 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARTS: Distribution-Aware Active Rollout Trajectory Shaping for Accelerating LLM Reinforcement Learning
May 29, 2026Reinforcement Learning (RL) has become pivotal for improving model capabilities yet suffers from rollout efficiency bottlenecks due to the long-tail response length distribution. While existing works mitigate the impact of long tails via prompt-level tail scheduling, we focus on the root source of inefficiency: the distribution itself. Specifically, we characterize the long-tail distribution at a finer granularity, identifying intra-prompt long tails, and revealing that they frequently consist of ineffective verbosity. To address this, we propose a novel paradigm of active distribution shaping to shape the rollout distribution towards conciseness and certainty, thereby fundamentally resolving tail-induced overheads. We achieve this through a distribution-aware trajectory sampling mechanism, which selects trajectories from a redundant exploration space for each prompt, and an adaptive redundancy allocation scheme to maximize both shaping effectiveness and system efficiency. Experiments demonstrate significant acceleration over state-of-the-art systems by up to 1.77x without compromising model performance.
LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
May 21, 2026Joint audio-visual reasoning is essential for omnimodal understanding, yet current multimodal large language models (MLLMs) still struggle when reasoning requires fine-grained evidence from both modalities. A central limitation is that explicit text-based chain-of-thought (CoT) compresses continuous audio-visual signals into discrete tokens, weakening temporal grounding and shifting intermediate reasoning toward language priors. We argue that a unified latent space is a better medium for such reasoning because it preserves dense sensory information while remaining compatible with autoregressive generation. Based on this insight, we propose \textbf{LatentOmni}, a cross-modal reasoning framework that interleaves textual reasoning with audio-visual latent states. LatentOmni introduces feature-level supervision to align latent reasoning states with task-relevant sensory features and uses Omni-Sync Position Embedding (OSPE) to maintain temporal consistency between latent audio and visual states. We further construct \textbf{LatentOmni-Instruct-35K}, a dataset of audio-visual interleaved reasoning trajectories for supervising latent-space reasoning. Comprehensive evaluation across multiple audio-visual reasoning benchmarks demonstrates that LatentOmni achieves the best performance among the evaluated open-source models and consistently outperforms the Explicit Text CoT baseline, supporting latent-space joint reasoning as a promising path toward stronger omnimodal understanding.
Efficient Serving for Dynamic Agent Workflows with Prediction-based KV-Cache Management
May 07, 2026LLM-based workflows compose specialized agents to execute complex tasks, and these agents usually share substantial context, allowing KV-Cache reuse to save computation. Existing approaches either manage KV-Cache at agent level and fail to exploit the reuse opportunities within workflows, or manage cache at the workflow level but assume that each workflow calls a static sequence of agents. However, practical workflows are typically dynamic, where the sequence of invoked agents and thus induced cache reuse opportunities depend on the context of each task. To serve such dynamic workflows efficiently, we build a system dubbed PBKV (\textbf{P}rediction-\textbf{B}ased \textbf{KV}-Cache Management). For each workflow, PBKV predicts the agent invocations in several future steps by fusing the guidance from historical workflows and context of the target workflow. Based on the predictions, PBKV estimates the reuse potential of cache entries and keeps the high-potential entries in GPU memory. To be robust to prediction errors, PBKV utilizes the predictions conservatively during both cache eviction and prefetching. Experiments on three workflow benchmarks show that PBKV achieves up to $1.85\times$ speedup over LRU on dynamic workflows, and up to $1.26\times$ speedup over the SOTA baseline KVFlow on the static workflow.
Scheduling LLM Inference with Uncertainty-Aware Output Length Predictions
Apr 01, 2026To schedule LLM inference, the \textit{shortest job first} (SJF) principle is favorable by prioritizing requests with short output lengths to avoid head-of-line (HOL) blocking. Existing methods usually predict a single output length for each request to facilitate scheduling. We argue that such a \textit{point estimate} does not match the \textit{stochastic} decoding process of LLM inference, where output length is \textit{uncertain} by nature and determined by when the end-of-sequence (EOS) token is sampled. Hence, the output length of each request should be fitted with a distribution rather than a single value. With an in-depth analysis of empirical data and the stochastic decoding process, we observe that output length follows a heavy-tailed distribution and can be fitted with the log-t distribution. On this basis, we propose a simple metric called Tail Inflated Expectation (TIE) to replace the output length in SJF scheduling, which adjusts the expectation of a log-t distribution with its tail probabilities to account for the risk that a request generates long outputs. To evaluate our TIE scheduler, we compare it with three strong baselines, and the results show that TIE reduces the per-token latency by $2.31\times$ for online inference and improves throughput by $1.42\times$ for offline data generation.
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
Mar 27, 2026Data-centric training has emerged as a promising direction for improving large language models (LLMs) by optimizing not only model parameters but also the selection, composition, and weighting of training data during optimization. However, existing approaches to data selection, data mixture optimization, and data reweighting are often developed in isolated codebases with inconsistent interfaces, hindering reproducibility, fair comparison, and practical integration. In this paper, we present DataFlex, a unified data-centric dynamic training framework built upon LLaMA-Factory. DataFlex supports three major paradigms of dynamic data optimization: sample selection, domain mixture adjustment, and sample reweighting, while remaining fully compatible with the original training workflow. It provides extensible trainer abstractions and modular components, enabling a drop-in replacement for standard LLM training, and unifies key model-dependent operations such as embedding extraction, inference, and gradient computation, with support for large-scale settings including DeepSpeed ZeRO-3. We conduct comprehensive experiments across multiple data-centric methods. Dynamic data selection consistently outperforms static full-data training on MMLU across both Mistral-7B and Llama-3.2-3B. For data mixture, DoReMi and ODM improve both MMLU accuracy and corpus-level perplexity over default proportions when pretraining Qwen2.5-1.5B on SlimPajama at 6B and 30B token scales. DataFlex also achieves consistent runtime improvements over original implementations. These results demonstrate that DataFlex provides an effective, efficient, and reproducible infrastructure for data-centric dynamic training of LLMs.
LAER-MoE: Load-Adaptive Expert Re-layout for Efficient Mixture-of-Experts Training
Feb 12, 2026Expert parallelism is vital for effectively training Mixture-of-Experts (MoE) models, enabling different devices to host distinct experts, with each device processing different input data. However, during expert parallel training, dynamic routing results in significant load imbalance among experts: a handful of overloaded experts hinder overall iteration, emerging as a training bottleneck. In this paper, we introduce LAER-MoE, an efficient MoE training framework. The core of LAER-MoE is a novel parallel paradigm, Fully Sharded Expert Parallel (FSEP), which fully partitions each expert parameter by the number of devices and restores partial experts at expert granularity through All-to-All communication during training. This allows for flexible re-layout of expert parameters during training to enhance load balancing. In particular, we perform fine-grained scheduling of communication operations to minimize communication overhead. Additionally, we develop a load balancing planner to formulate re-layout strategies of experts and routing schemes for tokens during training. We perform experiments on an A100 cluster, and the results indicate that our system achieves up to 1.69x acceleration compared to the current state-of-the-art training systems. Source code available at https://github.com/PKU-DAIR/Hetu-Galvatron/tree/laer-moe.
SALE : Low-bit Estimation for Efficient Sparse Attention in Long-context LLM Prefilling
May 30, 2025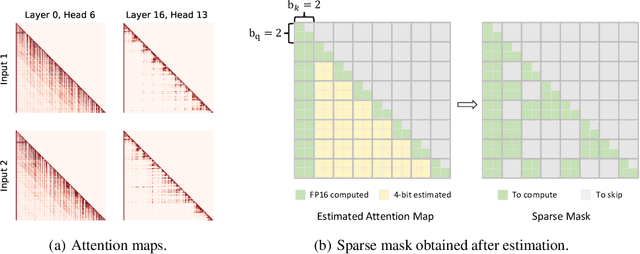
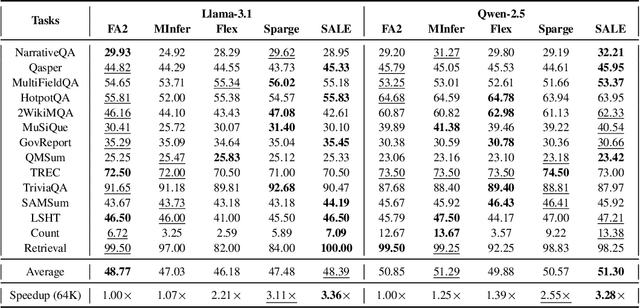
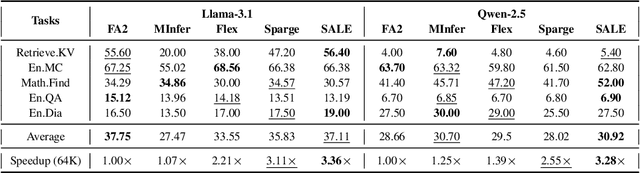
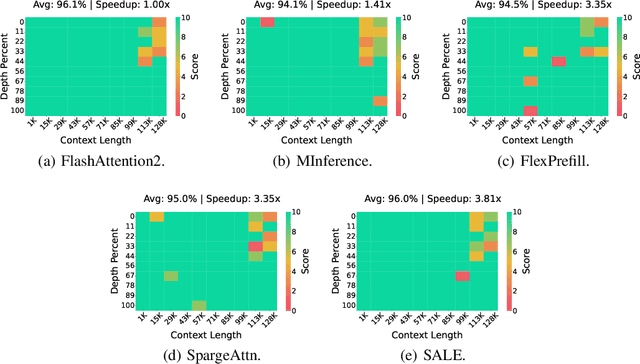
Many advanced Large Language Model (LLM) applications require long-context processing, but the self-attention module becomes a bottleneck during the prefilling stage of inference due to its quadratic time complexity with respect to sequence length. Existing sparse attention methods accelerate attention computation by skipping less significant regions of the attention map. However, these approaches typically perform coarse-grained inspection of the attention map, rendering considerable loss in model accuracy. In this paper, we propose SALE, a fine-grained sparse attention method that accelerates the long-context prefilling stage of LLM with negligible loss in model accuracy. SALE achieves fast and accurate fine-grained attention weight estimation through 4-bit quantized query-key products, followed by block-sparse attention to accelerate prefilling computations. For importance evaluation for query-key pairs, we adopt our Relative Attention Score metric, which offers significantly higher efficiency within our framework. We implement a custom CUDA kernel optimized for our approach for hardware efficiency, reducing the additional overhead to approximately 11% of the full attention latency. Notably, SALE requires no parameter training and can be seamlessly integrated into existing systems with trivial code modifications. Experiments on long-context benchmarks demonstrate that our method outperforms existing approaches in accuracy-efficiency trade-offs, achieving at least 3.36x speedups on Llama-3.1-8B for sequences longer than 64K while maintaining model quality.
Thinking Short and Right Over Thinking Long: Serving LLM Reasoning Efficiently and Accurately
May 19, 2025Recent advances in test-time scaling suggest that Large Language Models (LLMs) can gain better capabilities by generating Chain-of-Thought reasoning (analogous to human thinking) to respond a given request, and meanwhile exploring more reasoning branches (i.e., generating multiple responses and ensembling them) can improve the final output quality. However, when incorporating the two scaling dimensions, we find that the system efficiency is dampened significantly for two reasons. Firstly, the time cost to generate the final output increases substantially as many reasoning branches would be trapped in the over-thinking dilemma, producing excessively long responses. Secondly, generating multiple reasoning branches for each request increases memory consumption, which is unsuitable for LLM serving since we can only batch a limited number of requests to process simultaneously. To address this, we present SART, a serving framework for efficient and accurate LLM reasoning. The essential idea is to manage the thinking to be short and right, rather than long. For one thing, we devise a redundant sampling with early stopping approach based on empirical observations and theoretic analysis, which increases the likelihood of obtaining short-thinking responses when sampling reasoning branches. For another, we propose to dynamically prune low-quality branches so that only right-thinking branches are maintained, reducing the memory consumption and allowing us to batch more requests. Experimental results demonstrate that SART not only improves the accuracy of LLM reasoning but also enhances the serving efficiency, outperforming existing methods by up to 28.2 times and on average 15.7 times in terms of efficiency when achieving the same level of accuracy.
Galvatron: An Automatic Distributed System for Efficient Foundation Model Training
Apr 30, 2025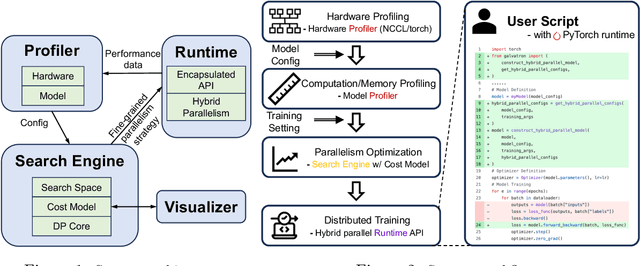
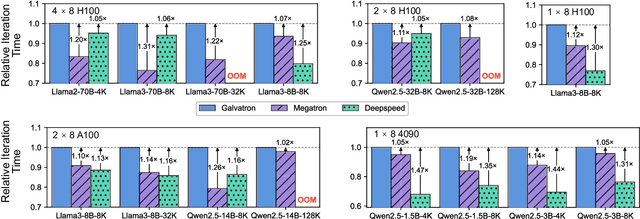
Galvatron is a distributed system for efficiently training large-scale Foundation Models. It overcomes the complexities of selecting optimal parallelism strategies by automatically identifying the most efficient hybrid strategy, incorporating data, tensor, pipeline, sharded data, and sequence parallelism, along with recomputation. The system's architecture includes a profiler for hardware and model analysis, a search engine for strategy optimization using decision trees and dynamic programming, and a runtime for executing these strategies efficiently. Benchmarking on various clusters demonstrates Galvatron's superior throughput compared to existing frameworks. This open-source system offers user-friendly interfaces and comprehensive documentation, making complex distributed training accessible and efficient. The source code of Galvatron is available at https://github.com/PKU-DAIR/Hetu-Galvatron.
Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
Feb 28, 2025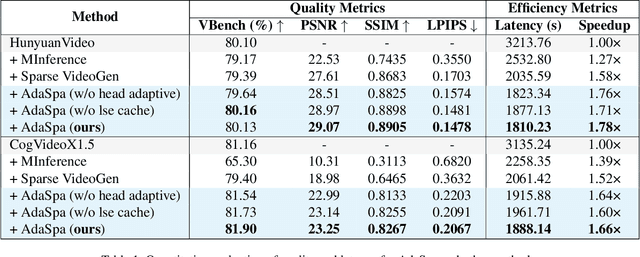
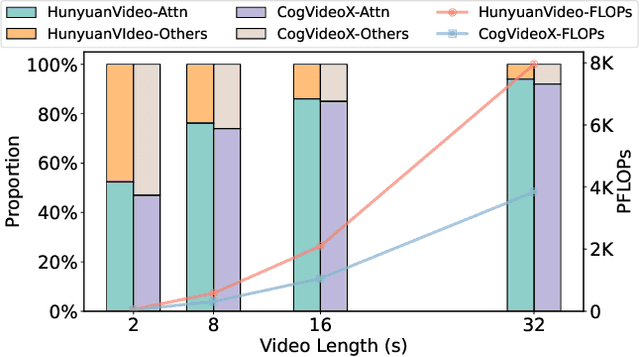
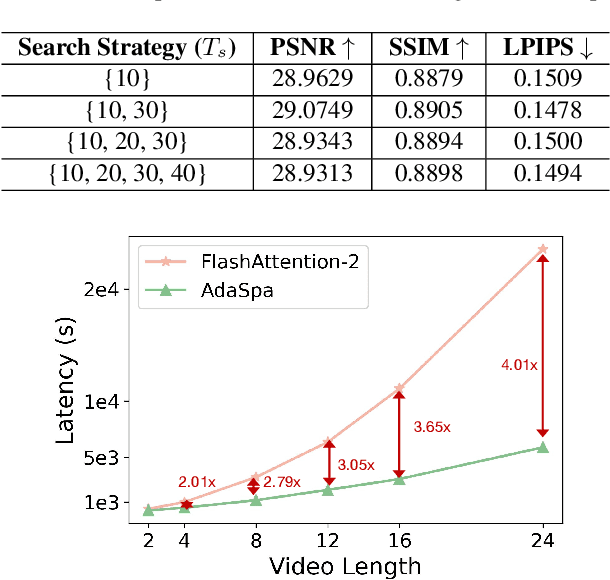
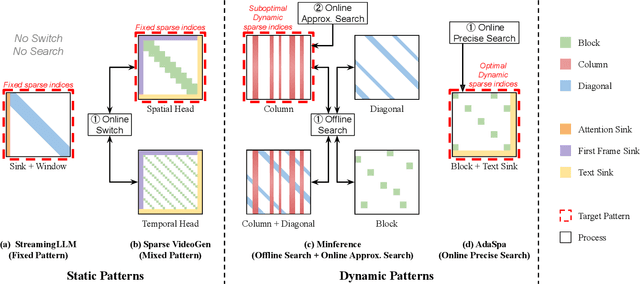
Generating high-fidelity long videos with Diffusion Transformers (DiTs) is often hindered by significant latency, primarily due to the computational demands of attention mechanisms. For instance, generating an 8-second 720p video (110K tokens) with HunyuanVideo takes about 600 PFLOPs, with around 500 PFLOPs consumed by attention computations. To address this issue, we propose AdaSpa, the first Dynamic Pattern and Online Precise Search sparse attention method. Firstly, to realize the Dynamic Pattern, we introduce a blockified pattern to efficiently capture the hierarchical sparsity inherent in DiTs. This is based on our observation that sparse characteristics of DiTs exhibit hierarchical and blockified structures between and within different modalities. This blockified approach significantly reduces the complexity of attention computation while maintaining high fidelity in the generated videos. Secondly, to enable Online Precise Search, we propose the Fused LSE-Cached Search with Head-adaptive Hierarchical Block Sparse Attention. This method is motivated by our finding that DiTs' sparse pattern and LSE vary w.r.t. inputs, layers, and heads, but remain invariant across denoising steps. By leveraging this invariance across denoising steps, it adapts to the dynamic nature of DiTs and allows for precise, real-time identification of sparse indices with minimal overhead. AdaSpa is implemented as an adaptive, plug-and-play solution and can be integrated seamlessly with existing DiTs, requiring neither additional fine-tuning nor a dataset-dependent profiling. Extensive experiments validate that AdaSpa delivers substantial acceleration across various models while preserving video quality, establishing itself as a robust and scalable approach to efficient video generation.