying mislabeled samples helps to improve the generalization power. Training dynamics, i.e., the traces left by iterations of optimization algorithms, have recently been proved to be effective to localize mislabeled samples with hand-crafted features. In this paper, beyond manually designed features, we introduce a novel learning-based solution, leveraging a noise detector, instanced by an LSTM network, which learns to predict whether a sample was mislabeled using the raw training dynamics as input. Specifically, the proposed method trains the noise detector in a supervised manner using the dataset with synthesized label noises and can adapt to various datasets (either naturally or synthesized label-noised) without retraining. We conduct extensive experiments to evaluate the proposed method. We train the noise detector based on the synthesized label-noised CIFAR dataset and test such noise detector on Tiny ImageNet, CUB-200, Caltech-256, WebVision and Clothing1M. Results show that the proposed method precisely detects mislabeled samples on various datasets without further adaptation, and outperforms state-of-the-art methods. Besides, more experiments demonstrate that the mislabel identification can guide a label correction, namely data debugging, providing orthogonal improvements of algorithm-centric state-of-the-art techniques from the data aspect.